论文旨在建立一个基准,用于评估像LLama 2、GPT-3.5和GPT-4这样的大型语言模型在解决农业领域复杂问题方面的能力。通过评估它们在使用RAG或/和微调时的表现,该研究对LLM在农业领域的优势和局限提供了宝贵的见解。
论文的主要贡献包括:
建立了LLM在使用RAG或微调时的性能基准,因为它们具有不同的收益和成本。已知可以提高大型模型准确率的RAG,在数据上下文相关的实例中非常有效,例如在农场数据的解释中。创建嵌入(数据的向量表示)的初始成本很低,这使得RAG是一个有吸引力的选择。但是,重要的是要考虑输入token大小可能会增加提示大小,而输出标记大小往往更冗长,更难以控制。另一方面,微调提供了精确简洁的输出,比较简洁性。它在特定领域(如提高作物产量预测或根据天气模式优化灌溉时间表)的新技能学习中非常有效。但是,由于需要大量工作在新数据上来微调模型,初始成本很高。此外,微调需要最小的输入token大小,这使其更适合处理大型数据集。两种方法的比较如表23所示。论文也是建立RAG和微调技术在各种LLM应用流程的先驱性步骤,使跨多个行业的创新和协作成为可能。通过最初关注农业,论文已经展示了这些策略如何从问答生成过程开始得到更高效的模型。论文还展示了如何通过利用结构化文档理解以及GPT-4进行问题生成和RAG进行答案生成,为特定行业的数据集生成相关的问题和答案。生成的问题非常特定于它们各自派生的部分,模型能够利用整个文本生成深入而全面的答案。论文表明,分别生成问题和答案会导致高效的token使用,这开启了使用不同模型或方法的可能性为问答对的每个组成部分。论文还提出了一系列指标来正确评估生成的问题相对于原始文档中包含的信息的质量,并展示了多种指标来衡量RAG生成答案的质量。不断完善我们对不同LLM能力的理解,包括RAG和微调,是非常重要的。尽管GPT-4的表现始终优于其他模型,但其微调和推理相关的成本不能被忽略,这是需要考虑的一个重要权衡。总之,虽然RAG和微调都是有效的技术,但它们的适用性将取决于具体的应用、数据集的性质和大小以及模型开发的可用资源。然而,这项工作为进一步研究如何最好地结合这两种方法以及进一步探索行业特定LLM应用的数据集生成流程奠定了基础。作为未来的工作,进一步研究微调模型获得的知识的类型非常重要,在使用LLM开发系统时,对如何改进从文档中提取的结构化信息进行进一步研究非常重要。另一个令人兴奋的方向是如何将来自相同文档的PDF中的结构化信息与图像和图像字幕相结合,以实现多模态微调机会。

表23:RAG与微调的见解
二、论文的简单介绍2.1 论文背景随着LLM研究的继续,确定其局限性并解决开发更全面人工通用智能(AGI)系统的挑战至关重要。此外,机器学习社区必须摆脱传统的基准数据集,并以更接近人类认知能力评估的方式评估LLM。
各行业对人工智能驾驶员(AI copilots)的采用正在彻底改变企业的运营和环境交互方式。这些由LLM提供支持的AI驾驶员在数据处理和决策过程中提供了宝贵的帮助。例如:
在医疗保健领域,AI驾驶员被利用来预测患者风险和改善诊断准确性。在制造业,它们帮助提高运营效率,减少停机时间并提高产品质量(在金融领域,AI驾驶员帮助欺诈检测、风险管理和投资决策通过利用AI驾驶员的力量,行业可以推动创新、优化绩效并获得竞争优势。
尽管有这些进步,由于缺乏专门的训练数据,AI在农业等特定领域的应用仍然有限。虽然AI已被用于从农业中的卫星图像和传感器数据中获得洞察力,但这项技术仍在缓慢地被农民采用。虽然GPT-4和Bing是查找信息的强大工具,但它们可能不能为农民提供最佳解决方案,这些农民对他们的作物和牲畜有非常具体的问题。这些问题通常需要对当地条件、特定品种和最新数据的知识,这些数据可能无法通过一般搜索引擎轻松获得。例如,表1比较了GPT-4和农艺专家对同一查询的回答,该查询针对三个不同的美国州提出。虽然专家会根据各州特定的气候和农业传统提供情境化的答案,但LLM提供一个通用的答案,尽管正确,但对于每个州来说都不像专家答案那样精确。

表1:GPT-4、Bing Chat和专家对示例查询(“植树和灌木最佳时间是什么时候?”)的回答比较,考虑了三个位置(阿肯色州、康涅狄格州和佐治亚州)。GPT-4无法结合位置特定知识,在所有情况下都提供相同的答案,没有考虑地理特殊性。在搜索引擎的增强下,Bing Chat在适应每个位置的答案方面做得更好,但专家的答案仍然更精确
2.2 论文的方案论文引入了一个新焦点:为需要特定上下文和自适应响应的行业(如农业)创建AI驾驶员。论文提出了一个全面的LLM流程,以生成高质量的行业特定问题和答案。这种方法涉及一个系统的过程,包括识别和收集广泛涵盖农业主题的相关文档。然后,这些文档被清理和结构化,以便利用基本GPT模型生成有意义的问题答案对。随后根据质量对生成的对进行评估和过滤。论文的目标是为一个具体的行业创造有价值的知识资源,以农业为案例研究,最后为推进这个关键领域做出贡献。
所提出的流程旨在为行业中的专业人员和利益相关者生成定制的行业特定的问题和答案,其中驾驶员的答案预计将以相关的行业特定因素为基础。在农业研究案例中,论文的目标是生成与地理相关的答案。为此,论文的起点是一个农业数据集,它被馈送到三个主要组件:问答生成、检索增强生成(RAG)和微调过程。问答生成根据农业数据集中的可用信息创建问题答案对,而RAG将其用作知识来源。然后对生成的数据进行细化并用于微调几个模型,同时使用所提出的指标组合来评估其质量。通过这种全面方法,论文旨在利用LLM的力量造福农业行业及其利益相关者。

图1:方法流程。收集特定领域的数据集,并提取文档的内容和结构。然后将这些信息馈送到问答生成步骤。合成的问题-答案对用于微调LLM。使用基于GPT-4的指标评估RAG的模型,无论是否使用RAG
本文提出的方法论围绕一个旨在生成和评估问题-答案对以构建特定领域助手的流水线展开:
流水线始于数据采集。最初的焦点是收集与行业领域相关的多样化且经过精心策划的数据集。这包括从各种高质量仓库获取数据,如政府机构、科学知识数据库以及需要时的专有数据。在完成数据采集后,流水线继续提取所收集文档的信息。这一步骤至关重要,因为它涉及解析复杂且非结构化的PDF文件,以恢复其中的内容和结构。流水线的下一个组件是问题和答案的生成。这里的目标是生成与提取文本内容准确反映的上下文相关且高质量的问题。该方法采用一个框架来控制输入和输出的结构组成,从而增强语言模型的整体响应生成效果。随后,流水线为制定的问题生成答案。这里采用的方法利用了检索增强生成(RAG),结合了检索和生成机制的力量,以创建高质量的答案。最后,流水线通过问题-答案对对模型进行微调。数据采集
流水线的初始焦点是收集一个各方面经过精心策划的数据集,其中包含对行业感兴趣的信息。对于这一步骤,寻找包含感兴趣主题的高质量、权威信息的数据源。例如,在农业领域,这包括农业和环境政府机构、科学知识仓库以及农学考试数据库。还重要的是,提取的信息要与将提供给模型的基础相一致。例如,在农业数据的情况下,获取了地理特定的指南和程序,即在文档之间共享位置。
在定义了权威来源之后,Web抓取工具开始收集所需的数据。使用了Web抓取框架,包括Scrapy和BeautifulSoup,来解析网站,发现所有可用的文档并下载相关文件。
PDF信息提取
从收集的文档中提取信息和文本结构对于后续步骤的质量至关重要。然而,这是一项具有挑战性的任务,因为PDF的主要目的是在不同系统上准确显示文档,而不是方便信息提取。PDF文件的底层结构与文档的逻辑结构(即部分、子部分和相关内容)不相匹配。此外,由于文档来自各种来源,观察到它们的布局和格式复杂且缺乏标准化,通常呈现表格、图像、侧边栏和页脚的混合。在图2中展示了数据集中PDF文件的示例。
考虑到这一点,流水线在这一步中的主要目标是解决处理来自各种格式化PDF文档的数据时固有的复杂性。这通过利用强大的文本提取工具和使用先进的自然语言处理技术的机器学习算法来实现。重点不仅在于恢复每个文件的内容,还在于其结构。对文档的兴趣之一是发现各个部分和子部分,解析表格和图表中呈现的信息,识别文档内的交叉引用,并将图像与其标题和描述相关联。通过检索文档的组织,我们可以轻松地对信息进行分组,在表格中推理出数值数据,并为Q&A生成步骤提供更一致的文本片段。从文档中提取所有可用信息,形成良好组织的句子,也是非常重要的。
有许多在线工具可从PDF中提取信息(PDF2Text;PyPDF)。然而,其中许多缺乏以结构化方式检索内容的能力。例如,pdf2text是一个开源的Python库,提供了迭代PDF页面并恢复文本信息的方法。在清单1中提供了pdf2text对图2中文档的输出。该库能够恢复文本信息,但在检索的数据中会丢失表示部分或子部分开始的标记,这妨碍了我们推理文档结构的能力。表格和图表的标题也在转换中丢失,但有时包含了对文档理解至关重要的信息。
考虑到这一点,论文采用了GROBID(GeneRation Of BIbliographic Data),这是一个专门为从科学文献中的PDF格式中提取和处理数据而定制的机器学习库。其目标是将非结构化的PDF数据转换为TEI(Text Encoding Initiative)格式,从而有效管理大量文件。GROBID是在大量科学文章语料库上训练的,能够识别各种文档元素并提取相关的文献数据。我们在清单2中演示了GROBID对图2文档的输出,展示了其能力。
从GROBID生成的TEI文件中,提取了TEI文件的一部分,其中包括文档元数据(标题、作者、摘要)、章节、表格、图表引用、参考文献和内容本身。关键是,该阶段强调了文本的结构与其内容同样重要的信念。最终目标是将TEI文件转换为更易管理的JSON文件,不仅保留内容,还保留原始PDF的结构。这种方法确保全面理解科学文献的内容和背景,使其成为各种领域或行业的宝贵资源。

代码3:在问题生成期间从文档中识别支持上下文(即提到的位置和农艺主题列表)的提示
问题生成
这一部分的初步焦点是在从提取的文本生成问题时管理自然语言的内在复杂性和变异性。目标是生成上下文相关且高质量的问题,准确反映提取文本的内容。为此,采用了Guidance框架,其主要优势在于能够在输入和输出的结构组成上提供无与伦比的控制,从而增强语言模型的整体响应生成效果。这种控制程度导致的输出不仅更为精确,而且表现出增强的一致性和上下文相关性。该框架将生成、提示和逻辑控制融合为一个单一、统一的过程,紧密与语言模型文本处理的固有机制相似。此外,Guidance独特的功能,通过上下文特定提示引导语言模型的方向,有助于在生成文本中实现更高水平的语义相关性。在我们的情况下,这确保问题将在从JSON文件中提取的上下文中携带语义相关性。
首先,通过明确从文本中添加支持标签来增强可用文档的内容和结构。制定了提示,以提取文档每个部分中提到的位置和农学主题的列表(例如,如果该部分涉及作物、牲畜或疾病),如清单3所示,并要求LLM模型根据从JSON文件中提取的数据回答它们。目的是利用额外的信息,包括位置和提到的主题,来打地基于生成过程,增强问题的相关性并引导模型涵盖各种主题和挑战。
一旦获得支持上下文和章节内容,我们促使LLM基于它们生成一组问题。我们在清单4中提供了问题生成提示的示例。提示包括一个系统前导,引导LLM制定与文档内容相关的工业主题的评估问题。而用户部分提供了期望问题类型的少量示例,以及用于生成的内容和支持上下文。通过这个设置,LLM为文档的每个部分生成一组5到15个问题。
答案生成
采用检索增强生成(RAG),这是一种创新方法,结合了检索和生成机制的力量,以生成高质量的答案。在处理大型和复杂数据集时,RAG特别有用,因为它可以有效地恢复与查询相关的信息并用于增强生成过程。
RAG流水线始于从数据集中检索给定问题的最相关文档或段落。检索系统采用BM25、密集检索等技术,检索到的文档作为后续生成阶段的知识源。一旦确定了相关段落,生成组件开始发挥作用。LLM将问题和检索到的信息作为输入,并生成一个上下文适当的答案。生成过程由检索文档提供的上下文引导,确保生成的问答对准确、相关且信息丰富。具体而言,生成过程分为三个步骤:
嵌入生成和索引构建:使用从数据集中提取的PDF文档中的文本块计算嵌入,使用句子转换器。然后,使用Facebook AI Similarity Search(FAISS),这是一个用于有效索引和相似度搜索的向量库,创建嵌入的数据库。检索:给定一个输入问题,计算其嵌入并从FAISS数据库中检索相关的文本块。这是通过FAISS检索工具similarity_search_with_score完成的,该工具允许执行相似性搜索,返回与问题相关的顶级文本片段。答案生成:将问题和检索到的文本块作为输入,使用LLM模型合成答案。具体而言,将从FAISS数据库中检索的信息作为上下文提供给GPT-4,以在自定义提示中生成领域特定的答案。答案与相关的问题一起以JSON文件的形式正确格式化,形成问答对。
代码4:针对作物相关文档的问题生成提示示例。在提示模型时,我们用上一步中检索到的支持信息替换{{context}}标记,并分别用文档来源、标题和章节内容替换{{source}}、{{title}}、{{section}}标记。在我们的例子中,提示直接与农业相关,但在其他场景中应该用特定领域知识进行调整
微调
语言模型的开发涉及数据集的创建和具有不同容量的模型的训练。在这种情况下,一个由问题和相应答案组成的数据集是从Llama2-13b-chat用RAG生成的。训练了几个不同大小的基本模型,包括Open-Llama-3b、Llama2-7b和Llama2-13b。这些模型被设计为基于问题提示预测答案token,同时屏蔽提示标记以确保模型不会预测它们。
为了优化这些模型的性能,使用了8个H100 GPU和PyTorch的完全分片数据并行(FSDP)进行了微调过程。FSDP允许参数、优化器状态和渐变的分片,有效地减少了训练期间的内存需求。模型中的每个变压器模块都充当FSDP模块,具有激活检查点。训练过程包括向每个GPU馈送4个样本的微批量并在4个微批量上累积渐变,从而在每个训练步骤中获得128个样本的有效批大小。 训练进行了4个epochs,采用BFloat16的自动混合精度(AMP),Adam优化器,2e-5的基础学习速率和余弦学习速率调度器,线性warmup占总步数的4%。 在整个训练过程中使用了FastCha训练脚本与flash-attention monkeypatching。
最后,还在这个设置中微调了GPT-4。由于其更大、更昂贵,目标是评估与其基础训练相比,该模型是否会从额外的知识中受益。由于其复杂性和可用数据量,使用低秩适应(LoRA)进行了微调过程。这种技术为适应参数繁重的模型提供了一种高效的方法,与传统的重新训练相比,它需要更少的内存和计算资源。通过调谐体系结构中的注意力模块中的一组已减少的参数,它在不损失基础训练期间获得的知识的情况下,从新数据中嵌入特定领域的知识。优化在4个epochs上完成,批量大小为256个样本,基础学习速率为1e-4,随着训练的进行而衰减。微调在总运行时间为1.5天的七个节点上进行,每个节点有八个A100 GPU.
2.3 论文的效果在本文中,论文对农业领域LLM的理解做出了几点值得注意的贡献。这些贡献可以列举如下:
全面评估LLM:广泛评估了大型语言模型,包括LlaMa2-13B、GPT-4和Vicuna,以回答与农业相关的问题。这是使用主要农产品生产国的基准数据集完成的。评估包括完整的微调和RAG流程,每个流程都有一套自己的指标。这些评估的发现为这些模型在农业背景下的性能提供了关键的基准理解。此外,论文进行评估以展示现有LM编码的知识上存在的空间转移影响,以及空间定义的微调提供的改进。在论文分析中,GPT-4始终优于其他模型,但是与其微调和推理相关的成本需要考虑在内。检索技术和微调的影响:论文研究了检索技术和微调对LLM性能的影响。该研究表明,RAG和微调都是提高LLM性能的有效技术。RAG在数据上下文相关的实例中被证明非常有效,例如在农场数据的解释中,同时也导致比基本模型更简洁的响应。另一方面,发现微调在教模型农业领域特定的新技能方面很有用,并提供更精确简洁的响应。但是,进行大量工作以在新数据上微调模型的高昂初始成本是一个重要的考虑因素。LLM在不同行业中的潜在用途的影响:这项研究是建立RAG和微调技术在LLM中的应用流程的开创性步骤,促进跨多个行业的创新和协作。通过最初关注农业,论文展示了这些策略如何从问答生成过程开始导致更高效的模型。从这项研究中获得的见解可以应用于其他部门,可能导致开发更有效的AI模型用于各种应用。例如,一个潜在的应用可能是为不同的行业开发AI驾驶员,在这种情况下,能够对用户查询提供准确、相关和简洁的响应至关重要。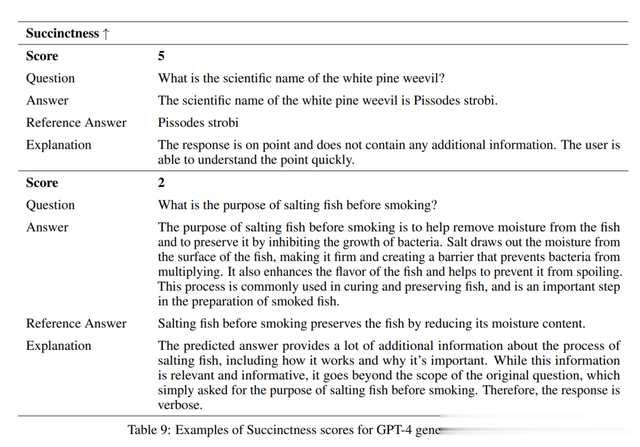
表9:GPT-4生成答案的简洁性得分示例

表18:基本模型和微调模型(无论是否使用RAG)的准确率

表19:基本模型和微调模型(无论是否使用RAG)的简洁性,范围从1(冗长)到5(简洁)
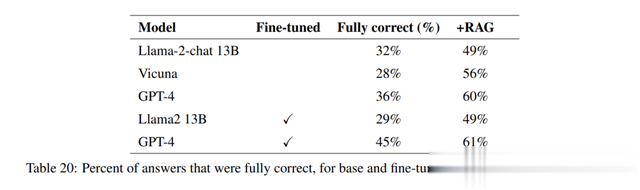
表20:基本模型和微调模型(无论是否使用RAG)完全正确的答案百分比

表21:不同模型对参考问题提供答案的比较

表22:基本模型和微调模型(无论是否使用RAG)的准确率
论文标题:RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
论文链接:https://arxiv.org/abs/2401.08406
