Deep Research Agent 训练门槛骤降,30小时H200算力即可超越Sonnet-4,开源工具助力人人可达前沿水平。
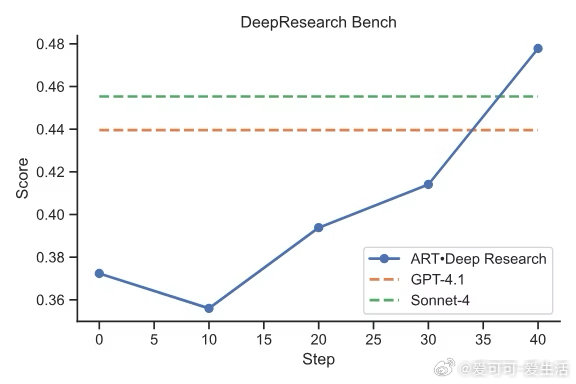
• 利用Agent Reinforcement Trainer (ART) 和 LangChain Open Deep Research框架,将Qwen 2.5 14B模型经过30小时强化训练,打造高效研究代理。
• 训练流程简洁明了:先用SFT掌握基础研究技能,再用GRPO提升执行效率,最终在DeepResearch Bench验证性能。
• 训练模型表现媲美Gemini 2.5 Pro、OpenAI Deep Research、Claude Research等百万级投入的商用系统。
• 公开了完整教程,基于OpenPipe、LangChain、Tavily,$350成本即可复制,极大降低深度研究AI开发门槛。
• 该方案不仅节省资金,更加推动开放研究生态,促进研究效率和创新能力的普惠。
• 社区广泛讨论奖励信号设计、模型可用性及后续扩展,展现该范式的广泛适用潜力。
技术细节与完整教程👉 art.openpipe.ai/tutorials/open-deep-research
强化学习 深度研究 开源AI LangChain 人工智能 研究代理