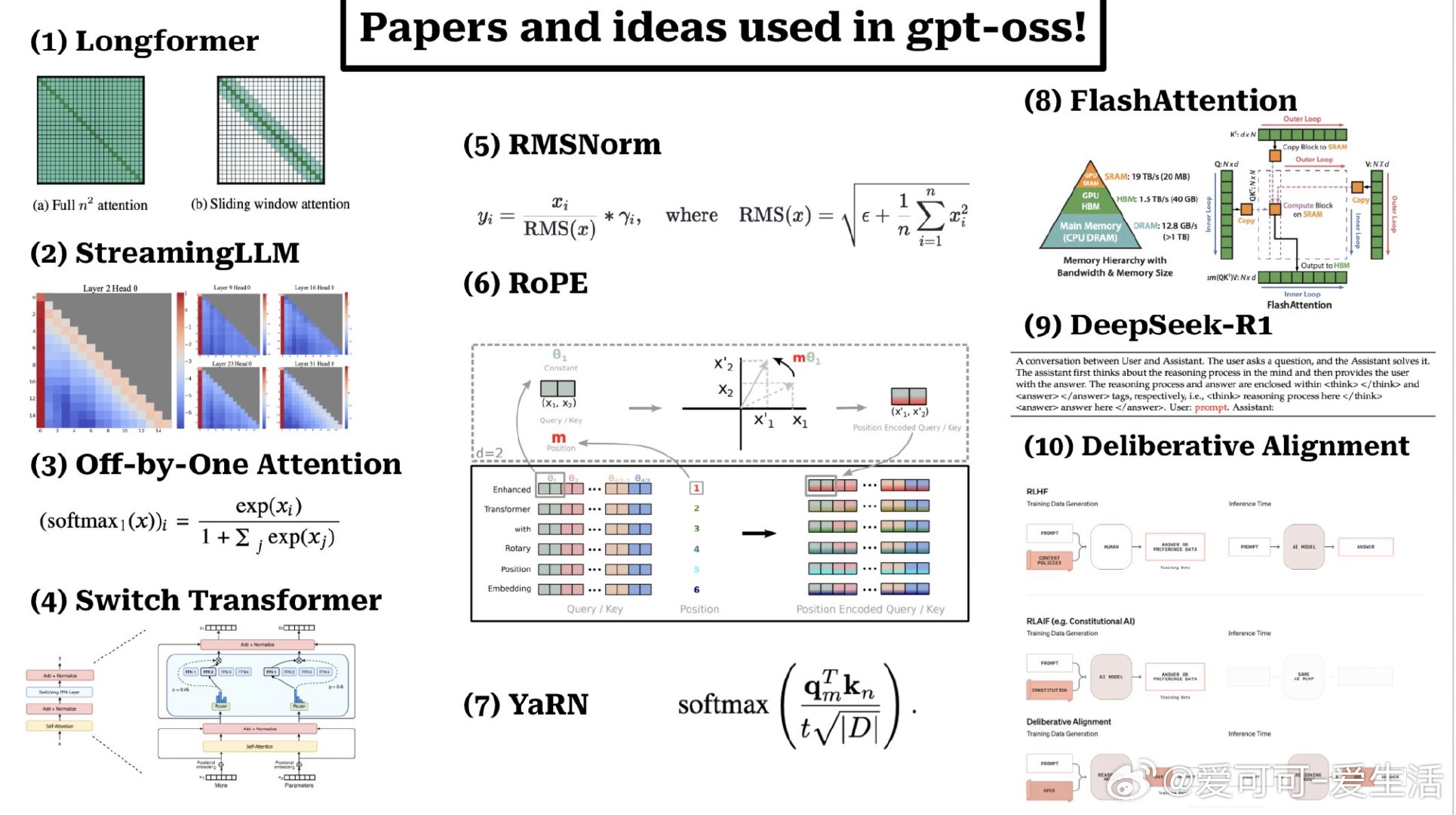
OpenAI 推出的 GPT-OSS 模型融合了多篇前沿论文的关键创新,构建了一个高效且安全的开源大型语言模型(120B 参数),核心技术亮点包括:
• Longformer 的滑动窗口稀疏注意力,提升长文本处理效率,交替应用于模型层间。
• 关注点“attention sinks”问题,采用 Off-by-one attention 的可学习偏置机制,允许模型选择不关注任何 token,解决软最大化(softmax)限制。
• 混合专家模型(MoE)思想借鉴自 Switch Transformer,提升模型扩展能力。
• RMSNorm 替代传统层归一化,简化参数同时提升训练效率。
• Rotary Positional Encoding(RoPE),通过旋转矩阵融合绝对与相对位置编码,增强自注意力机制的上下文感知。
• YaRN 技术延展上下文窗口,通过调整 RoPE 频率基底和额外训练支持更长文本输入。
• Flash Attention 利用系统级优化,显著降低注意力机制的计算与内存开销。
• DeepSeek-R1 报告提供了可验证奖励的强化学习训练框架,推动模型推理能力提升。
• Deliberative alignment 安全训练方法,使模型具备逻辑推理和拒绝不当请求的能力。
GPT-OSS 是少数真正开放源码、兼顾隐私与合规的大规模语言模型,适合需要机密计算环境的企业和研究机构,未来可持续扩展与安全优化。
详读论文合集与技术解读👉 x.com/cwolferesearch/status/1956132685102887059
GPT-OSS 大型语言模型 隐私计算 开源AI 机器学习 人工智能