近期,DeepSeek火爆出圈,这款由杭州深度求索人工智能公司倾力打造的AI助手,凭借自然语言处理、机器学习与深度学习、大数据分析等核心技术优势在推理、图像视频分析等多元应用场景中大放异彩,赢得了广泛赞誉。然而,随着用户访问量的不断攀升,云端服务器时常会因超负荷运行而服务中断,影响正常使用。为应对这一难题,本地部署DeepSeek应运而生,不仅能为用户提供更稳定可靠的服务保障,还可进一步提升用户的满意度与信赖度。感兴趣的快看过来~
一、DeepSeek本地部署硬件配置
为满足用户的多样化需求,DeepSeek有提供多种模型版本可选。以下是本人整理出的DeepSeek本地部署硬件配置表,旨在帮助合理选择并配置硬件资源。
模型版本
类型
CPU
GPU 配置
内存
存储
技术要点
1.5B
推理
Intel i5 / Ryzen 5
RTX 3060 (12GB) / Jetson AGX
16GB
256GB
SSD
Int4量化,支持边缘设备部署
训练
Xeon Silver
RTX 3090 (24GB)
32GB
512GB
NVMe
SSD
单卡微调,适用LoRA优化
7B/8B
推理
Xeon Silver
RTX 3090 (24GB) / A10G (24GB)
64GB
1TB NVMe SSD
FP16/Int8量化,单卡加载
训练
Xeon Gold
A100 40GB * 2 (NVLink)
128GB
2TB NVMe RAID
全参微调需多卡并行
14B
推理
Xeon Gold
A100 40GB * 1
64GB
1TB NVMe SSD
Int4量化(显存≈7GB),支持长上下文
训练
EPYC 7xxx
A100 40GB * 4
256GB
4TB NVMe RAID
需张量并行+ZeRO3优化
32B
推理
Xeon Platinum
A100 80GB * 2
128GB
2TB NVMe RAID
FP16模型并行(显存≈64GB/卡)
训练
EPYC 9xxx
H100 80GB * 8
512GB
8TB NVMe RAID
混合并行(流水线+数据并行)
70B
推理
Dual Xeon Platinum
A100 80GB * 4
256GB
4TB NVMe RAID
模型分片+显存优化(PagedAttention)
训练
Multi-Node EPYC
H100 80GB * 16 (跨节点)
1TB+
16TB NVMe集群
需InfiniBand网络+Megatron-LM框架
671B
推理
集群级CPU
H100 80GB * 32 (多节点)
2TB+
32TB分布式存储
动态负载均衡+分片推理
训练
超算集群
H100 80GB * 512 (多机架)
10TB+
PB级存储
需定制化并行策略+高速互联(>800Gbps)
二、DeepSeek本地部署步骤说明
为有效降低DeepSeek本地部署的流程负担,我强烈推荐使用【聪明灵犀】软件,有内置多种DeepSeek模型版本可供灵活选择,帮助更轻松完成部署任务。
1、部署DeepSeek模型
▪ 先下载并安装聪明灵犀软件,启动程序后再点击【一键本地部署deepSeek】下的“立即体验”按钮。

▪ 在跳转页面选择下载模型与安装地址,然后开始模型下载。所需时间取决于网络速度和模型文件大小。

2、与模型互动
▪ 等模型下载好后点击页面上的“立即体验”启动CherryStudio。
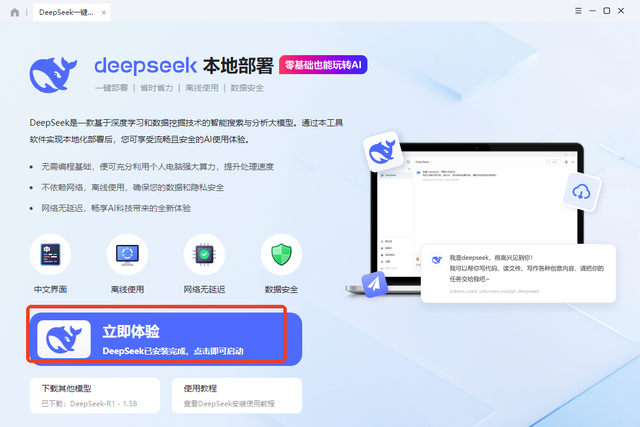
▪ 在新打开界面中找到并点击左下角的“设置”图标。

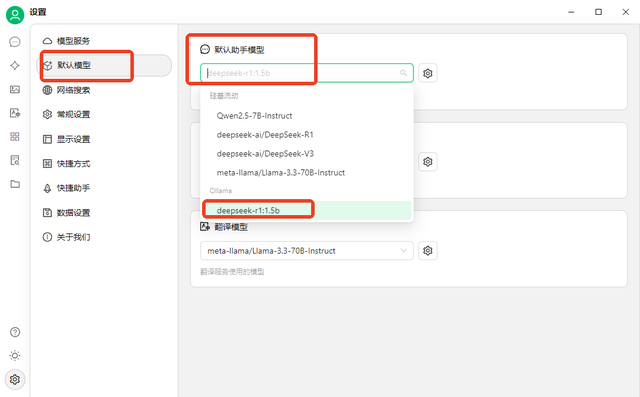
▪ 在弹出的“设置”窗口点击“模型服务”选择“Ollama”,开启该模型后按下底部的“管理”。

▪ 在“管理”窗口中找到刚下载的模型,随后点击右侧的“+”将其添加到Ollama的模型列表中。

▪ 切换到“默认模型 ”选项,将“默认助手模型”设置为刚刚添加的模型。
▪ 返回对话界面,确认当前使用的模型为新添加的模型,如不是,点击进行切换。

▪ 在界面底部输入消息并发送即可开始聊天,还支持网络搜索和上传文档以丰富对话体验。

以上就是本次分享到的全部内容啦,希望能对你有所帮助,喜欢的话记得点赞哟~
