
走进科技实验室,你会看到长长的工作台上摆满了各种复杂的仪器和设备。
坐在电脑前的几位科学家,正眉头紧锁,快速地在键盘上敲击着代码。
这里的一切都充满了探索和思考。
而就在最近,他们迎来了一个激动人心的突破:一种新技术,让原本需要大量数据的AI模型,只需10条数据,就能显著提升性能。
Visual-RFT:增强模型性能的新路径你知道吗?
最近上海交大、上海人工智能实验室和香港中文大学的研究团队共同开发了一个名为Visual-RFT的开源项目。

乍听之下,这个名字可能会有些枯燥,但这个项目的内容可一点都不无聊。
Visual-RFT的特别之处在于,它将一种叫DeepSeek R1的技术迁移到了多模态领域——说白了,就是让这种技术不再局限于一种数据类型,而能够处理包括图像、文本等多种数据类型。
而且,更令人称奇的是,只需要10条数据,就能显著提升这些模型的性能。
这意味着在一些数据极度匮乏的领域,科学家们也能训练出性能超群的AI模型。
少样本学习中的卓越表现看过一些AI学习的资料,你可能会觉得:训练AI模型就像养孩子,需要成千上万的数据来“喂养”它。
Visual-RFT却打破了这种传统观念。
一个有趣的实验来了:研究人员在一个叫LISA的数据集上做了测试,这个数据集对推理能力要求非常高。
结果发现,Visual-RFT在推理任务上的表现,远超其他传统方法。
研究人员甚至还尝试了只用几十个样本进行训练,结果发现Visual-RFT依然表现卓越。
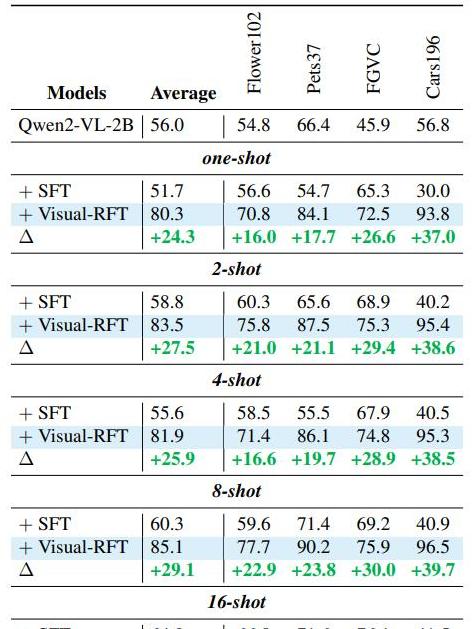
再比如,在花卉图像分类的实验中,研究人员使用了Flower102数据集。
不同于日常见到的花店,这个数据集涵盖了形态各异、颜色斑斓的102种花卉。
Visual-RFT仅用了一次少量样本训练,准确率提高了24.3%。
而传统的监督微调方法,效果反而下降了4.3%。
看到这,你可能会想,这种技术对真实世界中的分析工作会有多大帮助!
比如医学影像分析,很多时候一个病例研究都是在有限样本下进行的,这种新技术无疑打开了更广阔的应用空间。
广泛实验验证的优越性能当然,任何一项新技术都不是仅靠一个实验结果吹嘘自己“无敌”。
Visual-RFT也不例外。
研究小组还在更多的数据集上检验了这个技术的优越性能。
在一个开放词汇对象检测任务上,研究人员分别对COCO和LVIS数据集进行了测试。

COCO数据集包含了各种日常物品的图像,而LVIS更是包括了大量罕见物品的分类。
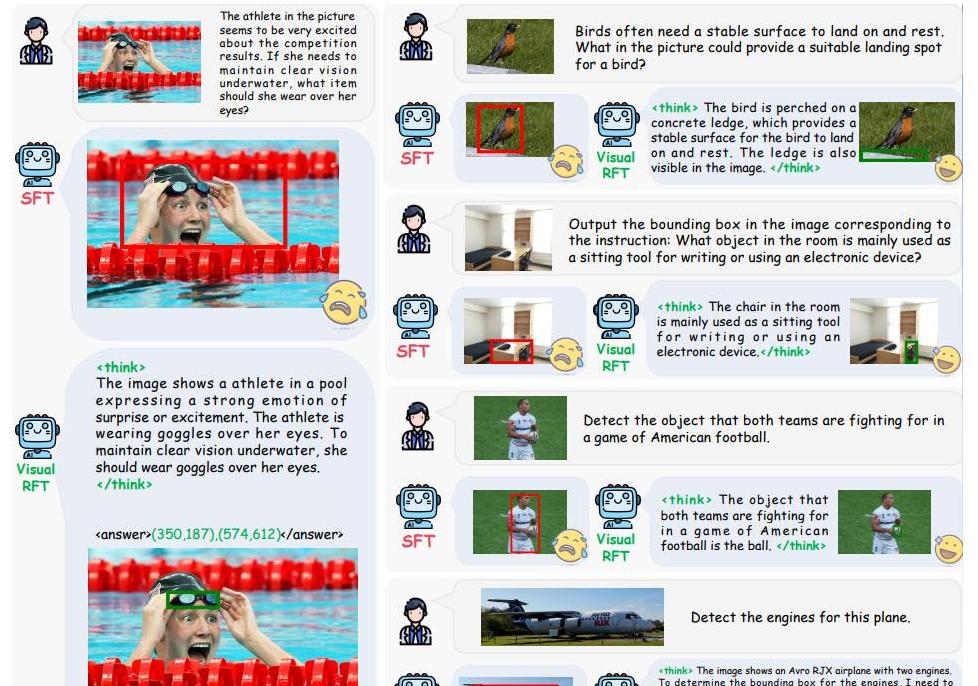
训练后的结果显示,Visual-RFT不仅能有效检测常见物体,在识别那些冷门物体如蛋卷和蒲团等方面,甚至从0达到了1的突破性进展。
不再是简单记住答案,而是真正学会了如何从有限数据中理解和推理出来。
研究员们还选择了一个更具挑战性的动漫风格数据集——MG数据集来验证Visual-RFT的适应性。
面对各种各样的“怪物女孩”图像,Visual-RFT依然能够表现出色。
这不仅证明了模型的强大泛化能力,还展示了出色的推理能力。
与之前的方法相比,Visual-RFT在每一次实验中都大幅领先。

讲了这么多,你可能会好奇:这项技术究竟对我们生活有多大影响?
其实,从科研实验室到实际应用,只有一步之遥。
Visual-RFT这项技术使得AI在数据缺乏时也能学习和提升,这将极大地拓宽其应用领域。
从医学影像分析到自动驾驶,再到智能安防,无处不在它的施展空间。
想象一下,在医疗领域,对某些罕见疾病进行影像分析时,很难获得大量的病例数据。
但有了Visual-RFT,医生们仅需数个病例即可训练出高效的诊断模型,为患者提供更精准、更快速的诊断。

而在自动驾驶领域,这项技术还可以辅助车辆更加智能地识别稀有物品或异常情况,提升出行的安全性。
结尾说到底,科学的进步,总是在人们不断突破自己想象边界的过程中实现的。
Visual-RFT无疑为我们打开了一扇新窗口,让我们看到了一个数据信息缺乏下的广阔世界。
就像那几位在实验室里埋头苦干的科学家一样,他们用实际行动告诉我们,即便在看似不可能的条件下,也能创造出不可思议的成就。
这不禁让人想起一句话:科学无国界,梦想无止境。
对每一位梦想奔跑在科技前沿的研究者来说,Visual-RFT不仅是一种技术,更是一种探索精神的象征,让我们一起期待更多的可能性被打开。

在未来的某一天,也许我们会看到更多这样的技术应用在生活中,帮助我们解决那些看似无法解决的问题。
而这一切的背后,离不开每一个默默努力、勇于创新的科学家。
正如他们所说:“未来,只属于那些相信梦想之美的人。”
