在机器学习领域存在一个普遍的认知误区,即可解释性与准确性存在对立关系。这种观点认为可解释模型在复杂度上存在固有限制,因此无法达到最优性能水平,神经网络之所以能够在各个领域占据主导地位,正是因为其超越了人类可理解的范畴。
其实这种观点存在根本性的谬误。研究表明,黑盒模型在高风险决策场景中往往表现出准确性不足的问题[1],[2],[3]。因此模型的不可解释性应被视为一个需要克服的缺陷,而非获得高准确性的必要条件。这种缺陷既非必然,也非不可避免,在构建可靠的决策系统时必须得到妥善解决。
解决此问题的关键在于可解释性。可解释性是指模型具备向人类展示其决策过程的能力[4]。模型需要能够清晰地展示哪些输入数据、特征或参数对其预测结果产生了影响,从而实现决策过程的透明化。
PyTorch Geometric的可解释性模块为图机器学习模型提供了一套完整的可解释性工具[5]。该模块具有以下核心功能:
关键图特性识别 — 能够识别并突出显示对模型预测具有重要影响的节点、边和特征。
图结构定制与隔离 — 通过特定图组件的掩码操作或关注区域的界定,实现针对性的解释生成。
图特性可视化 — 提供多种可视化方法,包括带有边权重透明度的子图展示和top-k特征重要性条形图等。
评估指标体系 — 提供多维度的定量评估方法,用于衡量解释的质量。
可解释性模块的系统架构图
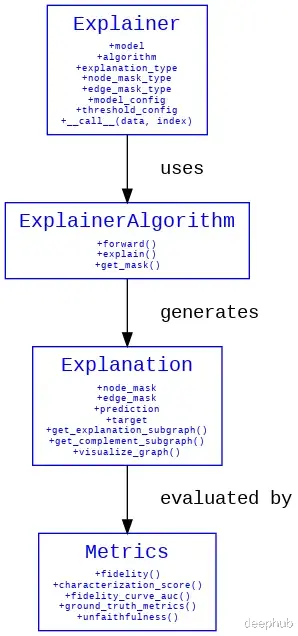
我们下面使用Reddit数据集来进行详细的描述
数据集我们选用Reddit数据集作为实验数据。该数据集是一个包含不同社区Reddit帖子的标准基准数据集,可通过PyTorch Geometric提供的公开数据集仓库直接访问。
Reddit数据集的规模较大,包含232,965个节点、114,615,892条边,每个节点具有602维特征,共涉及41个分类类别。考虑到数据集规模,我们采用NeighborLoader类实现小批量处理。该类提供了一种高效的采样机制,可以对大规模图数据集中的节点及其k-跳邻域进行小批量采样。所以设置了三个NeighborLoader实例,分别用于训练、测试和可解释性分析。num_neighbors和batch_size参数可根据系统资源情况进行调整。
# 数据集加载与预处理dataset = Reddit(root="/tmp/Reddit") data = dataset[0] train_loader = NeighborLoader( data, input_nodes=data.train_mask, # a=第一层邻居采样数量 # b=第二层邻居采样数量 num_neighbors=[a, b] batch_size=batch_size, shuffle=True ) test_loader = NeighborLoader( data, input_nodes=data.test_mask, num_neighbors=num_neighbors, batch_size=batch_size, shuffle=False # 测试阶段保持顺序以确保可重复性 ) explain_loader = NeighborLoader( data, batch_size=batch_size, num_neighbors=num_neighbors, shuffle=True )
GraphSAGE我们采用GraphSAGE作为基础模型架构。GraphSAGE是一个专为归纳学习设计的图神经网络框架,其特点是能够将预测能力泛化到未见过的节点。模型的高效邻居采样机制使其特别适合处理Reddit这样的大规模图数据集。以下代码展示了模型的核心结构及其训练、测试方法的实现。
# GNN模型定义class SAGE(torch.nn.Module): def __init__(self, in_channels, hidden_channels, out_channels): super().__init__() self.convs = torch.nn.ModuleList() # 构建双层网络结构 self.convs.append(SAGEConv(in_channels, hidden_channels)) self.convs.append(SAGEConv(hidden_channels, out_channels)) def forward(self, x, edge_index): for i, conv in enumerate(self.convs): x = conv(x, edge_index) if i < len(self.convs) - 1: x = F.relu(x) x = F.dropout(x, p=0.5, training=self.training) return x
模型训练实现
# 训练过程实现def train(model, loader, optimizer, device, num_train_nodes): model.train() total_loss = 0 total_correct = 0 for batch in tqdm(loader, desc="Training"): # 数据迁移至指定计算设备 batch = batch.to(device) # 前向传播计算 optimizer.zero_grad() out = model(batch.x, batch.edge_index) # 损失计算与反向传播 loss = F.cross_entropy(out[batch.train_mask], batch.y[batch.train_mask]) loss.backward() optimizer.step() # 计算当前批次训练节点的预测准确率 pred = out[batch.train_mask].argmax(dim=-1) total_correct += int((pred == batch.y[batch.train_mask]).sum()) total_loss += loss.item() return total_loss / len(loader), total_correct / num_train_nodes
模型评估实现
# 测试过程实现def test(model, loader, device): model.eval() total_correct = 0 total_test_nodes = 0 for batch in tqdm(loader, desc="Testing"): batch = batch.to(device) # 预测计算 with torch.no_grad(): out = model(batch.x, batch.edge_index) pred = out.argmax(dim=-1) # 评估测试节点的预测准确率 mask = batch.test_mask total_correct += int((pred[mask] == batch.y[mask]).sum()) total_test_nodes += mask.sum().item() # 计算整体测试准确率 accuracy = total_correct / total_test_nodes return accuracy
Explainer模块配置要启用可解释性分析功能,首先需要完成Explainer的初始化配置。以下是相关参数的详细说明:
model: torch.nn.Module, algorithm: ExplainerAlgorithm, explanation_type: Union[ExplanationType, str], node_mask_type: Optional[Union[MaskType, str]] = None, edge_mask_type: Optional[Union[MaskType, str]] = None, model_config: Union[ModelConfig, Dict[str, Any]], threshold_config: Optional[ThresholdConfig] = None
下面对各参数进行详细说明:
**model: torch.nn.Module** — 指定需要进行可解释性分析的PyG模型实例。
**algorithm: ExplainerAlgorithm** — 可选的解释器算法:
这里主要要使用_GNNExplainer
DummyExplainer: 用于生成随机解释的基准测试器
GNNExplainer: 基于"GNNExplainer: Generating Explanations for Graph Neural Networks"论文实现[6]
CaptumExplainer: 集成Captum开源库的解释器[7]
PGExplainer: 基于"Parameterized Explainer for Graph Neural Network"论文实现[8]
AttentionExplainer: 基于注意力机制的解释器[9]
GraphMaskExplainer: 基于Interpreting Graph Neural Networks for NLP With Differentiable Edge Masking论文实现[10]
**explanation_type: Union[ExplanationType, str]** — 解释类型配置,包含两种选项:
"model": 针对模型预测机制的解释
调用Explainer时可通过index参数指定待解释的节点、边或图的索引,实现精确定位分析。
"phenomenon": 针对数据内在特征的解释
调用时需要通过target参数指定包含所有节点真实标签的张量。这使得Explainer能够比对模型预测与真实标签,从而识别图中对模型决策过程最具影响力的组件(节点、边或特征),并评估其与真实数据分布的一致性。
mask_type参数配置
**node_mask_type: Optional[Union[MaskType, str]] = None**
**edge_mask_type: Optional[Union[MaskType, str]] = None**
提供四种掩码策略:
None: 不进行掩码处理
"object": 整体掩码策略,每次掩码一个完整的节点/边
"common_attributes": 全局特征掩码,对所有节点/边的指定特征进行掩码
"attributes": 局部特征掩码,仅对指定节点/边的特定特征进行掩码
**model_config: Union[ModelConfig, Dict[str, Any]]** — 模型配置参数集
主要包括:
mode: 预测任务类型配置,可选值包括:'binary_classification'、'multiclass_classification'或'regression'
task_level: 预测任务级别,可选值包括:'node'、'edge'或'graph'
return_type: 模型输出格式配置,可选值包括:'probs'、'log_probs'或'raw'
**threshold_config: Optional[ThresholdConfig]** — 阈值控制参数,用于精确控制掩码应用的范围和方式。
threshold_type: 阈值类型配置,包含以下选项:
None: 保持原始状态,保留所有重要性分数
"hard": 采用固定阈值截断策略,将低于指定值的重要性分数置零
"topk": 保留重要性分数最高的k个元素(节点、边或特征),其余置零
"topk_hard": 类似于"topk",但将保留元素的重要性分数统一设为1,实现二值化表示
value: 阈值参数设置
对于threshold_type = "hard",value取值范围为[0,1]
对于threshold_type = "topk"或"topk_hard",value表示保留的元素数量k
阈值参数配置的关键考虑:
k值过小可能导致重要信息丢失
k值过大可能引入噪声信息
存在性能指标发生突变的临界阈值
最优阈值的确定通常需要针对具体应用场景进行实验验证
Explainer调用实现Explainer的调用需要配置以下参数:
x: Union[Tensor, Dict[str, Tensor]], edge_index: Union[Tensor, Dict[Tuple[str, str, str], Tensor]], target: Optional[Tensor] = None, index: Optional[Union[int, Tensor]] = None
各参数说明:
x: 节点特征矩阵(对应data.x或batch.x)
edge_index: 边索引张量(对应data.edge_index或batch.edge_index)
target: 真实标签张量(对应data.y或batch.y)
index: 指定待解释的节点、边或图的索引,可以是单个整数、整数张量或None(表示解释所有输出)
实例分析假设模型将索引为x=10的帖子分类到某个特定subreddit,我们可以分析这一预测的依据,确定哪些特征对该预测结果产生了关键影响。下面展示如何初始化和调用Explainer来实现这一分析:
index = 143 model_explainer = Explainer( model=model, algorithm=GNNExplainer(epochs=50), explanation_type='model', node_mask_type='attributes', model_config=dict( mode='multiclass_classification', task_level='node', return_type='log_probs', ) threshold_config=dict(threshold_type='topk', value=20) )
说明:
选择explanation_type='model'用于分析模型的预测机制
设置node_mask_type='attributes'以研究特征重要性,同时保持node_edge_type=None以专注于节点分析
model_config配置反映了数据集特点:41个类别的多分类问题(mode = 'multiclass_classification'),节点级预测任务(task_level = 'node'),使用对数概率输出(return_type = 'log_probs')
threshold_config设置为保留最重要的20个节点(threshold_type='topk', value=20)
执行分析:
model_explanation = model_explainer( batch.x, batch.edge_index, index=index )
由于设置了explanation_type = 'model',此处无需指定target参数,执行完成后返回Explanation对象,包含完整的解释结果
Explanation类封装了可解释性模块产生的关键分析信息[11]。其结构设计如下:
x: Optional[Tensor] = None, edge_index: Optional[Tensor] = None, edge_attr: Optional[Tensor] = None, y: Optional[Union[Tensor, int, float]] = None, pos: Optional[Tensor] = None, time: Optional[Tensor] = None
核心属性说明:
x: 节点特征矩阵,维度为[num_nodes, num_features]
edge_index: 边索引矩阵,维度为[2, num_edges]
edge_attr: 边特征矩阵,维度为[num_edges, num_edge_features]
y: 真实标签,可以是回归问题的目标值或分类问题的类别标签
pos: 节点空间坐标矩阵,维度为[num_nodes, num_dimension]
time: 时序信息张量,格式根据具体时间特征定义(如,time = [2022, 2023, 2024]表示节点0-2的时间戳)
解释结果分析方法预测行为分析以下代码用于获取模型的初始预测结果:
model.eval() with torch.no_grad(): predictions = model_explainer.get_prediction(batch.x, batch.edge_index)
要分析特定图属性掩码对预测的影响,可使用get_masked_prediction方法。例如,分析掩码节点5对预测的影响:
# 构建掩码矩阵node_mask = torch.ones_like(batch.x) node_mask[5] = 0 # 对节点5进行掩码处理 with torch.no_grad(): masked_predictions = model_explainer.get_masked_prediction(batch.x, batch.edge_index, node_mask=node_mask)
进行预测差异分析:
difference = predictions - masked_predictions mean_difference = difference.mean(dim=0).cpu().numpy() plt.figure(figsize=(10, 6)) plt.plot(mean_difference, color="olive", label="Mean Difference") plt.title('原始预测与掩码预测的差异分析') plt.xlabel('类别') plt.ylabel('Logits差异均值') plt.legend() plt.show()

该图展示了节点5掩码对各类别预测logits的平均影响。正值表示掩码导致该类别的预测概率增加,负值则表示减少。这种可视化有助于理解特定节点对模型决策的影响程度和方向。
除了均值分析,还可以采用其他评估指标,如:
绝对差异
相对差异
均方误差(MSE)
自定义评估指标
关键子图提取为了深入分析图结构中的重要组件,可以使用以下方法:
get_explanation_subgraph():提取对解释具有非零重要性的节点和边,返回一个新的Explanation对象。这有助于隔离对预测最具影响力的图结构组件。
get_complement_subgraph():提取重要性为零的节点和边,返回一个新的Explanation对象。这有助于理解模型认为不重要的图结构部分。
这些方法的主要价值在于能够分离和聚焦于感兴趣的图结构组件,尤其是get_explanation_subgraph()可以有效降低来自无关节点和边的干扰。
关键特征提取以下代码展示了如何提取影响节点预测的关键特征。这段代码改编自visualize_feature_importance方法
node_mask = model_explanation.get('node_mask') if node_mask is None: raise ValueError(f"The attribute 'node_mask' is not available " f"in '{model_explanation.__class__.__name__}' " f"(got {model_explanation.available_explanations})") if node_mask.dim() != 2 or node_mask.size(1) <= 1: raise ValueError(f"Cannot compute feature importance for " f"object-level 'node_mask' " f"(got shape {node_mask.size()})") score = node_mask.sum(dim=0) non_zero_indices = torch.nonzero(score, as_tuple=True)[0] non_zero_scores = score[non_zero_indices] # 特征重要性排序sorted_indices = non_zero_indices[torch.argsort(non_zero_scores, descending=True)] print(sorted_indices)
输出示例:
tensor([555, 474, 43, 210, 446, 158, 516, 273, 417, 531], device='cuda:0')
该实现的关键步骤:
计算每个特征在所有节点上的累积重要性
筛选出具有非零重要性的特征
特征列表的长度由Explainer初始化时的ThresholdConfig决定(示例中为10,因为设置了threshold_config = dict(threshold_type='topk', value=10))
解释结果可视化图结构可视化visualize_graph方法用于直观展示对模型预测有影响的节点和边。该方法的一个重要特性是通过边的不透明度表示其重要性(不透明度越高表示重要性越大)。需要注意的是,使用此方法时Explainer不能设置edge_mask_type=None
方法定义:
visualize_graph(path: Optional[str] = None, backend: Optional[str] = None, node_labels: Optional[List[str]] = None)
参数说明:
path: 可视化结果保存路径
backend: 可视化后端选择,支持graphviz或networkx
node_label: 节点标识符列表
下面通过两个示例展示不同配置下的可视化效果:
示例1:基础特征属性分析配置:node_mask_type='attributes',不设置阈值
visual_explainer_1 = Explainer( model=model, algorithm=GNNExplainer(epochs=50), explanation_type='model', node_mask_type='attributes', edge_mask_type='object', model_config=dict( mode='multiclass_classification', task_level='node', return_type='log_probs', ) ) index = 143 visual_explanation_1 = visual_explainer_1( batch.x, batch.edge_index, index=index )
生成可视化结果:
visual_explanation_1.visualize_graph('visual_graph_1.png', backend="graphviz")

可视化结果展示了与节点143相连的所有节点,这些节点的特征都对节点143的预测产生了影响。图中边的不透明度差异反映了不同连接对预测结果的影响程度。由于未设置阈值,可视化结果包含了较多的节点和边,这有助于全面理解模型的决策过程,但可能不够聚焦。
示例2:重要性筛选分析配置:node_mask_type='attributes',threshold_config=dict(threshold_type='topk', value=10),edge_mask_type=None
本示例通过设置阈值来筛选最重要的节点,提供更聚焦的分析视图:
visual_explainer_2 = Explainer( model=model, algorithm=GNNExplainer(epochs=50), explanation_type='model', node_mask_type='attributes', model_config=dict( mode='multiclass_classification', task_level='node', return_type='log_probs', ), threshold_config=dict(threshold_type='topk', value=10) ) index = 143 visual_explanation_2 = visual_explainer_2( batch.x, batch.edge_index, index=index )# 生成可视化结果visual_explanation_2.visualize_graph('visual_graph_2.png', backend="graphviz")

第二种可视化方法通过限制显示最重要的10个节点,提供了更加精炼的分析视图。边的不透明度变化不太明显,这说明这些保留下来的边对预测结果具有相近的影响程度。这种筛选后的可视化更适合用于识别和分析关键影响因素。
特征重要性可视化visualize_feature_importance方法提供了另一种可视化视角,用于展示影响节点预测的top-k重要特征。使用此方法时,Explainer的初始化配置中不能设置node_mask_type=None,详细实现可参考方法的源代码。
方法定义:
visualize_feature_importance(path: Optional[str] = None, feat_labels: Optional[List[str]] = None, top_k: Optional[int] = None)[source])
参数说明:
path: 可视化结果保存路径
feat_labels: 特征标签列表,用于增强可读性
top_k: 显示的重要特征数量示例调用:
model_explanation.visualize_feature_importance(top_k=10)

该图显示了对节点143预测结果影响最大的前10个特征。这些特征与我们之前通过分析得到的影响特征列表完全一致,提供了直观的重要性排序视图。
解释质量评估为了区分高质量解释和低质量解释,需要建立一套系统的评估机制。这一评估机制对于判断不同解释器(如DummyExplainer与专业解释器)的性能差异尤为重要。系统提供了五种评估指标[12]:
基于真实标签的评估groundtruth_metrics用于评估生成的解释掩码与真实解释掩码之间的一致性。这个指标有助于判断模型识别的重要特征是否与实际数据中的关键特征相符。
评估模型解释与数据真实重要性特征的匹配程度
验证模型的解释能力是否符合领域知识
识别潜在的误解释情况
准确性评估fidelity指标通过比较两种场景下的预测差异来评估解释的质量:
Fid+(保留重要特征):
仅保留解释认定的重要部分
评估这些部分是否足以重现原始预测
Fid-(移除重要特征):
移除解释认定的重要部分
评估这些部分的缺失是否会显著改变预测结果
评估标准:
高质量解释应具有高Fid+值,表明保留的重要特征能够很好地支持原始预测
同时应具有低Fid-值,表明移除这些特征会导致预测结果发生显著变化
综合特征化评分characterization_score将Fid+和Fid-两个指标整合为单一评分,提供更全面的评估视角:
Fid+:评估保留重要特征的效果(目标值接近1)
Fid-:评估移除重要特征的影响(目标值接近0)
权重配置:默认两者权重相等(各0.5),可根据具体应用场景调整
准确性曲线分析fidelity_curve_auc提供了一个更加动态的评估视角,通过测量不同阈值下解释质量的变化来生成完整的性能曲线:
评估机制:
通过调整重要特征的阈值进行多次准确性测量
计算测量结果的曲线下面积(AUC)
分析解释质量随特征数量变化的稳定性
结果解读:
AUC = 1:解释在所有阈值下均保持高准确性
AUC = 0:解释在所有阈值下均表现不佳
AUC值越高表明解释的稳健性越好
相比特征化评分,曲线分析的优势在于能够提供全范围阈值下的性能表现,而不是仅关注特定点的表现。
示例:
from torch_geometric.explain.metric import ( fidelity, characterization_score, fidelity_curve_auc, unfaithfulness ) # 验证解释结果is_valid = model_explanation.validate() # 计算准确性指标fid_pos, fid_neg = fidelity( explainer=metric_explainer, explanation=metric_explanation ) # 计算特征化评分char_score = characterization_score( fid_pos, fid_neg, pos_weight=0.7, # 提高正向影响的权重 neg_weight=0.3 # 降低负向影响的权重 ) # 准确性曲线AUC计算pos_fidelity = torch.tensor([0.9, 0.8, 0.7, 0.6, 0.5]) neg_fidelity = torch.tensor([0.1, 0.2, 0.3, 0.4, 0.5]) # 定义评估阈值点x = torch.tensor([0.1, 0.2, 0.3, 0.4, 0.5]) # 计算AUCauc = fidelity_curve_auc(pos_fidelity, neg_fidelity, x) # 输出评估结果print(f"准确性指标: {fid_pos}, {fid_neg}") print(f"特征化评分: {char_score}") print("准确性曲线AUC:", auc.item())
总结图神经网络的可解释性研究对于提升模型的可信度和实用价值具有重要意义。通过PyTorch Geometric的可解释性模块,我们实现了对复杂模型决策过程的系统分析和理解。
https://avoid.overfit.cn/post/5c548769e84c4bb598f9617de675be8d
作者:J Kwak
