就我个人经验来看,数据爬虫是很费时间的技术,特别对于中小公司和个人,我曾经想研究下某音用户短视频的评论情感倾向,需要大概100万条级以上的数据,光是写代码有上千行,虽然是公开数据,但会面临各种反爬手段,最后脚本磨了两三天才能正常稳定的运行。
爬虫为什么难?爬虫是网络数据采集的简称,顾名思义就是利用http请求技术向网站发送数据请求,然后进行html解析并提取到需要的数据,可以使用Python等工具实现,这个过程看似简单,但暗藏很多机关,也导致很多人只是入了爬虫的门,但无法真正开发爬虫项目。
这主要是因为网络上到处是反爬虫机制,爬虫会面对IP限制、验证码、数据加密、动态页面处理等各种问题,需要IP代理、OCR、数据解密、selenium动态加载等技术来解决。所以写爬虫要一路打怪升级,才能稳定地获取到高质量数据。

添加图片注释,不超过 140 字(可选)
最近用到一个非常简单的高级爬虫工具,亮数据的Scraper APIs,你可以理解成一种爬虫接口,它帮你绕开了IP限制、验证码、加密等问题,无需编写任何的反爬机制处理、动态网页处理代码,后续也无需任何维护,就可以“一键”获取Tiktok、Amazon、Linkedin、Github、Instagram等全球各大主流网站数据。
这能极大地节省数据采集时间,对于爬虫技术不那么过硬的小伙伴来说是不可多得的捷径。

比如可以轻松采集大批量Tiktok商品数据,还不受网络限制。
 如何使用Scraper APIs?
如何使用Scraper APIs?Scraper APIs是亮数据专门为批量采集数据而开发的接口,支持上百个网站,200多个专门API采集器,例如Linkedin的职位、公司、人员数据采集器,Tiktok的商品、短视频数据采集器,当然这些数据都是公开可抓取的,不会涉及任何隐私安全问题。
想要使用Scraper APIs,主要有以下三个步骤,非常简单。
1、注册和登陆亮数据亮数据是专门做数据采集服务的网站,各大Top互联网公司的数据服务商。
首先从下面网址注册并登陆亮数据。
登陆后就进入到亮数据的管理后台,点击Web Scrapers栏目进入网页采集看板。

然后点击Scrapers marketplace进入数据采集集市,在这里你能看到各种网站的API数据采集器,后面就以Tiktok为例讲下采集器的使用。
 2、配置和使用API来抓取数据
2、配置和使用API来抓取数据进入Tiktok API界面,会有各种各样数据类别采集器,包括电商商品、短视频、评论等。
我们这里选择电商商品采集器,是通过网址url来采集的。

接着进入到API配置的界面。

在Dictionary中我们知道这个API会采集电商商品名称、网址、价格等多达20几个字段,看看是不是你想要的数据。
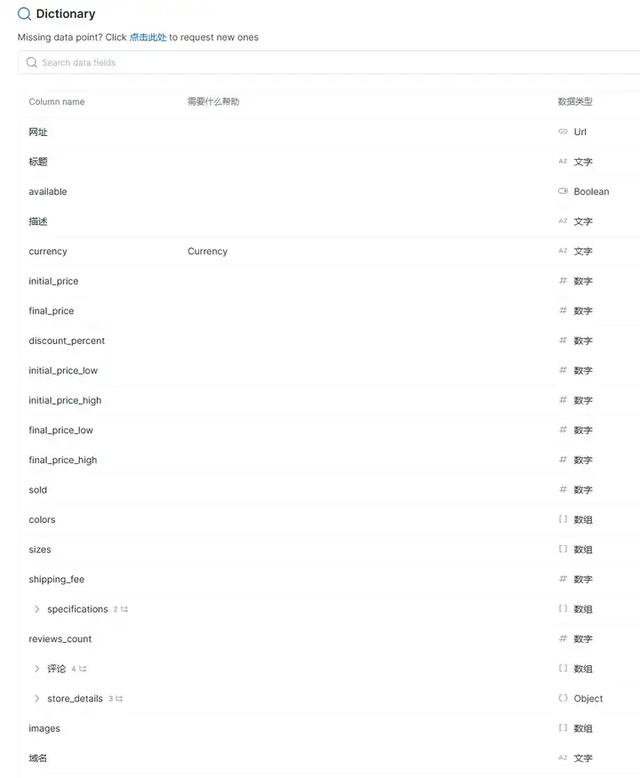
「第一步:配置要采集的url网址和输出数据的格式」
这里需要你把想要采集的url网址(必须Tiktok商品)填进去,一次性最多5千个,然后选择输出形式,Json或者CSV都行。


「第二步:设置数据存储形式」
亮数据支持数据临时存储(也就是snapshot),还可以存储到亚马逊、谷歌、微软、阿里的云端服务上。
这里的snapshot id先不用管,你发送数据请求后爬下来的数据就会临时存储到亮数据平台上,然后会生成一个snapshot id(用于下载数据),接着你可以通过snapshot id再提取你想要的数据,snapshot id是唯一的,不用担心数据丢失。

「第三步:开始抓取数据」
配置就是这么简单,下面直接复制配置好的命令行代码,放到本地电脑命令行执行。

执行好后,返回{"snapshot_id":"s_m6tm1ezn28xivtvzlt"}的提示,说明数据已经抓取成功,并临时存起来了。

这时候没看到爬取的数据,不要着急,把刚刚返回的snapshot_id填进去,复制用于下载数据的命令行代码,放到命令行执行。

很快,你就能看到抓取的Tiktok商品数据,在命令行呈现了出来。

这就是使用Scraper API采集复杂数据集的流程,没有写任何代码,直接获取到数据。
看似很简单,那这个中间Scraper API帮我们做了什么呢?有以下三件大事。
1、在云上向Tiktok发出http数据请求 2、模拟登陆、配置IP代理、动态访问、识别验证码、破解加密数据等 3、解析获取的HTML,提取重要的字段,输出为json格式
这里面有着极其复杂的操作,如果你要自己写代码抓取,会面临非常多棘手的问题,而且网站都是经常变动的,代码维护成本很高。
3、使用Python来实现大批量灵活抓取Scraper API提供了python的访问方式,通过request库来获取数据,也是非常的简单。
通过Python来实现有2个好处。
1、支持大批量的自动提交url网址,不像刚刚那样的手动复制进去 2、支持对抓取的数据进行处理、清洗、存储操作,配合Pandas、Numpy库,非常方便
下面是Python来抓取数据的代码,也是两步,先提交请求获取snapshot_id,然后再配置snapshot_id下载数据。
import requests# 提交数据采集请求,获取snapshot_idurl = "https://api.brightdata.com/datasets/v3/trigger"querystring = {"dataset_id":"gd_m45m1u911dsa4274pi"}payload = [{"url": "https://shop-sg.tiktok.com/view/product/1730242941495248835"},{"url": "https://www.tiktok.com/view/product/1729762527861968902"}]headers = { "Authorization": "Bearer 5ef0c1963cd15598df06011c34c7dffa89daf64bea9004776319d1448fa29109", "Content-Type": "application/json"}response = requests.request("POST", url, json=payload, headers=headers, params=querystring)snapshot_id = response.json()['snapshot_id']# 配置snapshot_id,下载数据url = "https://api.brightdata.com/datasets/v3/snapshot/{0}".format(snapshot_id)headers = {"Authorization": "Bearer 5ef0c1963cd15598df06011c34c7dffa89daf64bea9004776319d1448fa29109"}response = requests.request("GET", url, headers=headers)# 打印数据print(response.text)打印出商品信息如下:

如果你想输出为dataframe格式,更加直观且方便处理,也可以增加几行代码。
import jsonimport pandas as pddata_list = []for line in response.text.strip().split('\n'): try: data = json.loads(line) data_list.append(data) except json.JSONDecodeError: print(f"无法解析行: {line}")df = pd.DataFrame(data_list)df
用python来访问Scraper API获取数据,比命令行更加灵活且强大些,可以自己选择合适的使用。
结论网络爬虫向来是一件费时费力的事,如果你没有足够的代码能力或者不想浪费时间,完全可以使用亮数据的Scraper API来抓取数据,能支持URL或者关键词爬取相关HTML页面,而且能无限制的进行请求,完全自动化不用操心。
想用的话可以在下面网址查看登陆:
