
在本地环境下对大规模语言模型(LLMs)进行微调时,由于GPU显存限制,采用大批量训练通常难以实现。为解决此问题,一般普遍会采用梯度累积技术来模拟较大的批量规模。该方法不同于传统的每批次更新模型权重的方式,而是通过在多个小批量上累积梯度,在达到预设的累积次数后才执行权重更新。这种方法有效地实现了大批量训练的效果,同时避免了常见的内存开销问题。
理论上设置批量大小为1并在32个批次上累积梯度,其效果应等同于直接使用批量大小32进行训练。但是实际研究发现,在使用主流深度学习框架(如Transformers)时,梯度累积方法往往导致模型性能显著低于直接使用大批量训练的结果。
这一问题在reddit上引起了广泛讨论,并且Unsloth AI的Daniel Han成功复现了该问题。他发现这一问题不仅影响单机梯度累积,还影响多GPU训练环境。在多GPU配置中,由于梯度在多设备间隐式累积,会导致模型训练效果不达预期。并且这个问题可能在过去多年的模型训练中一直存在且未被发现。
本文将从以下几个方面展开讨论:首先阐述梯度累积的基本原理,通过实例说明问题的具体表现和错误累积过程;其次分析不同训练场景下该问题的影响程度;最后评估Unsloth提出并已被Hugging Face在Transformers框架中实现的修正方案的有效性。
梯度累积技术详解神经网络训练过程分析神经网络的训练过程包含以下关键步骤:通过前向传播生成预测结果,计算预测值与真实值之间的损失,然后通过反向传播计算梯度以优化模型权重。在标准训练流程中,每个批次的梯度计算完成后都会立即用于更新模型权重。
采用较大的批量规模通常能提供更稳定的训练过程,并有助于提升模型性能和泛化能力。但是,大批量训练需要较大的内存空间,特别是在梯度计算和存储方面。在硬件资源受限的情况下,可能无法一次性将大批量数据加载到内存中,这就限制了实际可用的批量大小。
梯度累积的实现机制
梯度累积技术通过将大批量数据分解为多个小批量来实现大规模批量训练。不同于传统方法在每个小批量后更新模型权重,该技术在多个小批量上累积梯度,仅在完成预定的累积步骤后执行一次权重更新。具体实现机制如下:
首先确定目标有效批量大小和硬件可承载的小批量大小。若目标有效批量大小为64,而硬件每次仅能处理16个样本,则需要在4个规模为16的小批量上进行梯度累积。
训练过程中,对每个小批量执行前向传播、损失计算和反向传播操作,计算得到梯度。此时不直接更新权重,而是将梯度存入累积缓冲区。
当处理的小批量数达到预设阈值(如上例中的4个小批量)后,对累积的梯度进行平均,用该平均梯度更新模型权重。随后清空累积缓冲区,进入下一轮累积循环。
梯度累积的应用场景当前主流的大规模语言模型和视觉语言模型往往规模庞大,其参数量通常超出单个GPU的内存容量。这种情况下梯度累积技术具有显著优势。
主要应用场景包括:
资源受限环境下的大模型训练:对于大型Transformer模型或用于图像处理的卷积神经网络(CNNs),其完整批量训练所需的内存往往超出硬件限制。梯度累积使得在有限资源条件下实现等效的大批量训练成为可能。
分布式训练环境优化:在多设备训练配置中,梯度累积可有效降低设备间的同步频率。各设备可先在本地累积梯度,仅在完成累积周期后进行一次同步,显著减少了通信开销。
实际应用中,梯度累积已成为各类模型训练过程(包括预训练、微调和后训练等阶段)的标准技术之一。
梯度累积中的归一化问题从理论上讲,使用N个样本的单一批量训练应与使用4个N/4样本小批量的梯度累积训练在数学上等价。
但是其实并不是这样
简单的梯度求和策略无法确保梯度累积与完整批量训练的数学等价性。在大多数LLM训练中使用的交叉熵损失计算过程中,通常需要对非填充或非忽略的token数量进行归一化,确保损失值与训练序列中的有效token数量相匹配。为简化分析,我们假设序列长度等于数据集平均长度。
在实际的梯度累积过程中,各小批量的损失被独立计算后直接相加,这导致最终的总损失比完整批量训练的损失大G倍(G为梯度累积步数)。要修正这一问题,需要对每个累积的梯度进行1/G的缩放,以匹配完整批量训练的结果。然而这种缩放方法的有效性建立在小批量间序列长度一致的假设之上。
在实际训练LLM等模型时,序列长度的变化是常见现象,这种变化会导致损失计算出现偏差。在因果语言模型训练等应用场景中,正确的梯度累积方法应当首先计算累积步骤中所有批次的总体损失,随后将其除以这些批次中非填充token的总数。这与单独计算每个批次损失后取平均的方法有本质区别。
所以当小批量中的序列长度一致且无需填充时,传统的梯度累积方法仍然有效。对于不熟悉填充机制的读者,建议参考相关技术文档以深入理解其对批处理的影响。
从技术实现角度分析,LLM预训练阶段受此问题影响相对较小。尽管预训练过程需要大量GPU资源进行梯度累积,但该阶段通常采用完整的大规模批次,包含连续的文档块,无需填充操作。预训练阶段的设计目标是最大化单个训练步骤的学习效果。这也解释了为什么许多LLM的词汇表中不包含填充token,因为预训练阶段未使用填充操作。
梯度累积问题的实验验证为量化分析错误梯度累积对训练过程的影响,本研究使用Unsloth对SmolLM-135M(Apache 2.0许可)进行了系统性实验,测试了不同批量大小、梯度累积步骤和序列长度配置下的模型表现。
实验环境采用内存效率优化的Unsloth框架和规模适中的LLM,以便在48GB GPU(RunPod提供的A40)上进行大批量训练实验。
大规模梯度累积步骤的影响分析首先验证梯度累积的问题存在性。理论上以下训练配置应产生几乎一致的学习曲线:
per_device_train_batch_size = 1,gradient_accumulation_steps = 32
per_device_train_batch_size = 32,gradient_accumulation_steps = 1
per_device_train_batch_size = 2,gradient_accumulation_steps = 16
per_device_train_batch_size = 16,gradient_accumulation_steps = 2
这些配置的总体训练批量规模均为32。
本研究关注的是配置间的相对损失差异,而非绝对损失值。在最大序列长度2048 token(SmolLM支持的上限)条件下的学习曲线:

不同批量大小(bs)和梯度累积步骤(gas)配置下的学习曲线对比,可以看到在序列长度512 token条件下的学习曲线:

实验数据显示,批量大小(bs)为32与梯度累积步骤(gas)为32的配置间存在显著差异。当降低梯度累积步骤至16时,这种差异程度有所减小。
数据分析表明,gas=32配置下的损失值无法完全收敛到bs=32的水平。对于2048 token序列长度的配置,损失差异稳定在0.2至0.3区间;而对于512 token序列长度的配置,差异范围在0.1至0.2之间。
2048 token序列长度配置表现出更大的性能差异,这一现象表明小批量中填充序列的增加会显著放大梯度累积的偏差效应。
序列长度高度离散场景的实验分析为深入研究该问题,作者构造了序列长度高度不均匀的小批量测试场景。以最大序列长度2048 token为例,当一个小批量中包含1个有效token的序列(附带2047个填充token),而另一个包含2048个有效token的完整序列(无填充)时,由于序列长度的极端差异,梯度累积的偏差会被显著放大。
实验中,通过从微调数据集中筛选出序列长度分布的两个极端(仅保留短于256 token和长于1024 token的序列),人为构造了序列长度的高度离散性。
实验获得的学习曲线如下:

如预期所示,序列长度的极端变化和分布稀疏性导致了更显著的性能退化。损失差异维持在0.45至0.70的较大区间内。
实验结论 该问题对于序列长度分布范围广泛的数据集训练配置产生了显著的负面影响。
序列长度一致性场景的实验验证虽然序列长度的显著变化会加剧梯度累积的问题,但在处理序列长度相对一致的数据集时,这一问题的影响应当显著降低。在这种情况下梯度累积的偏差应被最小化。
为验证这一假设,实验将最大序列长度设定为1024,并仅保留长度不少于1024 token的序列进行微调。在此配置下,所有序列均无需填充,超长序列则被截断至1024 token。
实验中所有小批量的序列长度保持一致:
实验结果符合理论预期,学习曲线呈现出高度的一致性。虽然在约210个训练步骤后出现微小差异,但这可归因于使用8位量化AdamW优化器所引入的数值近似误差。
该实验从实践角度验证了序列长度一致时梯度累积的有效性。这也进一步佐证了之前的推断:LLM预训练阶段受此问题影响相对较小,因为预训练过程中极少使用序列填充,开发者通常会最大化利用每个批次中的token数量以提高内存使用效率。
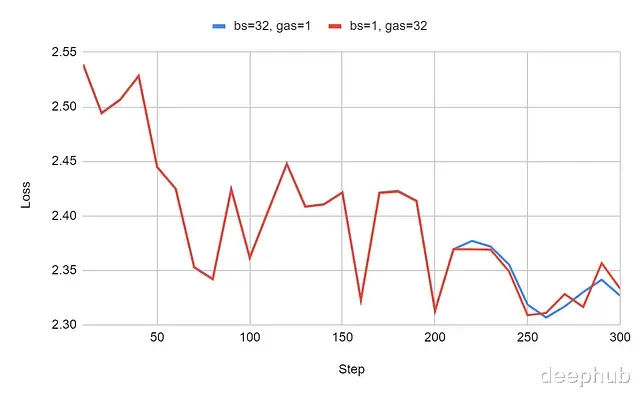
梯度累积修正方案的实验验证为验证Unsloth提出并经Hugging Face实现的修正方案的有效性,我们需要评估修正后带梯度累积和不带梯度累积配置的学习曲线一致性。
首先需要更新Transformers库环境。由于该修正方案近期才合并入主分支,我们采用以下命令从源代码更新:
pip install --upgrade --no-cache-dir "git+https://github.com/huggingface/transformers.git"
在最大序列长度2048 token配置下的学习曲线对比:

实验结果表明修正方案取得了预期效果:bs=32, gas=1配置与bs=1, gas=32配置的学习曲线实现了有效对齐。梯度累积的数学等价性得到了恢复。虽然在图中并不明显,但详细数据分析显示在某些训练步骤中仍存在最大约0.0004的微小差异,这可归因于AdamW量化过程中引入的数值近似计算误差。
总结鉴于该问题影响了跨设备和小批量的梯度累积机制,可以推断过去若干年间的部分模型训练结果可能处于次优状态。
研究结果表明其影响程度主要取决于具体的训练配置,尤其是涉及的GPU数量和梯度累积步骤数。采用大规模梯度累积步骤或高度可变序列长度进行训练的模型可能经历了次优的学习过程,这可能导致了下游任务性能的损失。
随着该问题在Hugging Face Transformers框架中得到识别和修正,未来的模型训练和微调工作有望获得更优且更稳定的效果。对于研究界和工业界此前使用受影响框架的相关工作,建议重新评估使用修正后梯度累积方案进行训练是否能带来显著性能提升。
总体而言,尽管该问题的具体影响范围尚待进一步量化研究,但可以确定的是采用有缺陷梯度累积方案训练的模型存在明显的优化空间。本研究不仅指出了一个长期被忽视的技术问题,也为未来的模型训练实践提供了重要的优化方向。
reddit帖子:
https://avoid.overfit.cn/post/abe2d4a766f343d3b7d3906cd2e807a1
作者:Benjamin Marie
