
LLM训练性能基准测试(昇腾910B3)
随着 ChatGPT 的火爆,AI 大模型时代已经到来。然而,这也导致了 AI 算力的日益紧缺。同时,中美贸易战和美国对华制裁 AI 芯片,促使国产化适配势在必行。我们曾分享过使用国产 AI 芯片 Mindformers、昇腾910、MindIE 实现大模型训练和服务化的案例。
大模型国产化适配1-华为昇腾AI全栈软硬件平台总结大模型国产化适配2-基于昇腾910使用ChatGLM-6B进行模型推理大模型国产化适配3-基于昇腾910使用ChatGLM-6B进行模型训练大模型国产化适配4-基于昇腾910使用LLaMA-13B进行多机多卡训练大模型国产化适配,基于昇腾910B快速验证ChatGLM3-6B/BaiChuan2-7B模型推理。AI芯片技术原理剖析(一):国内外AI芯片概述华为昇腾LLM落地可选解决方案包括MindFormers、ModelLink和MindIE。其中,MindIE是华为昇腾针对AI全场景业务的推理加速套件,支持多种主流AI框架,向下对接不同类型昇腾AI处理器,提供多层次编程接口,帮助用户快速构建基于昇腾平台的推理业务 。华为昇腾推出了针对LLM的完整部署方案MindIE 1.0.RC1,结束了小米加步枪时代。 MindIE是华为昇腾针对AI全场景业务的推理加速引擎,提供多并发请求的调度功能,支持Continuous Batching。大模型国产化适配9-LLM推理框架MindIE-Service性能基准测试大模型国产化适配10-快速迁移大模型到昇腾910B保姆级教程(Pytorch版)在性能测试之后,我们对MindIE-Service推理框架进行了进一步的优化。同时,我们也对训练框架(ModelLink/MindFormers)进行了全面的训练和测试,以确保其稳定性和高效性。
训练性能的定义在本文中,我们讨论了机器(如GPU、NPU等)在特定模型和输入数据下的训练性能。这里的性能指的是完成一个批量训练所需的时间,同时考虑到不同模型的训练数据量和轮次(epoch)差异。端到端训练通常是指AI模型单步训练的过程。因此,本文关注的是站在模型角度上的性能衡量和优化。
对于一个batch而言,训练所花费的时间主要由以下部分构成:
好的,我可以帮你优化文章内容。以下是我为你优化的文章:
单batch总时间 = 数据加载时间 + 模型前反向时间 + 优化器时间 + 模型后处理时间 + 通信时间 + 调度时间
单batch总时间包括数据加载、模型前反向、优化器、模型后处理、通信和调度等多个环节,这些环节的时间都会影响到单batch的训练速度。
数据加载时间是模型在加载所需数据(如图片、视频和文本等)时所花费的时间,涵盖了从硬件存储设备读取数据到CPU的全过程,以及CPU对数据进行预处理(如编解码等操作)并将数据传输至Device(如GPU/NPU等)的时间。对于需要在多张卡上切分的模型,数据加载过程还包括从一张卡广播数据到其他卡的时间。优化器时间:通常指的是模型参数更新时间。通信时间是通信领域的一个重要概念,它涵盖了单节点内卡与卡之间的通信行为以及多节点间的通信行为。在AI框架(如PyTorch)中,由于其特殊机制和优化,通信和计算可以实现重叠,因此我们关注的是未被计算掩盖的通信时间。训练性能指标FLOPS 与 FLOPs的不同之处
概念辨析:FLOPS 衡量设备性能,如每秒浮点运算次数;而 FLOPs 则反映模型复杂度,即浮点运算操作总数。FLOPS 是每秒浮点运算次数的缩写,是一个衡量硬件性能的指标;而 FLOPs 是浮点运算数的缩写,可以用来衡量算法/模型的复杂度。两者有区别和联系 。单位之别:FLOPS 衡量每秒浮点运算次数,如 TFLOPS、GFLOPS;而 FLOPs 反映浮点运算操作总数,如 MFLOPs、GFLOPS。吞吐量与单个样本延迟不同,集群训练中的最大吞吐率需有效并行处理尽可能多的数据。这依赖于数据、模型和设备规模。为正确测量最大吞吐率,可执行以下两步骤:
估计允许最大并行度的最佳训练样本数据批量大小,即Batch Size;为了找到最佳的Batch Size值,一个实用的经验法则是将其设定为接近AI加速卡(如GPU/NPU)对特定数据类型的内存容量限制。这主要取决于硬件类型、神经网络参数规模以及输入数据的规模等因素。
要找到最大的Global Batch Size,最快的方法是使用二分搜索。当时间不是关键因素时,简单的顺序搜索就足够了。但在大模型训练过程中,Batch Size会影响到不同并行模式(如重计算、Pipeline并行、Tensor并行)的配比以及micro Batch Size的数据分配。因此,将默认Batch Size设置为16的倍数是比较合理的选择。
在确定了在AI加速卡上最大Batch Size值后,可以使用以下公式计算实际吞吐量:BS为Batch Size per DP,即每个数据并行维度的Batch Size大小。N为集群中数据并行维度的大小 。
每秒处理的训练数据样本数:
AI框架的Global Batch Size计算因策略和优化方法的差异而异。以DeepSpeed为例,其Global Batch Size为:
全局训练批次大小 = 每个GPU的微批次大小 * 梯度累积步数 * GPU数量
而 MindFormers 中,Global Batch Size 为
全局批处理大小(global_batch_size)可以通过以下公式计算:
global_batch_size = batch_size * data_parallel * micro_batch_num * micro_batch_interleave_num
其中,`batch_size` 是批处理大小,`data_parallel` 是数据并行度,`micro_batch_num` 是微批次数量,`micro_batch_interleave_num` 是微批次交错数量。
每秒处理的Token数:
假设GLM10B网络模型在DGX A100(8x 80GB)上训练的吞吐量为25 samples/s,最大序列长度为1024。按照tokens计算,吞吐量为 25 * 1024 = 25600 tokens/s,即每秒可处理超过2万个tokens。单卡吞吐量为3200 token/s/p。
线性度线性度,又名加速比(speed up),指单机拓展到集群的效率度量指标。
单机内部线性度单机多卡总吞吐量单卡吞吐量卡数
优化后的文章:NLP和CV大模型中,单机多卡的吞吐率分别以tokens/s和samples/s为基本单位。
集群线性度多机多卡总吞吐量单卡吞吐量卡数集群机器数据
即:
集群线性度多机多卡总吞吐量单机总吞吐量集群机器数据
线性度的取值范围为0~1,数值越接近于1,其性能指标越好。
当多卡或多机的加速比接近高线性度(即线性度接近1)时,说明扩展时的通信瓶颈较小。此时,可以通过增加通信带宽来提升性能。对于整体AI大模型训练而言,通信问题将相对较小,从而提高性能。
当线性度低于0.8(具体取决于服务器集群规模)时,在排除数据IO和CPU影响后,分布式通信可能出现瓶颈。
算力利用率算力利用率指负载在集群上每秒消耗的实际算力占集群标称算力的比例。
标称算力是指硬件或设备在正常工作状态下的理论计算能力,通常以单位时间内能够完成的浮点运算次数(FLOPS)或整数运算次数(IOPS)来衡量。
模型算力利用率(Model FLOPs Utilization, MFU)是指模型一次前反向计算消耗的矩阵算力与机器算力的比值。它是评估某一模型实现对芯片计算性能利用情况的常用指标。MFU直接反映了模型在训练过程中对计算资源的有效利用程度。
硬件算力利用率(Hardware FLOPs Utilization, HFU)是指考虑重计算后,模型一次前反向计算消耗的矩阵算力与机器算力的比值。MFU对于典型的GPT类大模型,99%以上的浮点算力都来自Transformer层和logit层的矩阵乘积(GEMMs),如千亿盘古大模型。通常我们只关注这种矩阵运算。
对于一个GPT类Transformer大模型,
transformer 模型的层数为 l隐藏层维度为 h注意力头数为 a词表大小为 V批次大小为 b序列长度为 sGPU单卡的峰值算力 F训练使用GPU的卡数 N训练一次迭代时间 T因此,每次迭代的浮点预算数为
model FLOPs per iteration =
MLP 中将tensor维度从h提升到4h 再降低到h,浮点计算数为 首个线性层,矩阵乘法输入输出为 [b, s, h] × [h, 4h] → [b, s, 4h],计算量惊人。Q,K,V的变化([𝑏,𝑠,ℎ]×[ℎ,ℎ]→[𝑏,𝑠,ℎ]),浮点计算数为Attention矩阵运算,浮点计算数为在Attention机制中,从线性层到输出的计算过程为$[b,s,h]\times[h,h]→[b,s,h]$,浮点计算数为?请优化文章内容。logits运算([b,s,h]x[h,V]->[b,s,V]),浮点计算数为整个语言模型的每个step的前向传播 FLOPs:
第一项来自 QKVO 和 FFN 中的矩阵乘法第二项来自 attention 矩阵的计算,当s << 6h 时,可以忽略第三项来自 LM head,当V << 12lh ,可以忽略对于 LLaMa-13B 来说,
6h = 6 * 5120 = 30720
12lh = 12 * 50 * 5120 = 3072000
MFU 计算公式:
即
HFU使用了激活重新计算,在反向传播之前需要进行额外的前向传播,这里由于存在不同的重计算策略,计算方式会有一些差异。比如:Reducing Activation Recomputation in Large Transformer Models 中提到的选择性激活重计算(selective activation recomputation),提出了一种策略,即只对那些占用大量内存但重新计算成本不高的Transformer层的部分激活进行存储和重计算。例如,在自注意力机制中,某些操作(如: 矩阵乘法、softmax、softmax dropout和对V的注意力)会产生较大的激活,但每个输入元素所需的浮点运算次数却相对较低。通过选择性地存储这些激活,可以在使用较少内存的同时,以较低的计算开销重新计算未存储的激活。

为了识别通信算子内部瓶颈单元,我们针对同一通信算子在不同卡之间通信时间的波动进行了分析。主要采用以下几个指标:
- 通信时间波动率
- 通信时间延迟
- 通信数据量
算子的执行时间以及内部等待耗时的变化和比例
该指标有助于识别慢卡瓶颈,通过比较每块卡上的wait_ratio与设定阈值(0.2)的关系,判断是否存在慢节点。
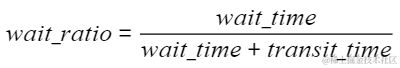
通信带宽分析
当通信算子内部不存在慢节点时,进行通信带宽分析。
主要有如下步骤:
对比该通信算子在各卡上的数据传输耗时 ,得到通信带宽最慢的rank;请计算位于该排名的sdma_bw和rdma_bw,并结合sdma_transit_time和rdma_transit_time,以得出相应的平均带宽。SDMA(System DMA,系统直接内存访问)是一种异步数据传输技术,可以在不占用CPU资源的情况下,实现数据在内存和外设之间的高速传输。RDMA(Remote Direct Memory Access,远程直接内存访问)是一种网络通信技术,其原理是通过绕过操作系统和协议栈的复杂处理过程,直接在网络适配器级别实现数据传输。它将数据直接从一台计算机的内存传输到另一台计算机,无需双方操作系统的介入。这允许高吞吐、低延迟的网络通信,尤其适合在大规模并行计算机集群中使用 。同时,我们会设置一个经验带宽,一般设置为最大带宽的0.8,如图所示。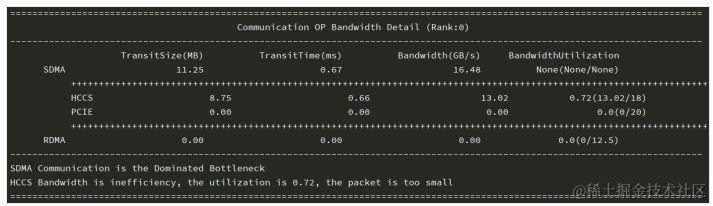
流水线并行是将神经网络中的算子切分成多个阶段,再把阶段映射到不同的设备上,使得不同设备去计算神经网络的不同部分。这种方法适用于模型是线性的图结构。
流水线并行适用于模型是线性的图结构,如图所示,将4层MatMul的网络切分成4个阶段,分布到4台设备上。正向计算时,每台机器在算完本台机器上的MatMul之后将结果通过通信算子发送(Send)给下一台机器,同时,下一台机器通过通信算子接收(Receive)上一台机器的MatMul结果,同时开始计算本台机器上的MatMul;反向计算时,最后一台机器的梯度算完之后,将结果发送给上一台机器,同时,上一台机器接收最后一台机器的梯度结果,并开始计算本台机器的反向。

简单地将模型切分到多设备上并不会带来性能的提升,因为模型的线性结构,同一时刻只有一台设备在工作,而其它设备在等待,造成了资源的浪费(流水线空泡bubble)。为了提升效率,流水线并行进一步将小批次(MiniBatch)切分成更细粒度的微批次(MicroBatch),在微批次中采用流水线式的执行序,从而达到提升效率的目的,如图所示。将小批次切分成4个微批次,4个微批次在4个组上执行形成流水线。微批次的梯度汇聚后用来更新参数,其中每台设备只存有并更新对应组的参数。其中白色序号代表微批次的索引。

为了优化内存管理,我们采用了1F1B(一次前向,一次反向)的流水线并行策略。通过调整执行顺序,我们实现了更高效的内存管理。具体来说,在编号为0的MicroBatch正向执行完成后,立即执行其反向操作。这样一来,编号为0的MicroBatch中间结果的内存能更早地被释放,从而确保内存使用峰值降低。

您好,根据您的需求,我为您找到了一些关于LLM多机多卡训练的信息。目前,传统的单机单卡已经无法满足其训练要求,因此,需要采用多机多卡进行分布式并行训练来扩展模型参数规模,同时使用一些训练优化技术去降低显存、通信、计算等,从而提升训练性能。
分布式训练并行技术:
数据并行张量并行流水线并行MOE并行(稀疏化)之前的文章也介绍过目前常见的分布式并行方案。
大模型分布式训练并行技术(一)-概述大模型分布式训练并行技术(二)-数据并行大模型分布式训练并行技术(三)-流水线并行大模型分布式训练并行技术(四)-张量并行大模型分布式训练并行技术(五)-序列并行大模型分布式训练并行技术(六)-多维混合并行大模型分布式训练并行技术(七)-自动并行大模型分布式训练并行技术(八)-MOE并行大模型分布式训练并行技术(九)-总结这里就不再一一介绍了,本文仅考虑DP/TP/PP这三者最常见的并行技术。
混合精度训练:
FP16 / BF16:降低训练显存的消耗,还能将训练速度提升2-4倍。FP8:NVIDIA H系列GPU开始支持FP8,兼有FP16的稳定性和INT8的速度,Nvidia Transformer Engine 兼容 FP8 框架,主要利用这种精度进行 GEMM(通用矩阵乘法)计算,同时以 FP16 或 FP32 高精度保持主权重和梯度。MS-AMP训练框架 (使用FP8进行训练),与广泛采用的 BF16 混合精度方法相比,内存占用减少 27% 至 42%,权重梯度通信开销显著降低 63% 至 65%。运行速度比广泛采用的 BF16 框架(例如 Megatron-LM)快了 64%,比 Nvidia Transformer Engine 的速度快了 17%。好的,我可以帮您优化这篇文章。重计算(Recomputation)/梯度检查点(gradient checkpointing)是一种在神经网络训练过程中使动态计算只存储最小层数的技术。这种技术可以通过减少保存的激活值来压缩模型占用空间,从而节省显存。但是,在计算梯度时必须重新计算没有存储的激活值。
重计算/梯度检查点是一种在神经网络训练过程中使用的方法,旨在使动态计算只存储最小层数。这种技术可以通过减少保存的激活值来压缩模型占用空间,从而节省显存。但是,在计算梯度时必须重新计算没有存储的激活值。
梯度累积:通过将多个Batch训练数据的梯度累加,在特定次数后,一次性更新模型参数。这样实现大批量模型训练的效果,累积梯度为各Batch梯度的平均值。
FlashAttention v1和v2:通过高效的分块计算和kernel融合技术,大幅降低了HBM访问次数,从而实现了显著的计算加速效果。同时,这一创新方法还减少了显存占用,为训练和推理过程带来了更高效的性能表现。参考项目:Megatron-deepspeed,可在训练与推理阶段灵活应用。
卸载技术是一种用通信换显存的方法,简单来说就是让模型参数、激活值等在CPU内存和GPU显存之间左右横跳。ZeRO-Offload、ZeRO-Infinity等都是这种技术的代表。
基于昇腾910B3进行 LLM 训练性能测试性能测试说明:
AI框架:ModelLink、MindFormers经过优化,以下是不超过54字的文章内容:"探索模型:baichuan2-7b/13b、qwen1.5-7b/14b、llama2-34b,揭示知识的无限可能。"
分布式并行策略:DP/TP/PP训练优化技术:FlashAttn、GQA、混合精度等指标:吞吐量、显存(仅为当前分布式策略下的吞吐量,并不是最大吞吐量)训练数据集:alpaca-52k、belle-random-10k服务器配置:3台910B3,其中2台在同一交换机,另1台在另一交换机,实现高效互联。在910B3上,我们进行了多组对比实验,涵盖了各种训练框架、模型参数规格和显卡组合。这些实验包括:同一框架下不同参数规模的模型对比,同一框架下不同显卡的模型对比,同一框架下不同并行策略的模型对比,以及不同框架下的模型对比等。
声明:LLM训练性能数据仅作参考,各框架训练优化技术未严格对齐。最佳参数为AI框架性能与易用性的隐性标准,实际性能实测为准。

本文概述了LLM训练评估指标,分布式训练策略和显存优化技术。通过MindFormers/ModelLink框架,我们还测试了不同大模型的吞吐量。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-

书同文车同轨
中国企业做大了,美国满世界的迫害! 美国企业做大了,一堆人天天吹捧!! 这就是我们要支持国货的原因!