了解Cassandra数据建模概念的黑暗面,并学习如何用更简单的架构来解决这个问题。
Apache Cassandra已经成为软件架构师和工程师非常流行的数据库。我们中的许多人相信它是用于我们的应用程序的数据,目前有成千上万的部署运行这个有信誉的NoSQL数据库。毫无疑问,卡桑德拉完全是值得的荣誉和声誉。数据库简单地具有它所期望的:无限的可扩展性和快速写入操作的高可用性。

这两个重要的功能帮助Cassandra迅速提高了知名度,解决了关系数据库无法解决的问题和用例。这些问题和用例需要横向扩展性,高可用性,容错性和24/7可操作性,而不需要停机。经典的关系数据库不能满足所有的要求 - 现在不能(除了分布式关系数据库,如谷歌Spanner或CockroachDB)。
但是,可扩展性和高可用性不是免费给我们的。我们这些被简单的设计原则和关系型数据库所破坏的人,被迫学习如何正确使用Cassandra,如何正确地进行数据建模,以及如何在没有高级SQL功能的情况下生活。
在这篇文章中,我将阐述Cassandra的数据建模概念的黑暗面。这是整个Cassandra架构的一个支柱,我会建议如何通过依靠现代数据库来使架构变得更简单,这些数据库可以为我们提供Cassandra所具备的一切 - 甚至更多。
数据建模完成正确当然,掌握Cassandra中的数据建模概念需要时间 - 考虑到这个主题有大量的资源,这并不是什么大问题。这个概念是基于非规范化策略的,它要求我们预先猜测所有将针对数据库运行的查询。坦率地说,这也是可行的。只要提出一个查询列表,组成为查询优化的Cassandra表,并将应用程序投入生产。
这种设计被称为查询驱动的方法,这意味着我们的应用程序开发是由我们的查询驱动。如果不了解我们的查询的内容,我们就不能再开发应用程序。随着这个数据教条,Ad hoc变得更加棘手,但是我们在Cassandra部署中进行快速廉价的写入。
例如,让我们假设我们的应用程序跟踪供应商生产的所有汽车,并为每个供应商提供生产力的见解。在关系世界里,我们可能会想出一个这样的数据模型:
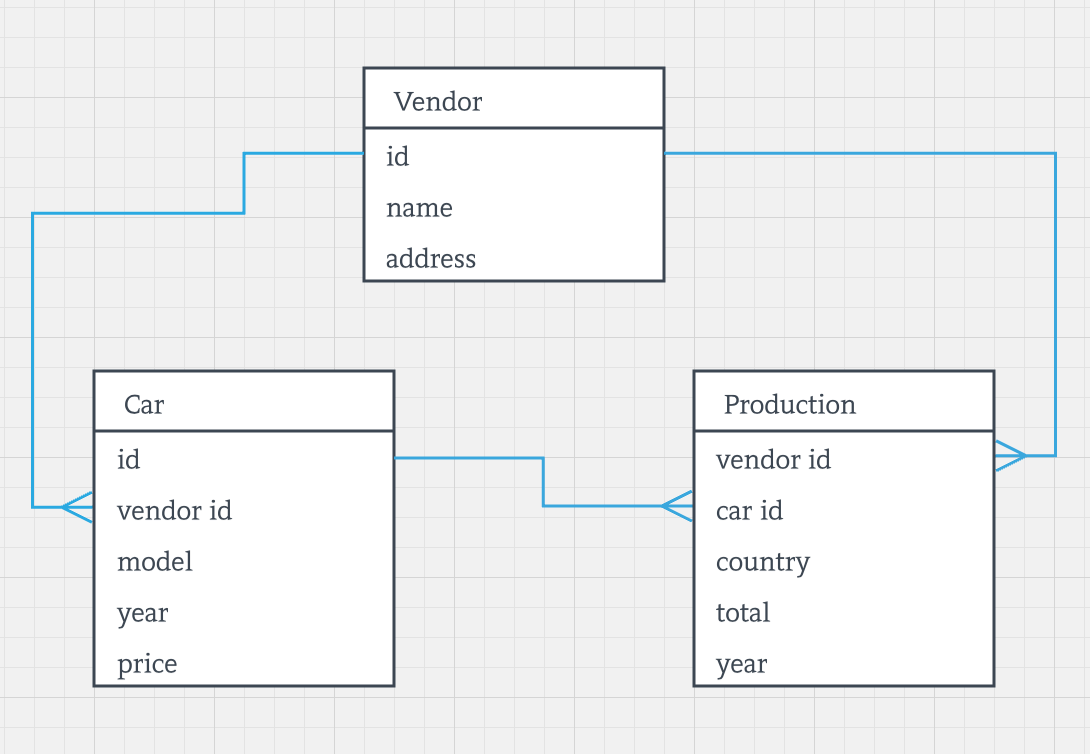
从技术上讲,没有什么能够阻止我们在Cassandra中使用相同的模型。但是从架构的角度来看,这个模型是不可行的,因为Cassandra无法加入存储在不同表格中的数据 - 我们当然希望将Cars,Vendors和Production的数据混合到一个结果集中。如果我们想要实现这一目标,那么是时候关闭关系模型,并利用非规范化策略。
该策略指导我们提出应用程序所需的查询(操作)列表,然后围绕它们设计模型。在实践中,没有什么比这更简单的了。让我来说明那些不熟悉它或Cassandra的人的非规范化策略。
想象一下,应用程序必须支持这个查询:
Q1:在特定的时间范围内获得供应商生产的汽车模型(最新的第一个)。
为了在Cassandra中高效地运行查询,我们将创建一个表格(见下文)来分区数据,并按照聚类关键字vendor_name排列数据:production_yearcar_model
CREATE TABLE cars_by_vendor_year_model ( vendor_name text, production_year int, car_model text, total int, PRIMARY KEY ((vendor_name), production_year, car_model)) WITH CLUSTERING ORDER BY (production_year DESC, car_model ASC);一旦表填充完毕,我们可以运行一个与最初定义的Q1相对应的Cassandra查询(见下文):
select car_model, production_year, total from cars_by_vendor_year_model where vendor_name = 'Ford Motors'
最重要的是,表格适合这些操作:
获取供应商生产的汽车模型:
select * from cars_by_vendor_year_model where vendor_name = 'Ford Motors'获取特定年份生产的特定车型的汽车数量:
select * where vendor_name = 'Ford Motors' and production_year = 2016 and car_model = 'Explorer'接下来,我们正在为计划由应用程序支持的每个查询执行此练习,确保所有表都已就位,并将我们的应用程序投入生产。工作已经完成,我们期待在业务季度结束时获得奖金!
缺点好的,所以也许有可能奖金不会落在我们的口袋里。
基于Cassandra的体系结构的一个缺点通常在应用程序实际处于生产阶段时出现。这种情况通常发生在有人通过我们的隔间停止时,并通过快速添加新操作来要求增强应用程序。这就是卡桑德拉不足的地方。
如果数据模型是关系型的,那么我们将准备一个SQL查询,创建一个索引(如果需要的话),并将补丁推入生产环境。卡桑德拉并不那么简单。如果查询不能被普遍执行,或者由于定义的架构不能被有效执行,那么我们将需要创建一个全新的Cassandra表,设置主键和集群键以满足查询的特定性,并从现有的表格。
让我们回到已经被数百万用户使用的Cars and Vendors应用程序,并尝试在其中完成以下操作(查询):
Q2:获取供应商生产的特定型号的汽车数量。
在考虑了一会之后,我们可以得出结论:可以根据cars_by_vendor_year_model之前创建的表格来创建一个Cassandra查询。那么,查询就绪,我们尝试运行它:
select production_year, total from cars_by_vendor_year_model where vendor_name = 'Ford Motors' and car_model = 'Edge'但是,查询失败,例外情况如下:
InvalidRequest: code=2200 [Invalid query] message="PRIMARY KEY column "car_model" cannot be restricted (preceding column "production_year" is not restricted)"例外只是提醒我们,在过滤数据之前car_model,我们必须指定一个生产年份!但今年是未知的,我们必须为了Q2而创建一个不同的表格:
CREATE TABLE cars_by_vendor_model ( vendor_name text, car_model text, production_year int, total int, PRIMARY KEY ((vendor_name), car_model, production_year));最后,我们可以成功执行下面的对应于Q2的查询:
select production_year, total from cars_by_vendor_model where vendor_name = 'Ford Motors' and car_model = 'Edge'现在,退一步,看看两者的结构cars_by_vendor_year_model和cars_by_vendor_model,并告诉我,你有多少差异能够发现。那么,应该只是一对夫妻,而主要的一个就是在安排集群钥匙!所以,只是为了第二季度,我们不得不:
创建一个复制以前存在的数据的新表cars_by_vendor_year_model。
注意在我们的应用程序中嵌入批处理更新的两个表的原子更新。
复杂的应用程序体系结构。
这个故事往往会一再发生,除非应用程序停止发展,我们倾倒它。实际上,至少在头几年这是不太可能的,这意味着我们应该戴上头盔,准备好在无限的建筑并发症上轰炸我们的头脑。有没有办法避免这种情况?绝对。你能用一些魔术卡桑德拉能力吗?当然不。
Apache点燃救援?使用JOINs的SQL查询并不便宜,特别是如果关系数据库在一台机器上运行,并且由于工作负载的增加而开始“窒息”。这就是为什么我们许多人转向Cassandra,忍受它的数据建模技术的缺点,这通常会导致复杂的架构。
分布式商店,数据库和平台的市场正在经历巨大的增长。找到一个可以扩展的数据库并且和Cassandra一样可用,这也是可以做到的,但是这也可以让我们建立一个基于关系模型的应用程序。
看看其他一些Apache软件基金会(ASF)项目,我们遇到了Apache Ignite。这是一个以内存为中心的数据存储,用作分布式缓存或具有内置SQL,键值和计算API的数据库。
Ignite仍然在其较老的ASF队友(Cassandra)的阴影下。然而,我经常碰到那些从可伸缩性,高可用性和持久性观点来看这些数据库非常相似的人。另外,许多人确认Ignite在涉及到SQL,分布式事务和内存存储时是无与伦比的。而且,那些信任Cassandra生产环境的人试图通过使用Ignite作为缓存层来加快速度 - 通常是Cassandra用Ignite自己的持久性替代阶段的中间步骤。
您是否像加入Ignite社区时那样感兴趣?然后系好安全带并等待下一篇文章,这将打破如何使用Ignite构建更简单的基于关系模型的体系结构。我将通过利用亲和力搭配和分区概念以及高效的搭配SQL来构建Cars和Vendors应用程序的示例JOIN。和更多。对于那些不耐烦,想要自己解决这个问题的人,我建议先看一下Ignite的主要功能,首先看Ignite essentials的第一部分和第二部分。
