[CL]《Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning》V Shrivastava, A Awadallah, V Balachandran, S Garg... [Microsoft Research] (2025)
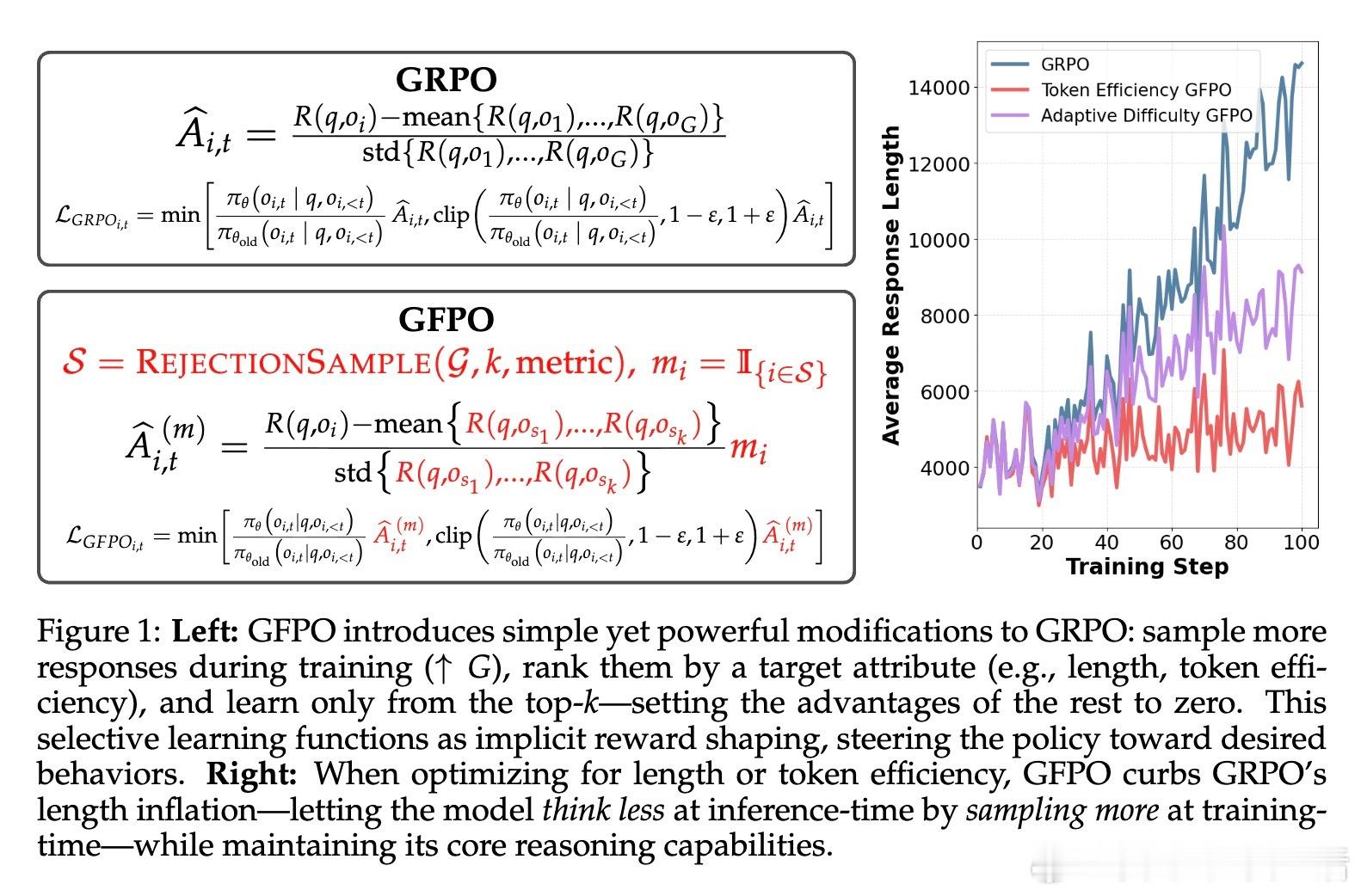
GFPO(Group Filtered Policy Optimization)革新了RL训练中的策略优化,通过采样更多候选回答并筛选出最简洁或最高效的部分进行训练,实现了推理链长度的大幅缩减而不损失准确性。核心亮点包括:
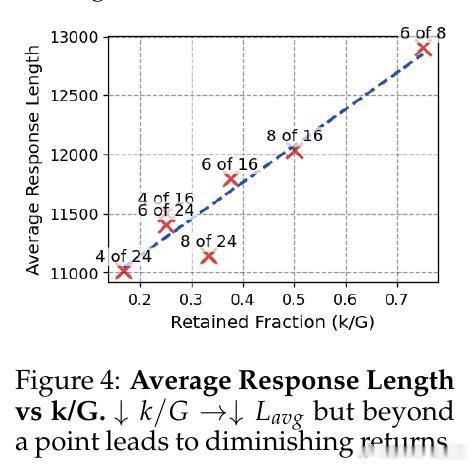
• 样本量提升+筛选机制:训练时从每个问题采样更多响应(G),只保留最短或最高token效率(奖励/长度)前k条进行更新,显著抑制了传统GRPO的响应长度膨胀。
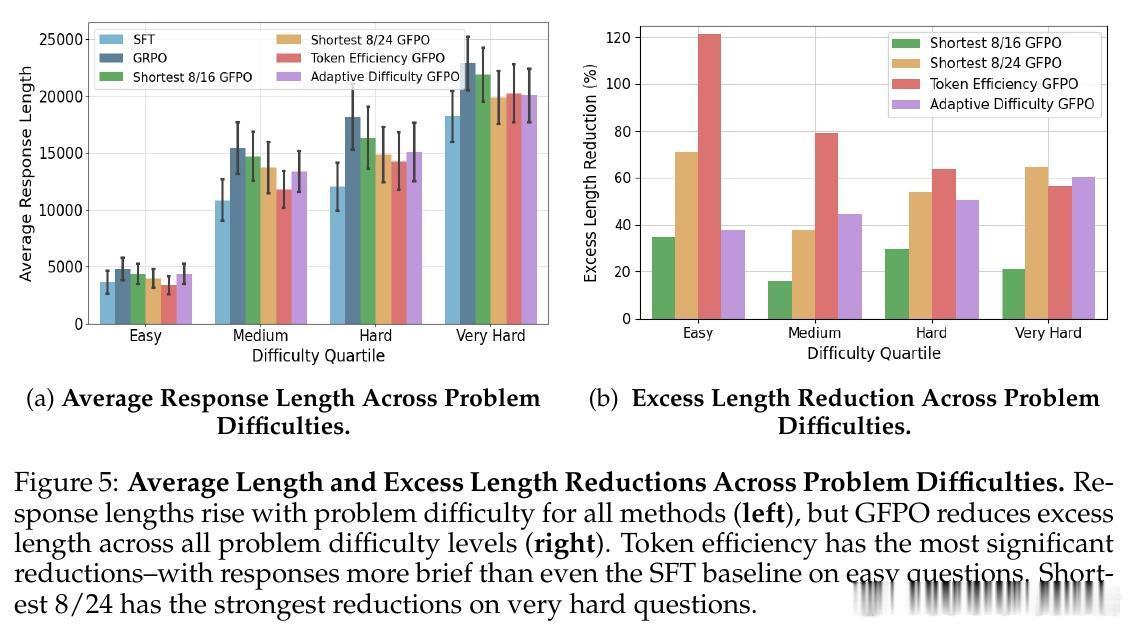
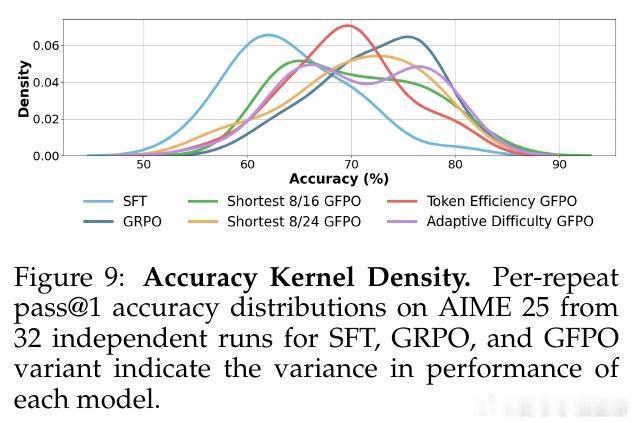
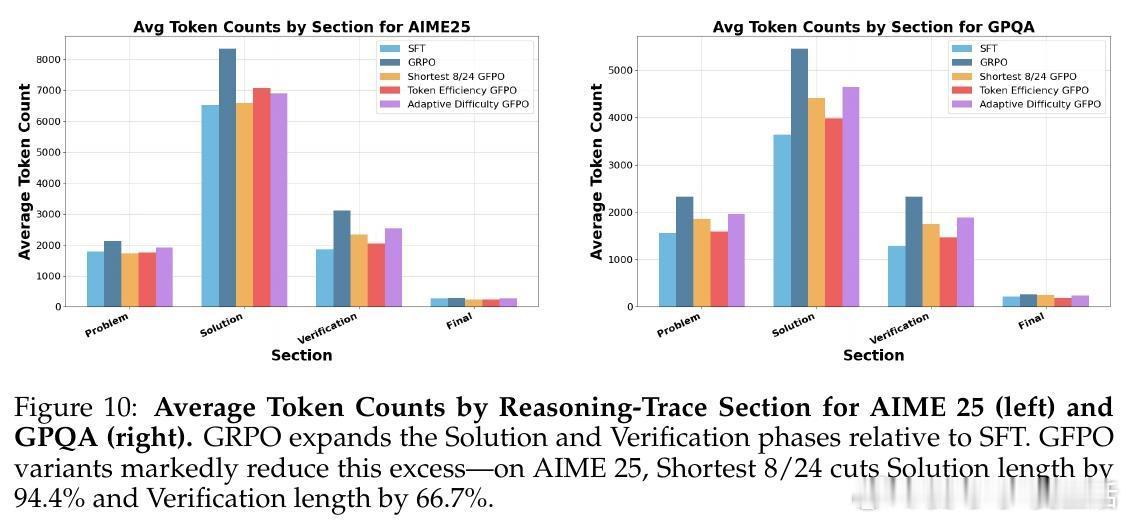
• Token效率优化:引入奖励与响应长度比率作为筛选指标,促使模型生成紧凑且高质量的推理链,长度减少最高达85%,且准确率保持稳定。
• 自适应难度调整:根据问题难度动态调整保留样本数,难题采更多样本以保证准确,简单题强化精简,兼顾效率与性能。
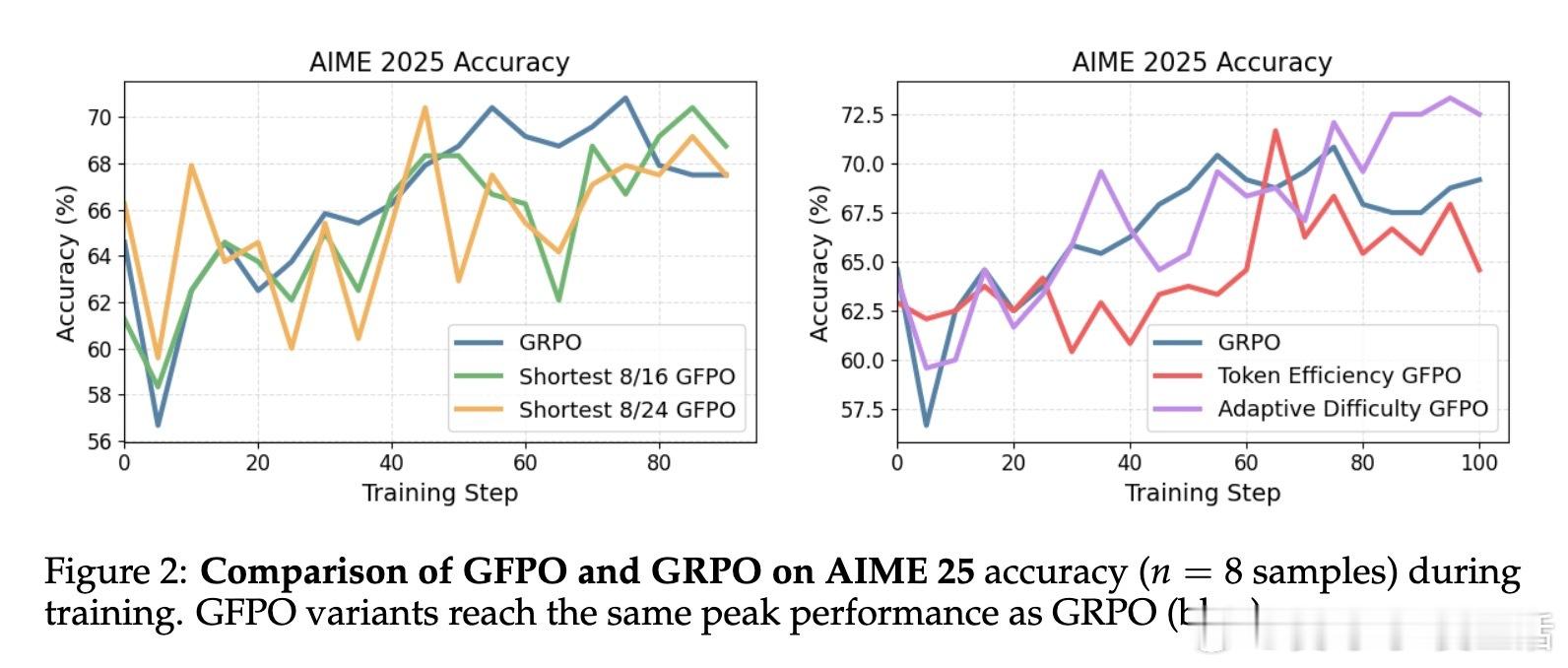
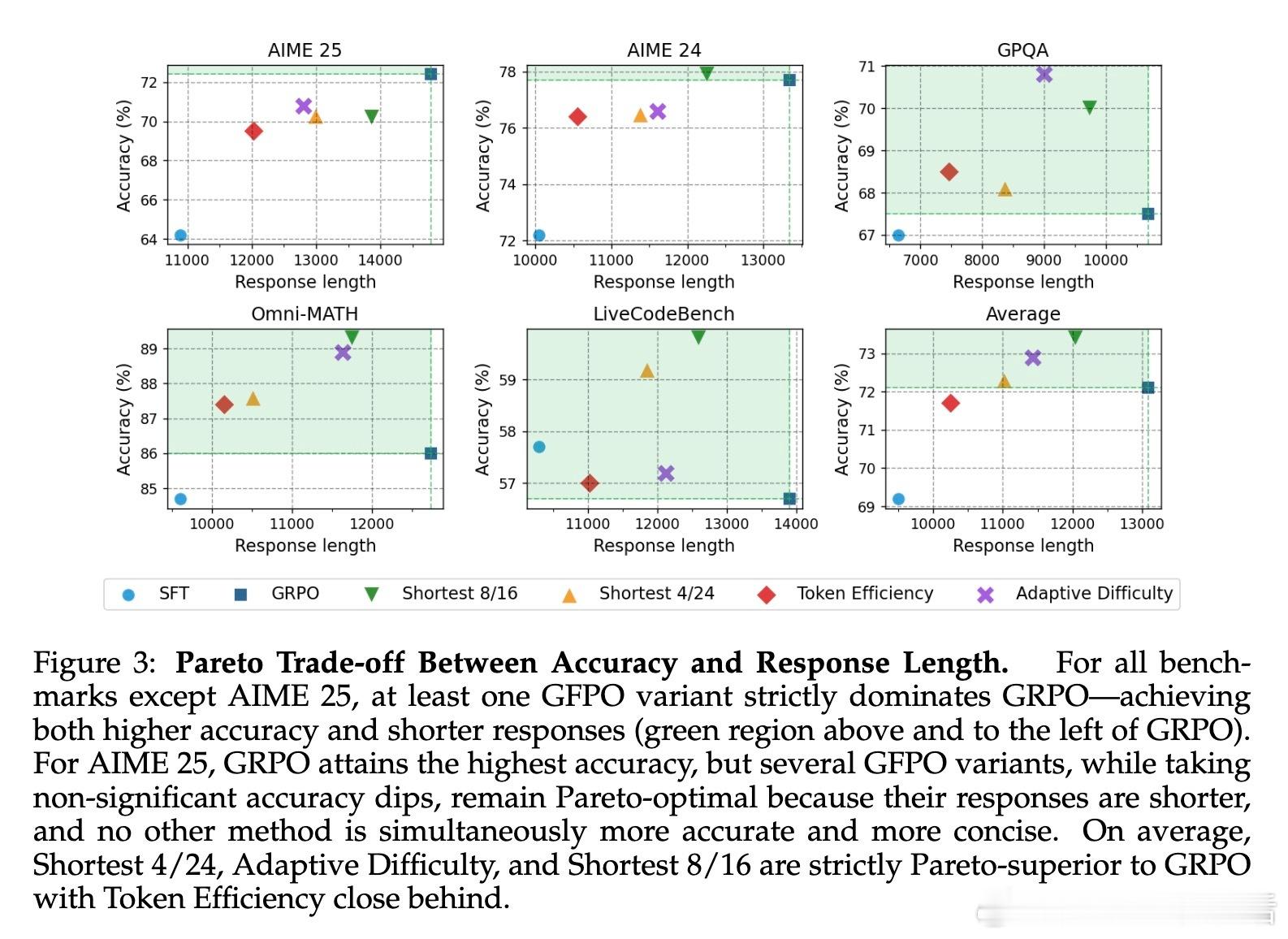
• 跨任务和分布外表现优异:在AIME、GPQA、Omni-MATH以及未见编码任务LiveCodeBench上均有效压缩响应长度,且有时提升准确率。
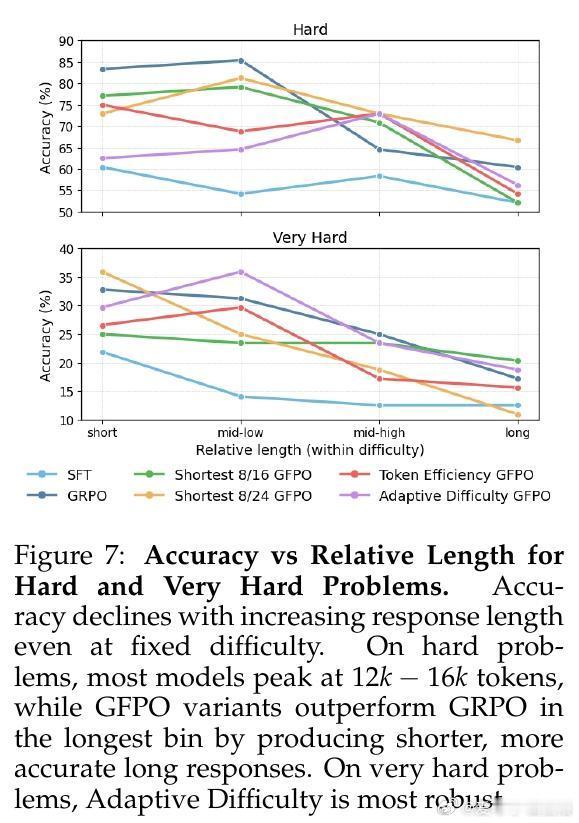
• 长链反直觉现象揭示:即使题目难度固定,过长推理链往往准确率下降,GFPO通过筛选机制帮助模型“少想多效”,找到长度与准确的平衡点。
• 训练与推理计算折中:GFPO在训练阶段付出更多计算资源,换来推理阶段显著节省,提升整体系统效率。
这项技术为训练高效、准确的长文本推理模型提供了切实可行的路径,突破了传统RL训练中长度膨胀的瓶颈。详细解读👉 arxiv.org/abs/2508.09726
强化学习自然语言处理大语言模型推理效率机器学习