
几个月前,一个朋友聊起了AI助手,说他一度陷入了选择困境。
当他说自己被ChatGPT困扰时,我实在不觉得惊讶,毕竟如今提到AI,大多数人第一反应就是ChatGPT。
但是,他一脸兴奋地告诉我,他最近遇到了一个新助理——DeepSeek,说它在很多方面表现得更好。
于是,我不禁好奇,DeepSeek到底有什么魔力,真的能动摇ChatGPT的地位吗?

不论你是不是技术爱好者,提到AI助手,大概率都听说过ChatGPT。
它已经成为了语音助手、智能回答和日常聊天的代名词。
不过,即便如此,也没能阻止DeepSeek的崛起。

DeepSeek与ChatGPT的最大区别之一就是,它完全开源。
你可能会问,开源到底有什么了不起?
开源意味着,任何人都可以自由查看、使用和修改DeepSeek的代码,这在一定程度上能推动技术的进步和应用的扩展。
更有意思的是,作者姜海在文中提到,DeepSeek在数学、物理和推理问题上表现得尤为出色。
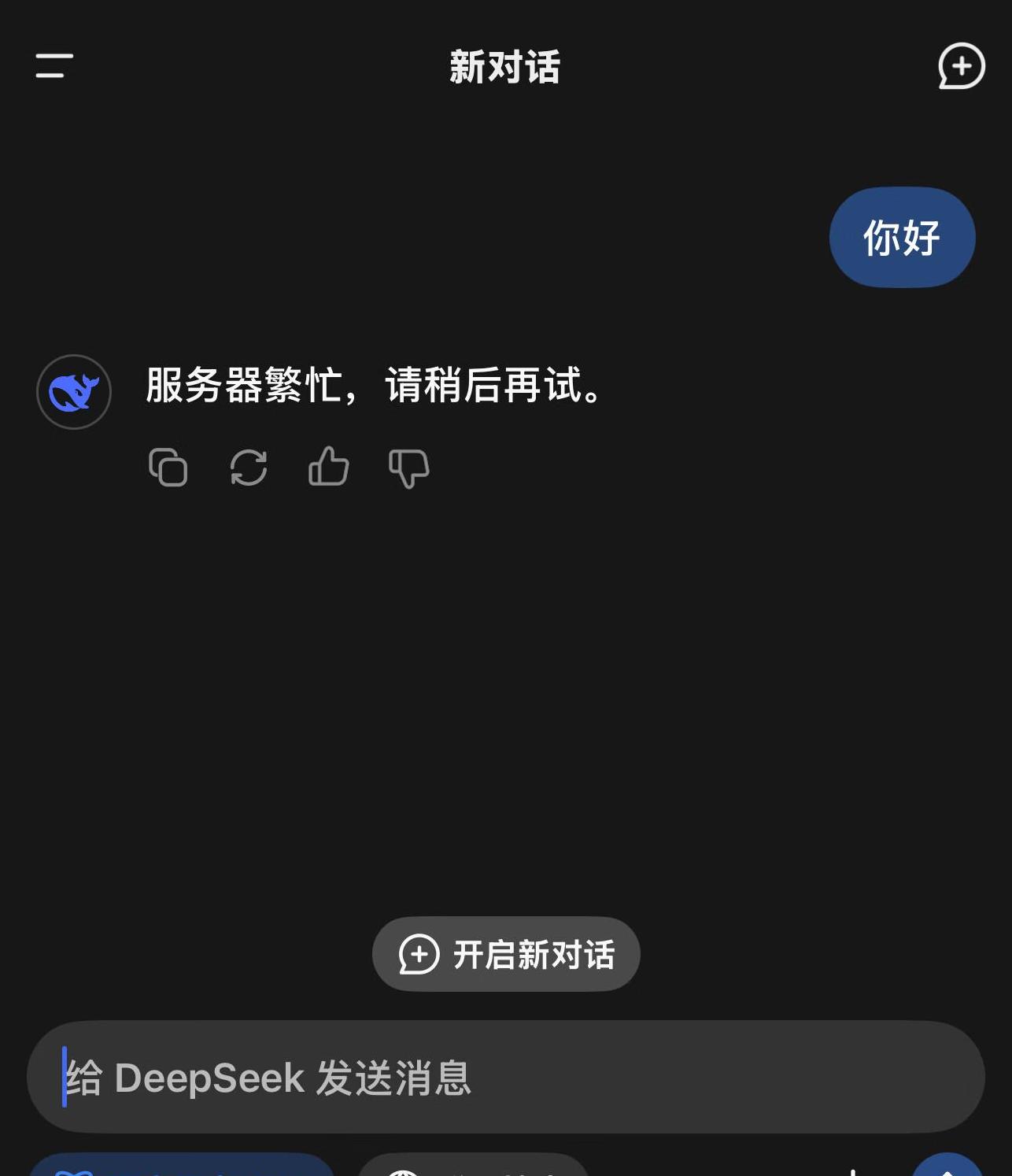
比如,在解答“1.11和1.9谁大?
”这个经典问题时,ChatGPT的表现可能会不尽如人意,而DeepSeek不仅给出了正确答案,甚至详细展示了解题思路。
对于日常面对这类问题的用户来说,这种解决方式无疑提高了使用体验。
成本分析:硬件与训练成本的区别
聊到AI,成本问题避不开。
构建一个高效的AI模型,硬件成本和训练成本是巨大的。
以英伟达为例,它的芯片单张价格高达数万美元。
提出售价不低的高性能B200芯片,可以说是英伟达主导了芯片市场,价格高昂,几乎让所有AI公司对其依赖。
但DeepSeek走了一条不同的路。
它绕过了CUDA核心的限制,使用了全新的技术直接调用GPU的算力,不仅有效降低了成本,还在极短时间内完成了模型训练。
你或许不知道,这种创新使DeepSeek能够使用华为芯片,而训练成本只是ChatGPT的一小部分。
DeepSeek的技术创新
那么,DeepSeek的技术到底新在哪里?
许多人都认为在芯片如此昂贵的情况下,高性能的AI模型训练不可避免地依赖于大量昂贵的芯片。
事实确实如此,正如市场中的大多数AI模型一样,依靠英伟达的高端芯片实现高性能。
但DeepSeek通过绕过CUDA核心限制,直接利用GPU算力,让我们看到了一种新的可能性。
简单来说,就是它不用高端贵重的芯片,也能达到甚至超越现有AI模型的效果。
这样的创新,无疑给那些资源有限的公司提供了一个重大发展契机。
本地化部署DeepSeek R1模型让我们回到朋友的故事。

他不仅兴奋地谈论DeepSeek,更迫不及待地分享如何将DeepSeek R1模型本地化部署。
这听起来可能有点技术性,但实际上并没有那么复杂。
只需登陆Ollama官网,下载安装,然后拉取DeepSeek R1模型,就能在本地的电脑上运行。
不同的显卡会影响模型的运行效果,但大多数家用电脑的显卡都能够支持基本的运行需求。
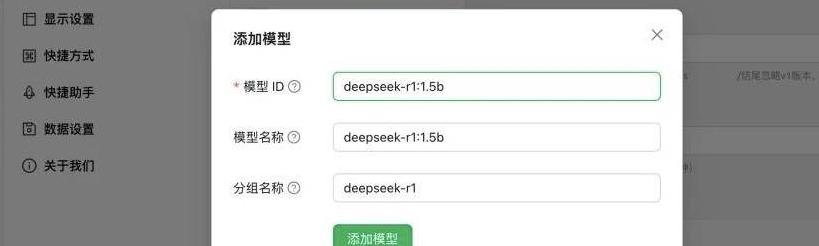
如果你用的是高端显卡,那就能获得更好的体验。
如果你和我一样,对命令行一头雾水,还可以使用现成的GUI进行包装,使操作更加直观友好。
结尾来说,DeepSeek的崛起无疑对现有的AI市场产生了巨大冲击。
不仅仅是在改进技术和降低成本方面,它更是通过开源方式,极大地推动了AI技术的普及和应用。

正如那些敢于挑战现有规则的新技术一样,DeepSeek也在不断地打破我们对AI的认知边界。
想象一下,不远的未来,你的AI助手正在用更高的效率,解决你生活中的各类问题,而这一切只需要最低的成本投入。
你会发现,技术的发展,竟然能如此贴近我们的生活,让复杂的问题变得如此简单。
DeepSeek的出现不仅是一个技术的突破,更是一场让更多人受益的技术革命。

希望这篇文章能激起你对DeepSeek的兴趣,并期待看到你自己动手尝试这个改变AI界的新明星。
