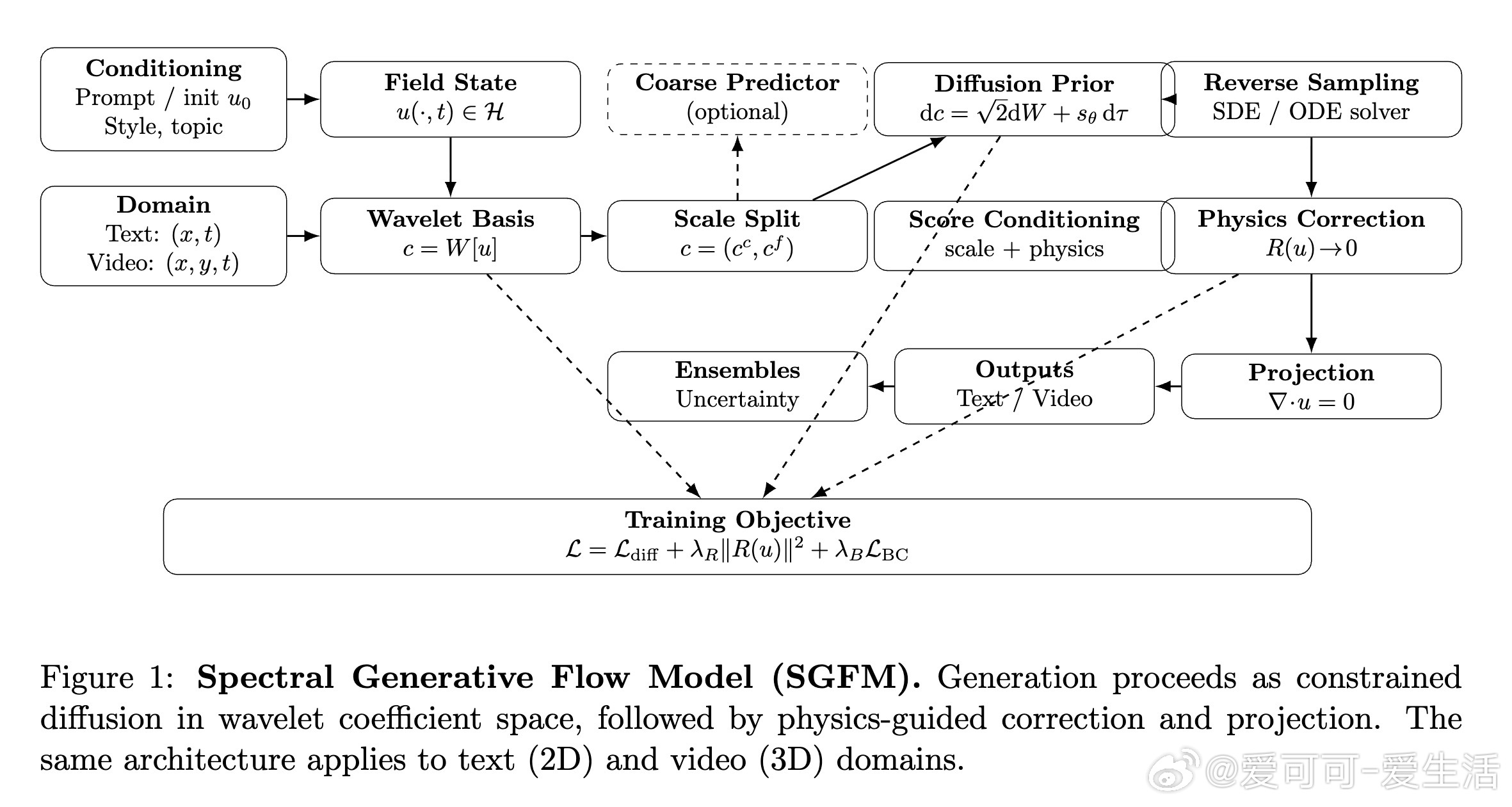
[LG]《Spectral Generative Flow Models: A Physics-Inspired Replacement for Vectorized Large Language Models》A Kiruluta [UC Berkeley] (2026) 生成式AI的范式正在发生根本性的动摇。长期以来,我们习惯了Transformer架构和Token化(Tokenization)的离散思维,本文提出的“谱生成流模型”(Spectral Generative Flow Models, SGFM)宣告:注意力机制可能只是一个过渡,物理启发下的连续场动力学才是未来。以下是关于这一范式转移的深度解析:1. 告别注意力的“二次方枷锁”Transformer架构的成功建立在全局注意力机制上,但其$O(N^2)$的计算复杂度让长文本和高分辨率视频生成面临巨大的成本瓶颈。SGFM提出了一个深刻的洞见:注意力并非智能的基石,而只是对信息传播的一种计算近似。在物理世界中,长程相干性是通过局部动力学随时间的累积而产生的,而非瞬时的全局耦合。SGFM通过局部算子和谱投影,将复杂度降至$O(N \log N)$,彻底绕过了注意力的瓶颈。2. 从离散Token到连续场的本体论跃迁目前的vLLM(向量化大语言模型)将文本视为离散符号的序列,这在本质上破坏了语义的几何结构。SGFM引入了场论视角,将生成视为连续场在函数空间中的演化。文本不再是珠串,而是流动的河水。这种从离散到连续的转变,让模型能够直接利用微分算子、拓扑学和度量结构,使语义的平滑插值和不确定性的动态传播成为可能。3. 纳维-斯托克斯方程:生成的物理模板SGFM最令人惊叹的创新在于借用了流体力学中的纳维-斯托克斯(Navier-Stokes)方程作为生成先验。研究者将文本生成视为二维不可压缩流,视频生成则是三维流。流体动力学中的“不可压缩性”被转化为一种语义约束,防止生成过程中信息的凭空消失或幻觉的无序产生。这种物理启发式的归纳偏置,为模型提供了天然的稳定性与相干性。4. 小波变换:多尺度结构的效率王牌为了实现极高的数据效率,SGFM在小波谱空间(Wavelet Domain)中进行操作。小波变换天然具备空间和频率的局部性:低频系数捕捉全局语义和叙事结构,高频系数刻画局部语法和纹理细节。这模仿了人类的认知过程:先有大纲,再填细节。这种尺度分离不仅减少了样本复杂度,更让模型在处理长程依赖时游刃有余。5. 维度的普适性:统一文本与视频在SGFM框架下,文本(2D)和视频(3D)在数学表达上是完全统一的。不同模态之间不再需要特定的Token化方案或复杂的架构调整,唯一的变量只是定义域的维度。这种“维度普适性”镜像了物理统一场论的理想——同一套方程,既能描述文字的流动,也能刻画光影的变迁。6. 训练目标:统计匹配与物理约束的交响SGFM的训练不再仅仅是简单的似然估计,而是一个复合目标:它结合了扩散模型的得分匹配(Score Matching)来学习分布,以及物理残差损失来强制执行守恒定律。这是一种受约束的随机演化,确保生成的每一个步骤都既符合统计规律,又满足物理逻辑。这种结构化的约束,是解决AI幻觉问题的硬核路径。深度思考:我们正处于从“注意力中心化”向“结构化流动力学”转型的节点。Transformer教会了我们如何利用大规模数据进行统计模拟,而SGFM则试图赋予模型一种“物理直觉”。如果说Transformer是在做符号的排列组合,那么SGFM就是在构建语义的物理规律。生成不再是预测下一个点,而是引导一场流动的演变。arxiv.org/abs/2601.08893