
作者|程茜
编辑|心缘
智东西2月25日报道,刚刚,DeepSeek开源周第二弹发布,第一个用于MoE模型训练和推理的开源EP通信库,发布不到一小时,GitHub Star数已上千。
DeepEP是为混合专家(MoE)和专家并行(EP)量身定制的通信库,其提供高吞吐量且低延迟的全对全GPU内核,这些内核也被称为MoE调度与合并。
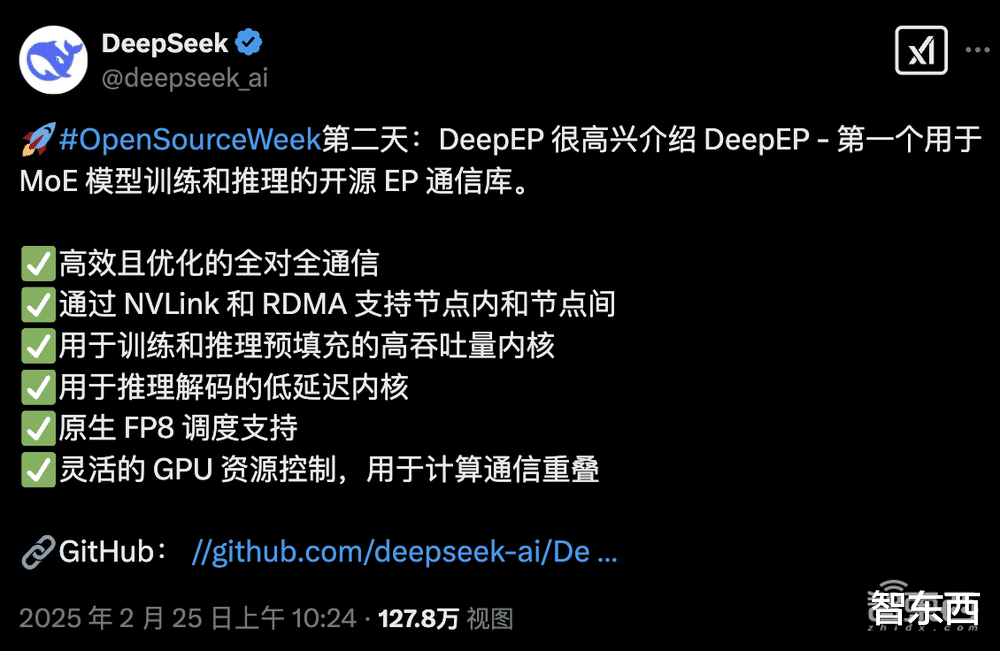
高性能:支持用于节点内和节点间通信的NVLink和RDMA,以及用于非对称域带宽转发的优化内核;
低精度运算:FP8支持;
延迟敏感推理:提供使用纯RDMA的低延迟内核,以最大限度地减少推理解码的延迟;
通信-计算重叠:引入基于钩子的方法,不会占用任何流式多处理器(SM)资源;
自适应路由和流量隔离:支持低延迟内核自适应路由,支持虚拟通道流量隔离。
其中,为了与DeepSeek-V3论文中提出的组限制门控算法(group-limited gating algorithm)保持一致,DeepEP提供了一组针对非对称域带宽转发进行优化的内核,例如将数据从NVLink域转发到RDMA域。这些内核能够实现高吞吐量,使其既适用于训练任务,也适用于推理预填充任务。此外,它们还支持流式多处理器(SM)数量控制。
对于对延迟敏感的推理解码任务,DeepEP包含了一组采用RDMA技术的低延迟内核,以最大程度地减少延迟。该库还引入了一种基于钩子的通信与计算重叠方法,这种方法不会占用任何流式多处理器(SM)资源。
DeepSeek指出,DeepEP的实现可能与DeepSeek-V3论文中略有不同。

GitHub地址:https://github.com/deepseek-ai/DeepEP
具体性能方面:
在H800(NVLink的最大带宽约为160 GB/s)上测试常规内核,每台设备都连接到一块CX7 InfiniBand 400 Gb/s的RDMA网卡(最大带宽约为50 GB/s),并且遵循DeepSeek-V3/R1预训练设置(每批次4096个Tokens,7168个隐藏层单元,前4个组,前8个专家(模型),使用FP8格式进行调度,使用BF16格式进行合并)。

在H800上测试低延迟内核,每台H800都连接到一块CX7 InfiniBand 400 Gb/s的RDMA网卡(最大带宽约为50 GB/s),遵循DeepSeek-V3/R1的典型生产环境设置(每批次128个Tokens,7168个隐藏层单元,前8个专家(模型),采用FP8格式进行调度,采用BF16格式进行合并)。

快速启动要求:

下载并安装NVSHMEM依赖项:

开发:

安装:

网络配置:

接口和示例:

DeepSeek发布的推文一小时浏览量高达12万,评论区下方开发者们直接进入夸夸夸模式:
“DeepSeek在MoE模型方面所实现的优化程度颇高,而MoE模型因其规模和复杂性而向来极具挑战性。DeepEP能够借助像NVLink和RDMA这类尖端硬件,如此精准地处理相关任务,并且还支持FP8格式,这着实令人惊叹。”

“对NVLink和RDMA的支持,为大规模的MoE模型带来了变革性的影响。看来DeepSeek又一次突破了AI基础设施的极限。”
还有人直接做了表情包:“跟着鲸鱼找到鱼。”

从带飞GPU推理速度的FlashMLA到开源EP通信库,DeepSeek开源周第二大重磅发布再次点燃AI圈的热情。本周后续,DeepSeek还将开源三个代码库,或许会与AI算法优化、模型轻量化、应用场景拓展等相关,涵盖多个关键领域。
期待接下来的三场技术盛宴,向开源者们致敬。

边缘人
完全看不懂,但是感觉很牛逼!!!
来自星球
虽然看不懂,但感觉很牛!我测试过好几次用AI解高中数学压轴题,相比其他几款AI工具,DeepSeek确实做的更加详细。
卧龙
辛苦研究出来的,花了大量的钱和时间,搞不懂为何要公开?
vivienne 回复 02-26 04:42
大量的钱和时间?一共投入了也就千把万美元以及一年的时间,不说什么惠及全人类的大话,单单是以本伤人,相当于用千把万的本来毁掉竞争对手前期投入的几百亿美元,并一举击破对手设立的成本门槛,打破其垄断圈钱的目的,这就够了。而且,这是由国家背书的,不说母公司股价大涨这看得见的收益,就说未来国家大力扶持,这在我国就是大部分资本家想都不敢想的好处,梁文峰未来的社会地位甚至政治地位眼见的要超过马云马化腾了。
用户10xxx26 回复 02-26 12:13
我觉得是为了训练,就好像你登录QQ,都会有个图案让你来选择,那个就是训练。开源后,只会让程序越来越聪明,到了一定程度,就可以得到成你所能够想到或想不到的各种利益,或高于利益的很多东西。你有个神童在家里,你怕别人拐走他,就让他在家里待着,过些年神童就成仲永了。
用户10xxx07
别自己最后被超越,究竟国内gpu还不行
用户12xxx31
打压美国
兔飞飞的猫丞丞
同样是人,为何他懂那么多[捂脸哭]
用户10xxx70
擦干净了