想象一下,有一天你在和朋友讨论自己喜欢的电影情节,突然朋友提到:未来会有一种AI可以流畅地写出你们所讨论的情节,甚至还能自动生成对白。
或许你会有些将信将疑,但这并不是科幻小说,而是真实存在于我们生活中的技术。
这种技术的核心就是大型语言模型。
今天,我就来为大家简单聊聊这其中的奥妙,包括它的解码策略和一些关键优化手段。
大型语言模型的技术基础
大型语言模型就像一本超级字典,它可以根据上下文猜出你接下来要说的词。
模型是通过一系列复杂的算法来实现的,核心思想是自回归语言建模。
举个简单的例子,当你说“我喜欢”,模型通过前两个词的条件概率来推测你可能会说的下一个词。
这种逐词推测的方法确保了语义的连贯性。
想了解得更透彻一点,可以把它想象成一个聊天机器人每次都很聪明地回应你的话。
它会综合你提供的所有信息来决定下一个词。

得益于这种特性,模型能生成一段非常自然、流畅的文字,而不是机器硬邦邦的回应。
主流解码策略详解处理语言模型最重要的一环就是解码策略,这决定了模型输出的文字到底是什么样的。
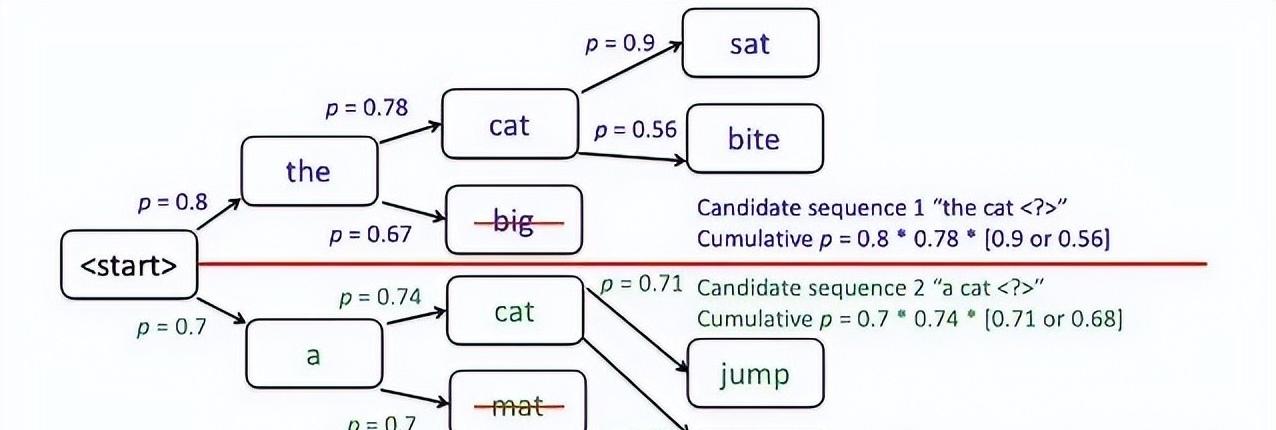
常见的解码策略包括贪婪解码、束搜索和采样等。
和贪婪解码相比,**束搜索**要聪明许多。
它会同时考虑多个候选词,每一轮都挑选出最优的几组,继续往下计算。

你可以想象它就像一个选美比赛,最后选出最优的前三名进行下一轮比赛。
虽然束搜索在生成连贯和多样性的文本上效果更好,但计算资源消耗也更大。
温度参数和优化手段在解码过程中,还有一系列细腻的调节手段,比如温度参数。
这种机制有点类似于在文字里加入不同的“辣度”,把生成的内容搞得更有层次感。
当温度高一些,输出会更具创造性;当温度低一些,输出则更严谨稳定。

此外,还有一些优化手段,比如**频率惩罚和存在惩罚**。
通俗点说,频率惩罚是为了防止模型重复使用某个词,而存在惩罚则是为了鼓励使用更多样的词汇。
这些手段的结合,确保生成内容不仅流畅还更加丰富多彩。
实际应用场景分析这些解码策略和优化手段不仅仅是技术上的创新,在实际场景中的应用也相当广泛。
比如你在使用一款智能对话工具,它背后依赖的正是这些解码策略和优化手段,使得聊天体验更加自然顺畅。

一个生动的例子是ChatGPT,当它生成文本时,会根据具体场景调节温度参数、使用Top-k或核采样,并结合频率和存在惩罚来优化对话质量。
这些技术的无缝结合,使得与AI的对话不仅有趣还富有深度。
结尾读到这里,你可能已经对大语言模型的解码策略和优化手段有了一些了解。
或许有一天,你会发现自己再也分不清某些富有创造性的文字到底是人写的还是AI生成的。
大语言模型在背后默默支持着我们日常生活中的智能应用,而它的解码策略和优化手段,正是这场无声革命的关键。

未来,当你和朋友再次探讨那个未来的AI写作时,你可以自豪地说,你已经了解了其中的技术奥秘。
让我们期待更多的技术突破,使得人类与机器的交流更加自然、充满情感。
人生如一篇篇未解码的文字,大语言模型将挖掘出更多令人惊叹的可能。
读者们,从技术到实例,我们一路走来探讨了大语言模型的解码与优化。
这不仅是对技术的全面总结,更是对未来智能交互的一瞥。
希望这篇文章能带给你一些思考和期待,未来,让我们一起见证这些技术如何改变我们的生活。