

作者 | 燕大
1月20日,DeepSeek老板梁文峰进京开会。
当天晚上,DeepSeek(深度求索)的推理模型 DeepSeek-R1 发布,开源、免费、可验证,因为他将技术报告也一同开源了。
没人想得到,仅过4个工作日,这一家不起眼的小公司,竟掀翻了美国科技巨头,一举将中国大模型硬生生拉到世界领先水平。
墙内开花墙外香,缓慢发酵数天后,首先被点“爆”的是大洋彼岸的科技界,接着这两天“DeepSeek”(深度探索)这个英文在各大平台冲上热搜、频繁刷屏。
就是这家来自中国的、名不见经传的小公司,却在美东时间周一,让美股震动,出现少有的暴跌,尤其是芯片、AI科技股。
标普500指数跌了1.46%,纳斯达克指数暴跌3.07%,科技巨头方面,谷歌大跌4.03%,微软下跌2,14%,最最意外的是,全球AI芯片的王者——英伟达,在昨晚暴跌近17%,差点跌了近1/5!市值蒸发约6000亿美元,约合4.27万亿人民币!
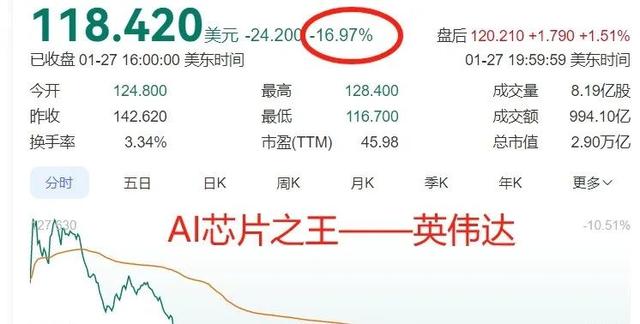
外媒说这是史上最大的一次暴跌,心态都快跌崩了。
说出来你可能都不敢相信,这家来自中国的小公司——DeepSeek,背景是一家炒股的量化公司,名叫幻方量化,炒股的应该都听过。
同样是炒股,量化私募公司不像干金融的,更像搞科研的,从创始人到员工,不少都是学计算机和数学的,岗位包括数据科学家、AI算法研究员、AI架构工程师等,你还在用个人经验炒股的时候,量化公司的决策早就依靠大数据和AI人工智能。
就好比几十年前赢了国际象棋大师的计算机,收割对手的不是另一个象棋高手,而是来自另一个领域的降维打击。
这几年在股市里,能赚到钱赚到打钱的,可能也就是量化私募公司了,跟玩个人经验的完全不是一个级别。
说到这里,我都有种感觉,咱们的大A貌似都成了它训练超级大脑的超级“训练基地”。
DeepSeek公司,是梁文峰在幻方量化私募之外,于2023年5月搞的一个“副业”,单独研究AI大模型技术,没有西方资本风投,员工也多来自国内高校刚毕业的大学生或AI 职业生涯刚起步的开发人员。

为什么不挖更有经验的人?梁说话一段话,“如果追求短期目标,找现成有经验的人是对的,但如果看长远,经验就没那么重要,基础能力、创造性、热爱等,更重要。”
但没想到,这个并不老练的团队,仅用一年多时间,就推出了模仿人类思维的DeepSeek-R1,在数学、编程自然语言推理等任务上,性能比肩当前“地球最强大脑”——OpenAI o1。
外国选手已经验证,对比很直观:
案例1,“编写一个 Python 脚本,让黄色小球在正方形内弹跳,确保正确处理碰撞检测。让正方形缓慢旋转。用 Python 实现。确保小球停留在正方形内”。
左边是OpenAI o1,右边是DeepSeek R1:

案例2,“要求实现一个带有红球的旋转三角形。”
左边是OpenAI o1,右边是DeepSeek R1:

这两个对比非常直观,DeepSeek-R1在数学、编程等复杂推理的性能,与OpenAI o1旗鼓相当甚至超越。
对咱们普通老百姓来说,辅导孩子做数学作业、编程作业甚至奥数都不用烧脑了,用这个app再简单不过。
在语言领域的性能,有从业者举了个更通俗的比喻,用ChatGPT写套路性很强的应用文很好用;
但一旦涉及到高语境、调侃、讽刺之类,就有浓厚的AI味,没有幽默感,但DeepSeek对高于境内容和中文网络上的梗都能理解明白,内容可以达到脱口秀水平。
这大概也是这两天DeepSeek的下载被挤爆的原因,注册都缓慢了不少。
不但在性能上跟世界顶尖水平比肩,在成本上,DeepSeek的训练成本还足够低!
根据公布的技术文档,DeepSeek-V3模型的训练成本只有557.3万美元,使用的还是“阉割版”的英伟达H800 GPU集群。
而同样是开源模型的Meta旗下某一模型的训练成本就超过6000万美元,OpenAI-4o的训练成本为1亿美元,且用的是性能更爆棚的英伟达H100 GPU集群。
换句话说,即使哪天DeepSeek模型要收费了,估计也是白菜价。
两相对比,更差的装备、更低的成本,却干掉了装备精良武装到牙齿的王者,这你找谁说理去!
上架10天不到,用实力击败ChatGPT,登顶苹果应用商店排行榜。以极低的成本构建出了一个突破性的人工智能模型,DeepSeek横空出世,甚至导致一个筹集了10亿美元的前沿实验室,因为产品比不过DeepSeek,连发布都不敢发布了。
到现在很多人也有点难以置信,中国一个不起眼的小公司,进京开了个座谈会后,发布的AI模型,竟然比肩甚至超越美国“最强大脑”OpenAI o1,真的匪夷所思。
但现实又再真实不过!
DeepSeek的横空出世,直接打破西方前沿科技只可追赶无法超越的神话。
其实,关注时政的人应该能察觉,1月20日,新闻联播报道DeepSeek创始人梁文峰获邀参加高层座谈会,就是个重大信号。
首先,肯定是这个小公司在AI领域有了特别重大突破;
其次,就是这个突破在世界上都属于领先。
要知道,这些年国家为了应对西方科技封锁,解决卡脖子问题,拉近中美之间硬科技的距离,急迫性,人所共知,要政策给政策、要钱给钱,普遍撒网,为的就是有朝一日有人能够取得突破性进展。

在硬科技、前沿赛道上,国家高度关注,要不然也不会出现DeepSeek创始人在最新模型发布前进京开会那一幕。
DeepSeek的横空出世,让美国科技圈睡不着觉,同样也让很多国人睡不着觉。
无他,实在是冲击太大了,对国人来讲,美国从0到1、中国从1到100是脑子里的固定模式,突然出现中国AI技术比肩甚至超越世界顶尖,非常不可思议。
其实,中美网民小红书对账,让很多国人对欧美文化、生活环境祛魅,而DeepSeek再一次证明,哪怕是前沿科技,也应该对西方祛魅。
任正非说过,从国外引进来的高新技术,打开后发现竟是中国鸡下的蛋。
中国从来不缺人才,也不缺天才,缺的是敢想象,敢独立自主走自己的路。
不起眼的小公司DeepSeek,靠性能较差的硬件和并不老练的团队,掀翻英伟达,有人说,这是以少胜多、以弱胜强。
我却觉得,哪有什么以少胜多、以弱胜强,都只是表象罢了。
所谓以少胜多、以弱胜强,本质都是以强胜弱!
