
11月6日,联发科新旗舰天玑9300正式发布。
这是Arm大小核结构出现以来,第一颗全大核CPU的移动SoC,第一颗晶体管数目达到227亿的手机SoC,这也是联发科第一次CPU、GPU、AI全方位抛离同代竞品。说的就是你们,骁龙8 Gen 3和A17 Pro。
首发天玑9300的vivo X100系列要11月13日才发布,但简单体验和测试天玑9300工程机就能发现,它还真的是下一代移动SoC性能之王。


天玑9300——新的发哥之⭐
台积电第三代4nm制程(天玑9000的N4是第一代,天玑9200的N4P是第二代)
晶体管数目从天玑9200的170亿,飙到227亿
CPU是1颗3.25GHz的X4+ 3颗2.85GHz的X4 + 4颗2.0GHz的A720
首发LPDDR5T 9600Mbps内存支持
GPU首发Immortalis-G720 MC12(GeekBench显示频率为1.3GHz)
第二代光线追踪引擎,宣称光追性能提升46%,支持全局光照,可以60帧运行光追游戏
第七代AI处理器APU 790,由性能核和通用核组成,整数和浮点性能提升翻倍,功耗降低45%
带硬件内存压缩,首个能运行330亿参数AI大语音模型的移动SoC
作为参考:
天玑9200是3.05GHz的X3 + 3x2.85GHz的A715 + 4x1.8GHz的A510 refreshed,Immortalis-G715 MC11 981MHz
天玑9200+是3.35GHz的X3 + 3x3GHz的A715 + 4x2GHz的A510 refreshed,Immortalis-G715 MC11 1.148GHz。
骁龙8 Gen 3是1颗3.3GHz的X4 + 3颗3.15GHz的A720 + 2颗2.96GHz的A720 + 2颗2.27GHz的A520(X4缓存2MB,A720和A520都是512KB,系统缓存6MB,L3缓存从8MB涨到12MB),GPU是Adreno 750 903MHz(默频770MHz),核心规模增加20%,多1组CU,1792ALUs
官宣提升:
CPU峰值性能提升40%,同性能下功耗降低33%,应用启动速度提升16%
GPU峰值性能提升46%,同性能下功耗降低40%
日常功耗有10%到13%不等的下降幅度(网页浏览降10%、短视频降11、视频录制降12、视频播放降13%),Wi-Fi热点功耗降低30%。极高画质原神+微信通话,宣称帧率提升15.5%,功耗下降12.3%,直播+新闻的功耗降低11.2%。
最高支持4K 120Hz或2K 180Hz屏幕,有AI景深画质引擎,日常显示功耗降低10%
最高支持6.5Gbps的Wi-Fi 7,Xtra Range 2.0技术可增加4.5米信号覆盖
支持安卓首个3天线双路蓝牙(连接速度提升42%,最低35ms时延)
5G基带支持Sub-6GHz的四载波聚合和情景感知功能,宣称5G卡顿降低20%,荒野待机增加4小时
双安全芯片,分别负责开机保护和敏感数据物理隔离,带内存标记拓展(MTE)

简要分析:
天玑9300的227亿晶体管,是真正的遥遥领先:苹果A16是160亿,A17 Pro是190亿,苹果M2是200亿。即便是刚发布的苹果M3,也“仅”有250亿晶体管,而高通好几代没公布晶体管数目了。
历史性的取消小核,CPU由4颗X4超大核和4颗A720大核组成,最高频的X4有更大的缓存。跳出安卓SoC的视角看,天玑9300的4颗超大核和4颗大核,其实更接近于苹果A系列和英特尔的P核(性能核)、E核(能效核)概念。
首发LPDDR5T 9600Mbps内存,速度比之前的LPDDR5x 8533Mbps提升12.5%,这是大家以为要等LPDDR6才能达到的频率(2年前的天玑9000是首发LPDDR 5x 7500Mbps内存,天玑9200是首发LPDDR5x 8533Mbps)。
海力士8月宣布在天玑9300上完成LPDDR5T验证,美光在10月26日宣布开始出货9600Mbps LPDDR5x的样品,这也是目前移动端唯一的1β(1-beta)内存,美光1β 工艺节点号称可以省电30%, 宣称是为骁龙8 Gen 3而生,但预计要明年才能量产。
LPDDR5T和这9600Mbps的LPDDR5x带宽一致,暂时未知它们是否有功耗差别。
Immortalis-G720 GPU的核心数目比前代还多一个,GeekBench显示频率高达1.3GHz,比天玑9200+的1.148GHz还夸张。
GPU支持全局光照技术,有2倍的多重抗锯齿性能、2倍的纹理吞吐量和2倍的像素混合运算性能,可变速渲染性能提高86%。引入延迟顶点着色技术(DVS)减少内存访问和带宽使用,以提高性能并降低功耗。
Imagiq 990 ISP,内置的AI语义分隔视频引擎,最高支持16层图像语义分割(骁龙8 Gen 3是12层)。
引入OIS光学防抖专用核,升级了景深和光斑引擎,支持全像素对焦叠加2倍无损变焦,最高支持3麦克风降噪(宣称可将25公里/小时的风噪降低99%)。
与索尼合作的14bit HDR视频录制宣称提升4.8倍动态范围;与三星合作,让2亿像素传感器解析力提升30%;与豪威合作的智能感知,功耗降低53%。



工程机与6.78英寸曲屏的vivo S16 Pro对比

联发科工程机还是熟悉的味道,依然有极为先进的3.5mm耳机口、双SIM卡+TF卡槽。
最大的外观变化来自屏幕,上一年以LCD为主,只有几台曲屏OLED,今年就全是OLED曲屏了。
它和量产机的散热条件,有亿点不同。它只有基础的均热板,电池容量还很小,但为了“方便”更换内存和闪存,据说SoC和内存没有像量产机那样叠放。
其具体配置是6.73英寸1080P+的OLED屏幕,最顶的16GB LPDDR5T 9600Mbps内存,512GB的UFS 4.0闪存,原生Android 14系统。

测试条件:
室温全程保持在22.8到23.8度,屏幕亮度280尼特,机身温度固定到22度再开跑。
强制普通模式,全程不使用性能模式、不使用风扇、散热背夹等工具。
今年终于有严格可控的测试条件,但280尼特亮度这个设定,对刷高分比较不利。高亮度屏幕会抢散热余量,对长时间亮屏的GeekBench 6和安兔兔测试会有比较明显的影响。天玑9300真正的极限性能,估计要等量产机才能看到了。
我们现在就来看看,天玑9300“留一手版”的测试结果。

开波前,还是老话:性能测试/跑分就像考试,跑分高未必体验好,但跑分差的,体验肯定不好。
优秀的测试工具,项目会更贴近用户实际使用,且结果稳定。最接近这个理想目标的,还是老牌的GeekBench和GFXBench。
安兔兔的项目太多,比重不好控制,且官方标准和评分系数变动频繁,经常会跑分“通货膨胀”,故有娱乐兔之称。
所以我们主要以GeekBench 6和GFXBench 5.0的数据为准,以安兔兔为辅。

天玑9300工程机GeekBench 6跑分↑

GeekBench 6和GeekBench 5是两套测试体系,GeekBench 6是多核单负载,会比GeekBench 5更接近日常应用。它以Clang6为主,不会像GeekBench 5那样主要调用本地库,所以无法像以前那样反映系统优化的影响,但正好用来测SoC的理论性能。
CPU单核性能,依然是苹果A系列的天下,安卓阵营今年的单核性能才刚贴近苹果A15,和A17 Pro还有30%左右的差距。
CPU多核这边,天玑9300跑出超越A17 Pro的多核成绩,比骁龙8 Gen 3量产机小米14强8.1%,比骁龙8 Gen 2强29.5%,比天玑9200强47.5%(联发科峰值提升40%的官宣,竟然还保守了)
要知道,我们这台天玑9300测试机是顶着280尼特的屏幕亮度测试的,而我们之前的测试都是以最低屏幕亮度跑的(屏幕功耗会压缩可用的散热余量,导致跑分偏低)。


GFXBench 5.0与BaseMark的In Vitro光追测试↑

GFXBench是老牌GPU测试工具了,对比3DMark,它使用的渲染管线和API更贴近传统手游,适合测试传统的GPU性能。
GPU部分,天玑9300的领先幅度更夸张,直接屠榜。官标说GFX曼哈顿3.0场景提升47%,这同样是反向虚标,几个场景最少比天玑9200强50%,领先最多的场景强62.7%。
骁龙8 Gen 3其实也不弱,这一代GPU也提升25%,但无奈天玑9300太猛,落后8.9%到24.4%之间。和骁龙8 Gen 2比,则是强42%到51.8%之间。
而GPU挤了好几年牙膏的A17 Pro就不用提了,它还没追上骁龙8 Gen 2和天玑9200+,被天玑9300抛离55%到79%,只能坐小孩那桌。


而光线追踪这边,行业的测试工具还没统一(毕竟上年的天玑9200才刚把硬件光追引入移动领域),主流是BaseMark的In Vitro测试和3DMark的Solar Bay测试。
但两个测试的光追占比都不高,Solar Bay的光追占比只有10%到15%,In Vitro测试的光追占比是25-30%,所以后者或许更能试出光追性能(如果光追比例过低,基础性能很强的GPU也能强行拉高总分)。
天玑9300宣称光追性能提升46%。而In Vitro测试中,之前的记录保持者是天玑9200/9200+,它们在3000到3100分左右,天玑9300又是强了50%以上。
而3DMark的Solar Bay测试里,A16是4000分多点,号称4倍光追性能的A17 Pro是6700分左右(此时功耗超过10W),骁龙8 Gen 2领先版是5600分左右,天玑9200+是6500分左右。
虽然现场工作人员不让跑3DMark,但用脚指头预测,天玑9300大概率还是第一。
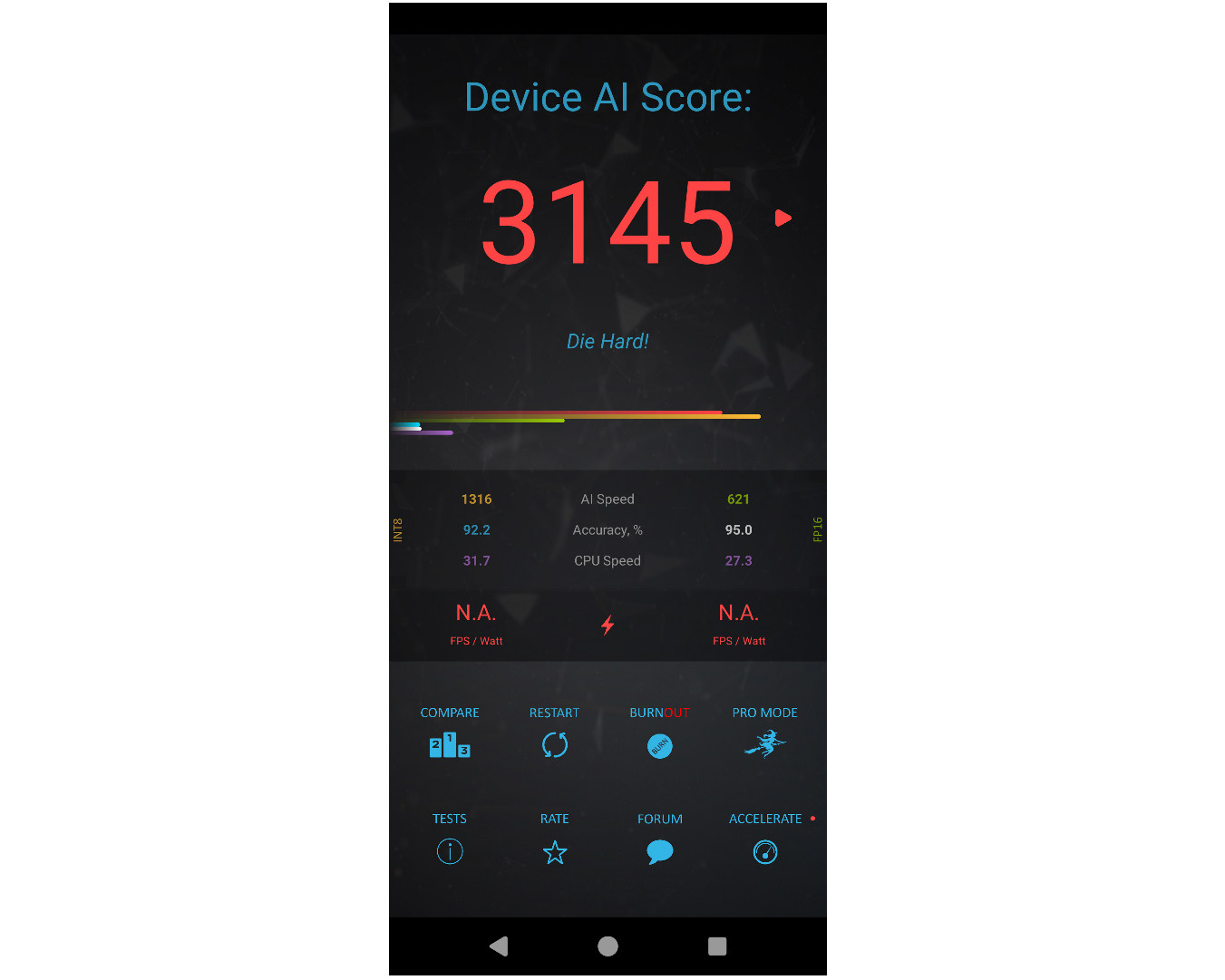
AI测试这边,测试工具的业界分歧就更大了。
和可以借用桌面平台经验的CPU/GPU不同,移动AI就是发展最快的端侧AI,没经验可借。而且还没大规模落地的AI应用,移动AI应该侧重哪方面性能也还没定论,就更遑论统一的测试工具了。
现在主要有ETHZ的AIBenchmark 5.1(即苏黎世测试)、AI Mark V3、AItutu V2、MLPref 3.0这4个测试工具。
当中压力最大的是联发科一直在用的AIBenchmark,其支持22种模型数,比另外几个测试的3-5种,多4倍以上。其最高的测试图分辨率有1536x1024,而另外几个是224p、300p和512p。
天玑9300测试机的成绩是3145分,而骁龙8 Gen 2领先版是2100分上下,骁龙8+是1800分出头,天玑9200是1600分左右,天玑9000在1000分出头。
发哥的领先幅度还是50%左右,这里也有一部分是9600Mbps LPDDR5T内存的功劳,毕竟AI测试对内存性能很敏感。

联发科还有官方的AI演示工具,没有vivo开发者大会那些做得那么精致,但移动SoC的AI性能,还真能玩本地GPT文本创作(大语言模型)和文生图(Stable Diffusion),而且文本和图片生成速度都挺快的。

最后看看娱乐项目。
安兔兔测试包揽的东西太多,变量也极多。例如同样的配置,2K屏就会比1080P屏高2万分左右(因为扫描和滑动场景会更占优),甚至内存大小也会有增益。同代SoC经常有违背强弱认知的结果,例如iOS平台就总是偏低的。另外,它对新机的硬件检测经常会偏出天际,所以一般只能作为定性测试工具。
而安兔兔测试的最大优点,是它会显示测试过程的温升和耗电(跑分截图不敢截温度曲线的,大概率是风箱/冰箱跑分)。
我们手上的天玑9300工程机,安兔兔总分接近214万,高亮度亮屏导致分数偏低,但依然比常温骁龙8 Gen 3量产机高10万分出头,也没落后零下10度的骁龙8 Gen 3太多。而天玑9300量产机的分数早就接近225万分了:
天玑9300工程机,总分213万,CPU 50.7万, GPU 92.8万,内存38.9万,UX 31.2万。
骁龙8 Gen 3,冰箱小米14 Pro(-10.3度,肥威老师),总分218万,CPU 49.3万, GPU 90.4万,内存45.5万,UX 33万
骁龙8 Gen 3 QRD总分215万,CPU 49.4万,GPU 92.7万,内存39.5万,UX 34.6万
骁龙8 Gen 3,小米14,总分200万,CPU 43万,GPU 83.4万,内存42万,UX 31.8万(WHYLAB)
骁龙8 Gen 3,一加12,官方总分211万,CPU 49.6万,GPU 91.4万,内存36.2万,UX 33.8万
骁龙8 Gen 2,小米13,总分157万,CPU 39.7万,GPU 60万,内存29.6万,UX 27.7万(WHYLAB)
A17 Pro,iPhone 15 Pro Max总分149.7万,CPU 36.8万,GPU 52.6万,内存26.4万,UX 33.9万(WHYLAB)
骁龙8 Gen 2的总分160万左右,CPU部分38万,GPU 60万
天玑9200+的总分165万左右,3GHz骁龙8+在130万左右

其实早在半年前,天玑9300 “4颗X4+4颗A720” 的爆料一流出,谁都知道今年发哥的性能是赢定了,大家关心的一直都是能效。
但暂时只能通过游戏来侧面测试,还是得等vivo X100系列这些量产机来最终实锤了。
制程上,今年只有苹果A17 Pro是台积电3nm(虽然实际能效貌似比4nm没啥提升),骁龙8 Gen 3是N4P(和天玑9200一样是台积电第二代4nm),而天玑9300是第三代4nm。
在沟通会中,联发科表示,同在台湾的联发科和台积电关系非常密切,即便是同样名字的工艺,联发科的也是特挑的,一般领先其他厂商半代到1代(苹果是一直是台积电第一大客户,二、三名则是联发科和AMD轮换)。


架构上,今年进步最大的是X4超大核,同性能下的功耗可以降低40%(虽然PPT预设的是3nm工艺),而A720是小改,同性能下最高降低20%功耗。
高通和联发科,都没有采用DSU-120关闭部分L3的功能,都无法关闭个别核心(天玑9300是3个簇,同时最多有3种频率,高通是4种)。
因为制程已经逼近极限,所以未来几年,更重要的革新应该都来自于架构设计。
而安卓生态一直是以8核为基准,所以高通和联发科都在减少小核,把位置让给大核。骁龙8 Gen 2的CPU是5大3小,到骁龙8 Gen 3就变成了6大2小,而天玑9300更是极为“big胆”直接取消小核。

A520、A720和X4的能效曲线(小核的位置,小得都快看不清了)↑
如果Arm的能效曲线属实,那天玑9300确实有取消小核的底气:A720有3种核心里最平缓的能效曲线(轻微的功耗提升,就能换来极大的性能提升)。1颗A720的性能就顶3、4颗A520,而3颗高频A520的功耗就肯定超过低频A720了。

根据官方能效曲线图,横竖转换后的效果↑
天玑9300把A720定在2GHz的超保守频率,摆明就是把大核当小核用。用更大规模的核心跑在低功耗的甜点频率来降低功耗,再给超大核堆料来提升单核性能。唯一缺点,可能就是贵吧(芯片面积更大)。
而完全取消小核,可能还会反直觉地带来功耗上的好处:
最基础的一条:“功耗和性能都低,但要长时间工作”的小核,还真未必比“功耗和性能更高,但工作时长更短”的大核省电。
天玑9300有安卓阵营第一个全乱序执行的CPU。arm公版的小核向来都是顺序执行的,A520也不例外。顺序执行的小核,在和乱序执行的大核、超大核一起工作时,顺序执行的特性会拖累其他核心,更容易造成拥塞(特别是涉及指令和数据存取时)。
没小核拖累,一来能提升速度,二来能缩短大核的工作时长,让其更快回到休眠状态,甚至还会方便桌面游戏的移植(开发者不用为落后的顺序执行小核搞调度)。
理论分析完了,我们这就看看实测,虽然是侧面的,但只有高性能+高能效,才能低功率征服原神↓

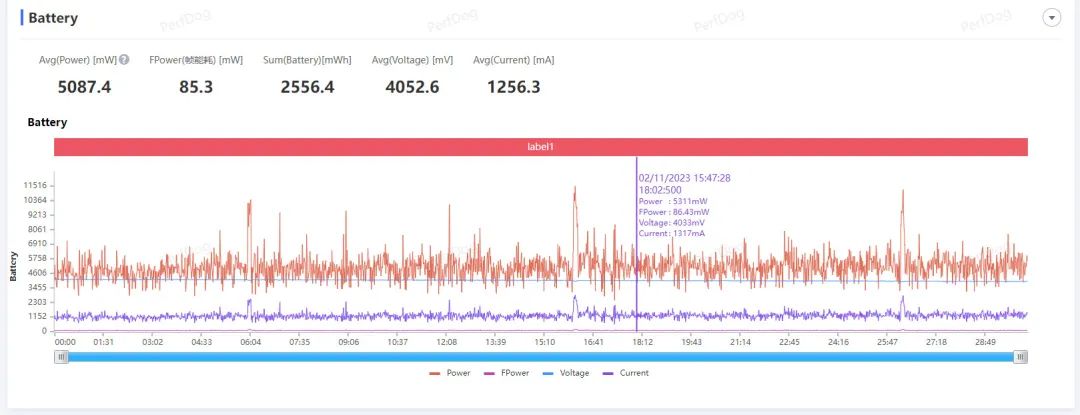
室温23.5度,屏幕固定300尼特亮度,原神60帧最高画质,须弥城跑图30分钟,天玑9300工程机最后平均帧率59.6帧,平均功耗5.09W。
其他用联发科测试路线+260到280尼特亮度的媒体老师,集中在59.7帧,4.85W到4.96W左右。而崩铁是58.8帧,5.12W到5.5W之间。
要知道,这可是300尼特亮度,比我们爱搞机平时用的200尼特测试还高一截。而200尼特下,天玑9200+的iQOO Neo8 Pro有6.4W,骁龙8 Gen 2的iQOO 11S要6.32W。
当然,把它们也调成300尼特,功耗也不会高很多,因为6.4W已经接近非游戏手机能长时间维持的最高功耗了(屏幕抢占功耗,那CPU和GPU就只能降频,导致掉帧和卡顿)。

(工程机的屏幕散热效果还彳亍,但背面完全不行,甚至能看出主板和电池的轮廓↑)
实际机身最高温度40.8度。简直就是离谱他妈给离谱开门,离谱到家了,竟然把原神搞成了中型游戏的功耗和发热。
和跑分一样,天玑9300在游戏里也刷新了历史记录。骁龙8 Gen 3那边,可能就算是游戏手机也未必能做到类似的效果。
虽然须弥城跑图,大家的最高帧都差不多,但天玑9300的小卡顿数目,从骁龙8 Gen 2机型的30-40次/10分钟、骁龙8 Gen 3新机的10次/10分钟,暴降到3.3次。
不开玩笑,在原神里,强大的CPU比什么都实际。

在接性能狗的间隙,我们做了个简单测试,不同亮度下打开图库一张全白图片↑
天玑9300工程机在680尼特全白最高亮度下是3.5W,而300尼特亮度下静息功耗是1.5W,最低亮度是0.8W,静息功耗表现还挺正常。
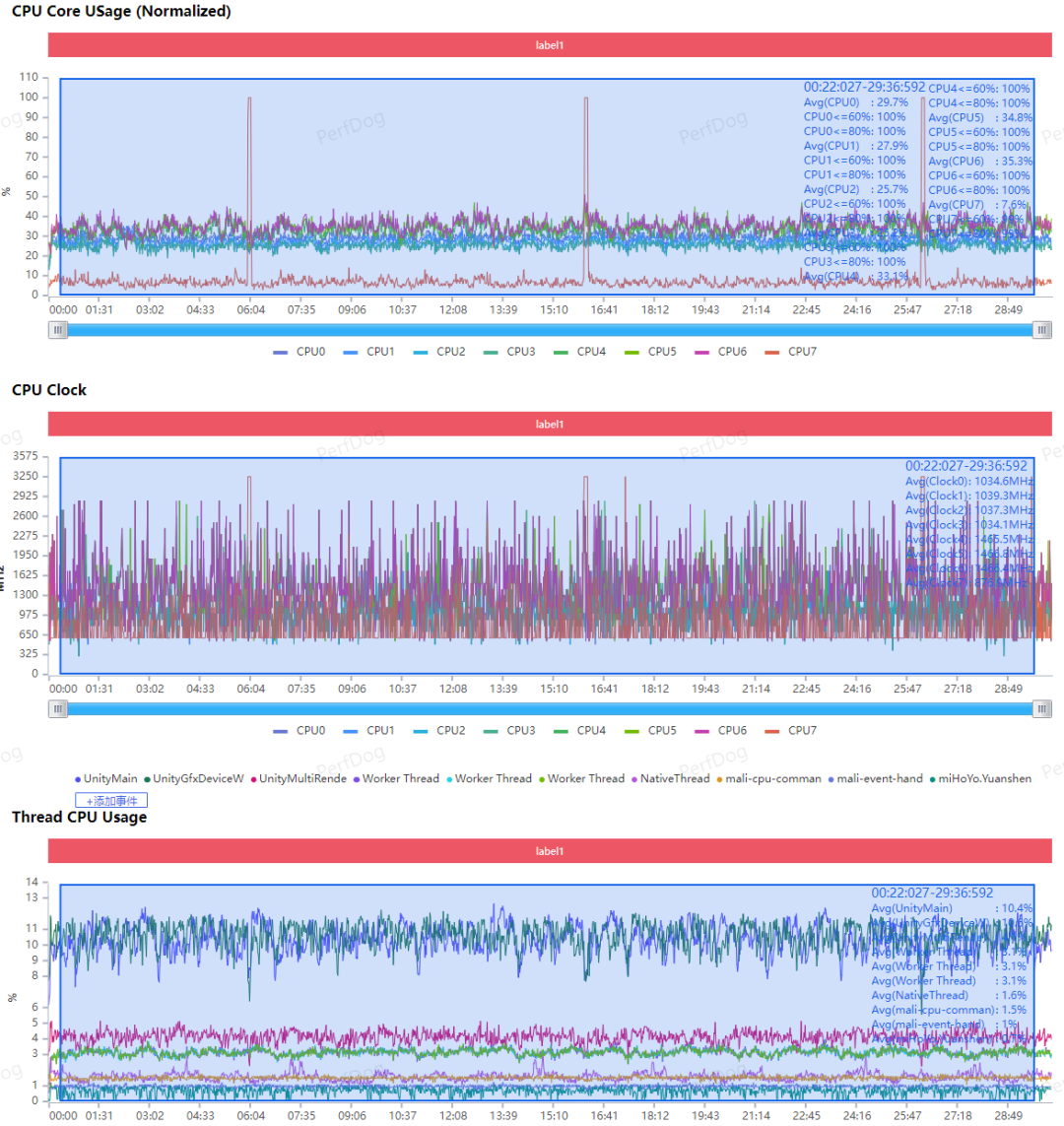
CPU频率与调度情况↑
也就是说,在原神须弥城跑图的时候,5W当中有1.5W喂给屏幕和其他元器件了,CPU和GPU加起来3.5W(期间,A720大核平均1.34GHz,3颗超大核X4平均1.47GHz,超超大核X4是876MHz)。
AI:新的年度C位上一年年底GPT爆发,今年高通和联发科都在端侧的“生成式AI”上重点布局。骁龙8 Gen 3和天玑9300都有文本创作和文生图能力,只是两家的堆料和生态规模不太一样。
天玑9300再次力大砖飞,其搭载的APU 790是首个搭载硬件生成式AI引擎、首个支持生成式AI端侧技能扩充的NPU,有Transformer模型算子的硬件加速,速度是前代的8倍,可1秒文生图(512x512的图片则只要0.5秒左右)。
其支持Meta Llama2、百度文心一言、百川智能百川等大模型,有移动端首个“端侧技能扩充”功能,可以用LoRA融合(Low-Rank Adaptation)对基础大模型做不同的功能拓展。

更猛的地方,是APU 790有硬件内存压缩,宣称可减少61%的内存占用,让天玑9300还成为移动端首个可运行330亿参数AI大语音模型的SoC。
天玑9300可以把130亿参数大模型13GB的内存占用压缩到5GB(16GB内存的手机还能留4GB给系统、6GB内存给APP保活),把330亿参数大模型33GB的内存占用压缩到13GB(需要24GB内存的手机来运行)。而10亿、70亿、130亿参数的大模型自然不在话下。
作为对比,在大家都是77GB/s内存带宽的情况下,骁龙8 Gen 3在70亿参数模型的生成速度也是20Tokens/秒,文生图也是小于1秒,但高通那边只能运行100亿参数的模型,现在只落地了60亿参数的大语言模型。
在国内使用GPT、文生图等AI工具还有一点门槛,这波旗舰芯片的生成AI,很可能会是大部分用户的“第一次接触”。
题外话:关于32位的应用今年的天玑9300和骁龙8 Gen 3,CPU都是纯64位,都没有原生32位支持,但高通和联发科都给了自己的兼容转译方案。
联发科表示有HBT技术,可以把32位应用“转译”成64位处理器能运行的代码(安装后的初次冷启会比原生慢个1秒左右),宣称应用商店前3000多个热门32位应用,都能100%运行。高通传闻也有类似技术,而澎湃OS的小米14系列,确实可以运行大部分32位应用。
而且更搞笑的是,现在所有核心都能一起跑,即便有转译性能损耗,性能也比只能用A510 refresh小核跑的前代强。
我们珍藏的32位无广告+轻量版的网抑云/彩云天气等老App命不该绝。我有个朋友,他说确实那些XX应用也比前代旗舰流畅。

在制程没巨大进步的情况下,天玑9300拿出了一般要两代才能达到的提升幅度。
对比前代动辄40%到50%的CPU/GPU提升、翻倍的AI性能、各种新特性,再加上游戏里的夸张能效表现,就能知道在“芯片面积(成本)-性能-能效”的半导体不可能三角里,发哥的堆料有多猛。
一年间,很多东西都变了。前两年,发哥都是特意抢在高通前面发布的,而今年高通的发布时间反而提前了1个月——或许,如果知道自己会输,抢在对手前发布,起码不会输在起跑线上……
今年发哥有种不慌不忙的自信,一种来自227亿晶体管的自信。
同样是一大堆首发,但今年的笔墨就少很多,像是Immortalis-G720的首发等,甚至都没怎么提。
发哥在天玑9300的测试活动中,还特意加了很多性能限制,像是260到280尼特的屏幕亮度、不能用性能模式,自然也不允许风冷或散热背夹。可能是为了把最强跑分的记录和名头留给ODM厂商,又或者是知道骁龙8 Gen 3怎么跑也赢不了它们。
一句话省流:天玑9300已经不需要跑分去证明自己,发哥尽力了,剩下就看11月13日首发天玑9300的vivo X100的实际表现了。
