
随着所有主流浏览器现已支持 getHTML() 方法,前端开发者有了一个强大的新工具来操作DOM。本文主要探讨 getHTML()的独特优势,特别是在处理Shadow DOM时的卓越表现。
getHTML()与innerHTML的异同getHTML()和 innerHTML 的 getter 在基本功能上相似,都返回元素内部DOM树的HTML表示。但getHTML()的真正优势在于它能够包含Shadow DOM的HTML,而innerHTML则完全忽略Shadow DOM。
getHTML()的高级用法getHTML()接受一个可选的options对象参数,通过适当的选项可以获取完整的HTML,包括Shadow DOM:
const container = document.body;const host = createDiv(123);const root = attachShadowDOM(host);container.append(host);console.log(container.getHTML({ shadowRoots: [root] }));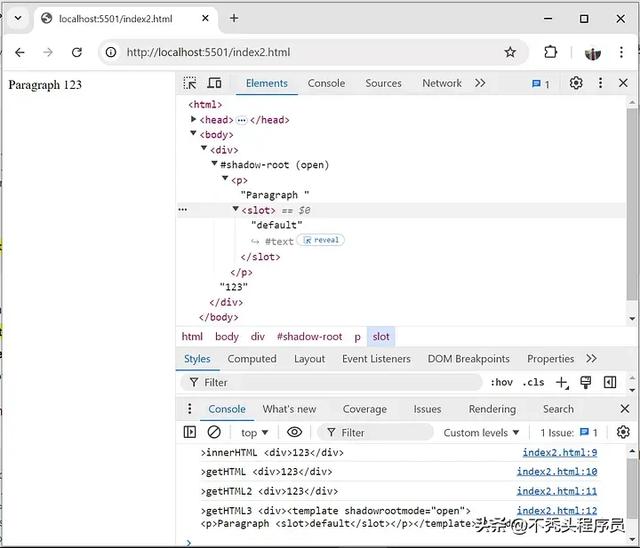
这段代码会返回包含声明式Shadow Root的完整HTML:
<div> <template shadowrootmode="open"> <p>Paragraph <slot>default</slot></p> </template> 123</div>如果在浏览器中将返回的 上面的 HTML 作为新页面打开,则会再现原始 DOM 树:
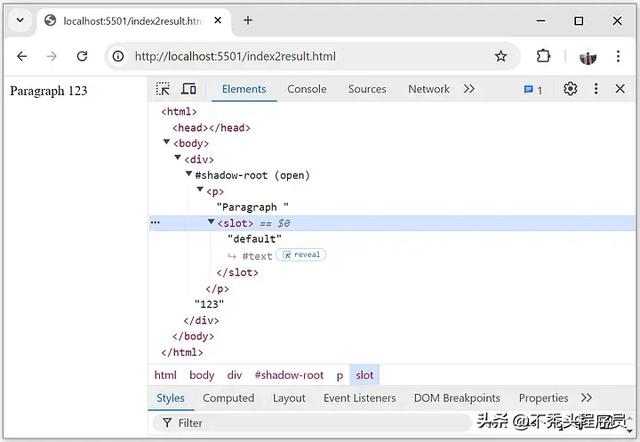
通常,shadow trees和slots是在自定义元素的构造函数中创建的,但为了保持上面和下面示例页面中的代码简单,这里没有创建任何自定义元素。相反,使用了两个辅助函数:
// shared.jsexport function attach(host) { const shadowRoot = host.attachShadow({ mode: 'open' }); shadowRoot.innerHTML = '<p>Paragraph <slot>default</slot></p>'; return shadowRoot;} export function div(n) { const el = document.createElement('div'); if (n) el.innerHTML = n; return el;}div(n)创建一个新的div元素,里面包含数字n,例如<div>123</div>,而attach(host)将HTML为<p>Paragraph <slot>default</slot></p>的shadow树附加到host元素上。为了用常见情况挑战getHTML(),div中的数字123被分配到shadow DOM的slot中。
处理嵌套的Shadow DOM在上面的页面中,getHTML()被调用时使用了所有两个可能的选项:
<script type="module"> import { attach, div } from './shared.js'; const container=document.body; const host=div(123); const root=attach(host); container.append(host); console.log('>innerHTML',container.innerHTML); console.log('>getHTML',container.getHTML()); console.log('>getHTML2',container.getHTML({ serializableShadowRoots: true })); console.log('>getHTML3',container.getHTML({ shadowRoots: [root] }));</script>options对象可以有两个属性:serializableShadowRoots和shadowRoots。当getHTML()在没有options的情况下被调用时,Shadow DOM会被忽略,就像在innerHTML中一样。
如果serializableShadowRoots为true,HTML将包括具有serializable属性设置为true的shadow roots。这样的roots通常不应该存在,因为serializable是与getHTML()一起引入的,默认情况下它是false。
要获取shadow roots的HTML,需要在shadowRoots属性中提供要序列化的shadow roots。当shadow roots是open的时候,可以很容易地递归检索网页中的所有shadow roots。在网页上下文中无法检索closed shadow roots,但可以在浏览器扩展注入的内容脚本中检索。
提供的shadow roots不一定会被序列化。在下一个示例页面中,创建了两个shadow trees。第二个shadow DOM嵌套在第一个中:
<script type="module"> import { attach, div } from './shared.js'; const container=document.body; const host=div(123); const root=attach(host); container.append(host); const host2=div(456); const root2=attach(host2); container.append(host); root.append(host2); console.log('>innerHTML',container.innerHTML); console.log('>getHTML',container.getHTML()); console.log('>getHTML2',container.getHTML({ serializableShadowRoots: true })); console.log('>getHTML3',container.getHTML({ shadowRoots: [root] })); console.log('>getHTML4',container.getHTML({ shadowRoots: [root2] })); console.log('>getHTML5',container.getHTML({ shadowRoots: [root,root2] }));</script>如果第一个shadow DOM不包含在options中,getHTML()不会返回第二个shadow DOM的HTML:要被序列化,shadow roots需要直接连接到要被序列化的DOM。如果省略了父shadow root,嵌套的shadow root也不会被序列化。
getHTML 局限性缺少outerHTML等价物:目前还没有获取包含元素自身在内的HTML的方法。单根元素限制:getHTML()返回的HTML如果没有单一根元素,浏览器可能无法正确解析为声明式Shadow DOM。封闭的Shadow DOM:在网页上下文中无法获取封闭的Shadow DOM,但可以通过浏览器扩展的内容脚本来实现。结语getHTML()为开发者提供了一种强大的方法来处理包含Shadow DOM的复杂DOM结构。虽然它有一些限制,但在处理现代Web组件和复杂UI时,getHTML()的优势是显而易见的。随着Web组件的普及,掌握getHTML()将成为前端开发者的重要技能。
在实际开发中,getHTML()可以用于创建更精确的DOM快照、调试复杂的组件结构,以及在需要保留Shadow DOM结构的情况下序列化页面内容。随着Web标准的不断发展,我们可以期待看到更多类似getHTML()这样的强大API,进一步增强前端开发的能力和灵活性。
