
Hello, 大家好!我是你们的技术小伙伴小米,今天要和大家分享一些关于Kafka日志处理的深入知识。我们将讨论如何查看偏移量为23的消息,以及Kafka日志分段的切分策略。准备好了吗?让我们开始吧!
如何查看偏移量为23的消息?在Kafka中,偏移量是消息的唯一标识,了解如何查找特定偏移量的消息是非常重要的。下面,我们将一步步详细介绍如何通过查询跳跃表ConcurrentSkipListMap,定位到在00000000000000000000.index文件中,然后通过二分法在偏移量索引文件中找到不大于23的最大索引项,即offset 20的那栏,最后从日志分段文件中的物理位置为320开始顺序查找偏移量为23的消息。
1. 查询跳跃表ConcurrentSkipListMap
首先,我们需要查询ConcurrentSkipListMap,这是一种高效的并发跳跃表,用于存储偏移量索引。在Kafka中,索引文件是按段存储的,每个段文件都包含一个偏移量索引和一个日志数据文件。
2. 定位到索引文件00000000000000000000.index
通过查询跳跃表,我们可以定位到特定的索引文件。假设我们定位到了00000000000000000000.index文件,这是Kafka中的第一个索引文件。
3. 使用二分法查找不大于23的最大索引项
在索引文件中,我们使用二分法查找不大于23的最大索引项。假设我们找到的最大索引项是偏移量为20的那栏。

在这个例子中,偏移量20的物理位置是320。
4. 从日志分段文件的物理位置320开始顺序查找
现在,我们知道偏移量20的消息在物理位置320。接下来,我们从物理位置320开始,在日志分段文件中顺序查找偏移量为23的消息。
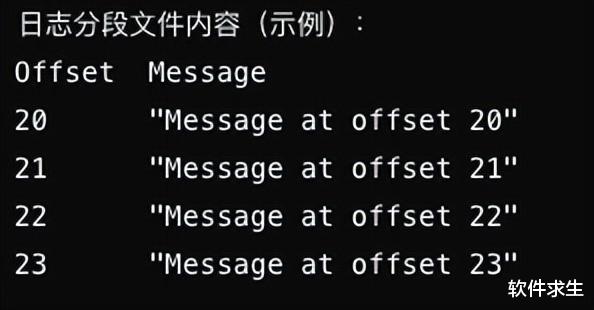
通过顺序查找,我们最终找到了偏移量为23的消息:"Message at offset 23"。
切分文件策略Kafka为了管理日志数据,会根据一定的策略将日志文件进行切分。主要有以下几种策略:
大小分片:当当前日志分段文件的大小超过了broker端参数log.segment.bytes配置的值时,Kafka会创建一个新的日志分段文件。这是为了防止单个日志文件过大,影响性能。
时间分片:当当前日志分段中消息的最大时间戳与系统的时间戳的差值大于log.roll.ms配置的值时,Kafka会切分日志文件。这种策略是为了确保日志文件不会因为时间过长而变得过大。
索引分片:当偏移量或时间戳索引文件大小达到broker端log.index.size.max.bytes配置的值时,Kafka会切分日志文件。这是为了防止索引文件过大,影响查找效率。
偏移分片:当追加的消息的偏移量与当前日志分段的偏移量之间的差值大于Integer.MAX_VALUE时,Kafka会切分日志文件。这是为了避免偏移量溢出。
示例配置
大小分片:当前日志分段文件的大小超过了log.segment.bytes配置的值时,创建一个新的日志分段文件。
时间分片:当前日志分段中消息的最大时间戳与系统的时间戳的差值大于log.roll.ms配置的值时,创建一个新的日志分段文件。
索引分片:偏移量或时间戳索引文件大小达到log.index.size.max.bytes配置的值时,创建一个新的日志分段文件。
偏移分片:追加的消息的偏移量与当前日志分段的偏移量之间的差值大于Integer.MAX_VALUE时,创建一个新的日志分段文件。
实际操作当Kafka检测到任何一个条件满足时,就会触发日志切分,创建一个新的日志分段文件,并更新相关的索引文件。新的日志分段文件会继续接收新的消息,而旧的日志分段文件会被保留,以便后续的读取和处理。
END今天我们详细讨论了如何查看偏移量为23的消息,以及Kafka日志分段的切分策略。理解这些概念对于掌握Kafka的日志管理机制非常重要。希望这篇文章能帮助大家更好地理解和使用Kafka。如果你有任何问题或建议,欢迎在评论区留言,我们下期再见!
祝大家编程愉快!
