AI大模型领域正迎来新一轮“降价潮”。2月26日,国内AI企业DeepSeek宣布,每日00:30至08:30的夜间时段,其开放平台的API调用价格大幅下调:DeepSeek-V3降至原价50%,DeepSeek-R1更是低至25%。这一错峰优惠策略旨在鼓励用户利用空闲时段降低使用成本,同时提升服务流畅度。

此次降价背后,是AI大模型厂商在算法优化与算力成本控制上的激烈竞争。例如,字节跳动旗下豆包大模型去年已降价85%,阿里云通义千问视觉模型价格最低至0.0015元/千tokens。与此同时,英伟达的加入为行业注入新变量。其开源的首个Blackwell架构优化方案DeepSeek-R1-FP4,使单token推理成本降低20倍,性能却提升25倍,B200芯片的推理吞吐量高达每秒21,088 token,较H100实现跨越式突破。
技术迭代与成本压缩的双重推动下,行业格局加速重构。光大证券分析称,DeepSeek的开源降本方法论可能引发全行业训练和推理成本下降,推动AI应用普及。长江证券则指出,开源生态的竞争正倒逼海外厂商加速研发,例如OpenAI已允许免费用户无限制使用GPT-5.0基础功能。
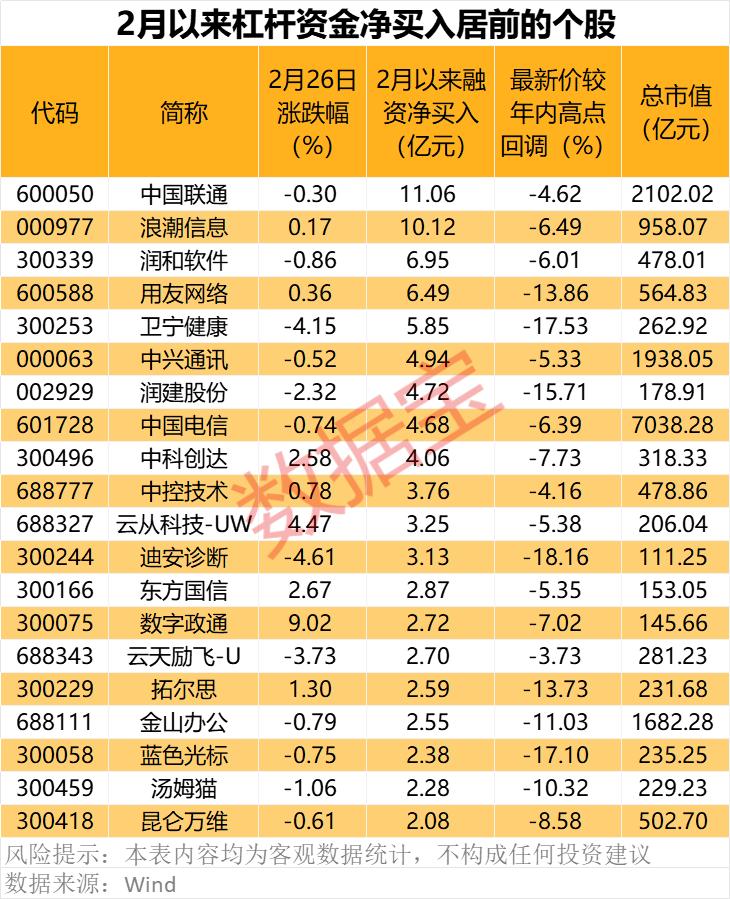
资本市场对此反应热烈。2月26日,A股大模型概念股普遍上涨,首都在线单日涨幅超13%,中国联通、浪潮信息等企业获杠杆资金抢筹,本月净买入额超90亿元。值得注意的是,部分企业已通过技术适配抢占先机:中国联通针对DeepSeek模型优化推理计算量,平均节省30%资源;浪潮信息则开源商用级大模型,赋能AI服务器性能提升。
这场由技术革新驱动的价格战,不仅降低了企业接入AI的门槛,更预示着行业从“堆算力”向“拼效率”的转型。随着英伟达与DeepSeek等厂商的深度合作,2025年AI大模型或将进入“高性价比”普及新阶段。
