GPU算力评估

一、 关于训练GPU的带宽
大模型训练算力需求:总算力(Tlops)=6倍模型参数量×训练数据token量,精准高效满足大规模训练需求。
需要把那么计算量和通信量的比例是多少?
3:指的是一次正向两次反向,反向是梯度和权重。在Transformer模型中,heads num代表了自注意力计算的并行度。输入嵌入向量被分解为多个“头”,每个“头”独立执行自注意力运算。这种设计使得每个“头”仅需处理部分嵌入向量,显著降低了内存需求,提升了模型效率。优化后的Transformer模型通过heads num的设置,实现高效且精准的自注意力计算。"bytes per param"指的是每个参数的字节数。对于BF/FP16类型的参数,每参数占用2字节。除以该值,旨在将内存需求从字节量转化为参数数量,实现精准的资源评估。若以每个head分配至一个GPU进行运算,并采用点对点通讯,基于4090的330 Tflops性能,为避免通信瓶颈,所需带宽至少为1.7 TB/s(330T / 384 * 2)。这一需求远超PCIe Gen4 x16的64 GB/s,即使NVLink的900 GB/s也难以满足。由此可见,高效通信技术在当前高性能计算领域具有极其重要的地位。
强调一点,注意力头(attention heads)在GPU间的分割,特指在训练大型深度学习模型(如Transformer)时,通过并行处理将不同注意力头分配到不同GPU,以优化计算效率。此分割通常限于单服务器内的多GPU操作,实现高效计算。
对于4090的330 Tflops性能,为确保通信无阻,所需带宽至少为859 GB/s(330T / 384),双向通信则翻倍至1.7 TB/s,远超PCIe Gen4 x16的64 GB/s带宽,确保高性能计算无瓶颈。
在应用张量并行时,不应过度细分工作负载,确保每个GPU处理足够多的attention heads。这样,由于多个attention heads共享输入矩阵X,输入矩阵的通信开销可以在这些heads之间分摊,从而提高计算量与通信量的比例。以NVIDIA 4090 GPU为例,其计算能力和单向通信带宽为330Tflops和32GB/s(因为64GB/s的带宽需要除以2来考虑单向通信)。这种情况下,计算和通信的比例至少需要达到10000,计算得张量并行的GPU数量应不超过2.4。这意味着,使用张量并行时最多只能使用两个GPU,超过这一数量,GPU的计算能力就无法被充分利用。
然而,当使用更为先进的NVIDIA H100 GPU,情况则有所不同。H100的峰值计算能力为989Tflops,而NVLink的双向带宽为900GB/s。这使得计算量与通信量的比例至少需要1100,计算得出张量并行的GPU数量可以达到11。这表明,在单机配置8张GPU卡进行张量并行是可行的,对于embedding size等于8192的模型,通信不会成为限制因素。
在优化模型性能时,对于embedding size为8192的模型,其参数存储与GPU数量的关系为:2 * 3 * 8192 / (GPU数量 * 2) ≥ 1100。经计算,张量并行GPU数量应不多于11个,即单机8卡配置恰好满足需求,确保通信不会成为性能瓶颈。这一配置优化了模型在GPU上的并行处理能力。
Llama3架构揭秘&FMOps
NVIDIA H200计算力等同H100,GPU显存与内存速度显著增强,将为用户带来前所未有的性能提升体验。
1. 显存提升的影响大显存助力训练更大规模模型,支持更大batch size,显著提升模型性能与训练效率,实现更高效学习。2. 内存速度提升的影响二、3D并行
Tensor、Pipeline和Data三种并行策略分别针对模型层内、层间及训练数据,优化GPU资源分配。这三者的并行度相乘,即确定训练任务所需的总GPU数量,实现高效资源利用与训练效率提升。
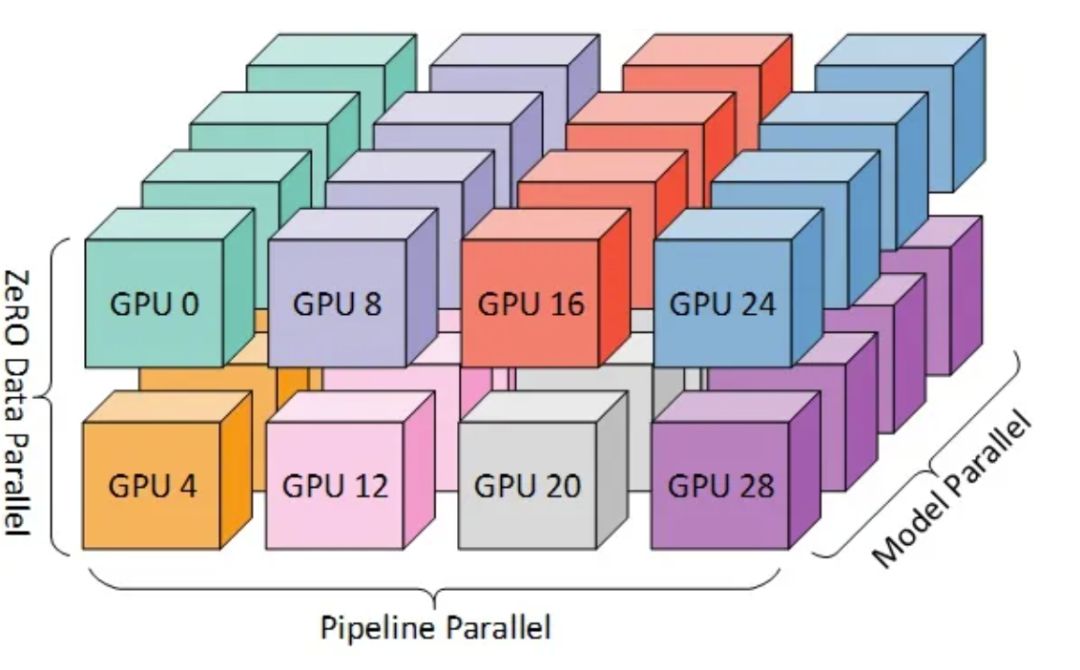
数据并行,即各GPU独立处理不同输入数据,计算梯度后汇总平均,再广播至各GPU进行更新(allreduce)。此方式直观高效,实现模型参数的快速同步更新。

模型训练所需GPU内存涵盖模型参数、梯度、优化器内存及正向传播中的激活状态。确保充足资源,优化训练效率。
Pipeline parallelism(流水线并行)当单GPU无法满足模型需求时,我们需借助多GPU实现model parallelism(模型并行),主要策略包括pipeline parallelism与tensor parallelism,确保高效并行处理大型模型。

面临的问题是,链上仅一个GPU工作,其余闲置。为提升效率,可将一个batch切分为多个mini-batch,实现并行计算,每个mini-batch独立处理,显著提升整体运算效能。

那么,是不是把 pipeline 搞的越深越好,每个 GPU 只算一层?
正向传播中间状态的存储容量随流水级数N成倍增长,对内存容量构成巨大挑战。每级流水线计算后,需历经2N-2轮正反向传播才能利用该中间状态,期间产生并保存2N-1个中间状态。当N值较大时,存储容量急剧膨胀,成为不可忽视的问题。因此,优化存储容量管理,提高内存使用效率,成为亟待解决的关键任务。
在pipeline设计中,相邻流水级间需通信,级数增加会直接导致通信数据量和时延显著上升,影响整体性能。
确保pipeline顺畅运行,需将batch size设为Transformer层数(通常几十层),再乘以data parallelism的并行数。尽管此设定下batch size较大,但务必注意其对模型收敛速度和精度的潜在影响。
因此,在内存容量足够的情况下,最好还是少划分一些流水级。
LLaMA-2 70B模型:参数占140GB,梯度同;若选Adam优化器,状态需额外840GB。高效存储,强大性能,满足大规模AI应用需求。
正向传播的中间状态跟 batch size 和选择性重新计算的配置有关,我们在算力和内存之间取一个折中,那么正向传播的中间状态需要 token 长度 * batch size * hidden layer 的神经元数量 * 层数 * (10 + 24/张量并行度) 字节。假设 batch size = 8,不用张量并行,那么 LLaMA-2 70B 模型的正向传播中间状态需要 4096 * 8 * 8192 * 80 * (10 + 24) byte = 730 GB,是不是很大?
总需求高达1850GB,远超单模型参数的140GB。对于A100/H100卡(每卡80GB),至少需24张;而若选择4090(每卡24GB),则至少需78张。这一庞大需求彰显了计算资源的巨大挑战,体现了高性能计算在现代科技中的核心地位。
LLaMA-2模型仅80层,每张卡承载一层,完美契合。实现80个流水级并行,每个并行batch均能填满流水线,高效运算。
正向传播的中间状态存储膨胀至160轮,即放大160倍,难以承受。即便采用选择性重新计算策略,如将80层划分为8组,每组10层,中间状态存储仍激增16倍,挑战显著。
除极端情况需全面重算,常规反向传播无需逐层重新计算正向结果。但此举计算成本随层数激增,如80层模型需算3240层,开销是正常计算的40倍。如此高昂的代价,岂能容忍?优化算法势在必行,以减轻计算负担,提升模型效率。
中间状态存储挑战严峻,2048张卡间通信开销更是不可小觑。这些卡采用层级分配,各卡以不同输入数据进行独立流水计算,相当于独立参与数据并行处理。在数据并行中,每轮传输涉及梯度和全局平均梯度,其数据量等同于模型参数数量,这进一步加剧了通信负担。
把 70B 模型分成 80 层,每一层大约有 1B 参数,由于优化器用的是 32 bit 浮点数,这就需要传输 4 GB 数据。那么一轮计算需要多久呢?总的计算量 = batch size * token 数量 * 6 * 参数量 = 8 * 4096 * 6 * 1B = 196 Tflops,在 4090 上如果假定算力利用率 100%,只需要 0.6 秒。而通过 PCIe Gen4 传输这 4 GB 数据就已经至少需要 0.12 秒了,还需要传两遍,也就是先传梯度,再把平均梯度传过来,这 0.24 秒的时间相比 0.6 秒来说,是占了比较大的比例。
当然我们也可以做个优化,让每个 GPU 在 pipeline parallelism 中处理的 80 组梯度数据首先在内部做个聚合,这样理论上一个 training step 就需要 48 秒,通信占用的时间不到 1 秒,通信开销就可以接受了。
当然,通信占用时间不到 1 秒的前提是机器上插了足够多的网卡,能够把 PCIe Gen4 的带宽都通过网络吐出去,否则网卡就成了瓶颈。假如一台机器上插了 8 块 GPU,这基本上需要 8 块 ConnectX-6 200 Gbps RDMA 网卡才能满足我们的需求。
聚焦batch size,2048张卡集群运行时,每GPU mini-batch设为8,总batch size高达16384,堪称大规模训练之典范。然而,再增大batch size可能影响模型收敛速度及精度。因此,当前配置已趋近最佳,确保训练高效且精准。
大模型训练时,流水线并行与数据并行的核心挑战在于级数过多,引发正向传播中间状态存储容量瓶颈,亟需解决。
Tensor parallelism(张量并行)仍有转机!最后一招是Tensor parallelism(张量并行),作为模型并行的高级形式,它在层内而非层间进行划分。这一方法将同一层的attention计算和Feed Forward Network分散至多个GPU处理,从而显著提升计算效率。
张量并行技术巧妙解决了GPU存储限制导致流水级过多的挑战。原本需80个GPU才能容纳的模型,通过单机8卡张量并行,仅需10个流水级即可。此外,该技术还能降低batch size,因各GPU协同处理同一输入数据,实现了高效计算与资源优化。

Attention计算高效并行,得益于多head机制,能同时关注输入序列不同位置。简单拆分head,即可实现并行处理,提升效率。

三、Batch size的公式

global_batch_size =
gradient_accumulation_steps
* nnodes (节点数)
* nproc_per_node (每个节点卡数)
* per_device_train_batch_si(micro bs大小)
我们想象一个场景:
假设情景:
batch_size = 10 #每批次大小total_num = 1000 #数据总量按照 训练一个批次数据,更新一次梯度;
训练步数 train_steps = 1000 / 10 = 100
梯度更新步数 = 1000 / 10 = 100
当显存不足以支持每次 10 的训练量!需要减小 batch_size
通过设置gradient_accumulation_steps = 2
batch_size = 10 / 2 =5
优化后文案:采用每5个数据作为一个批次,训练2批次后更新一次梯度,既减轻显存负担,又确保每次更新基于10个数据,效率与准确性并存。
梯度更新步数 1000 / 10 = 100 未改变
梯度累加优化策略:每batch数据计算梯度后不清零,持续累加,直至达到gradient_accumulation_steps次数,再更新参数并清零梯度,实现高效参数更新,循环推进训练进程。
直接调小Batch Size的影响训练稳定性:小批量尺寸易导致梯度估计方差上升,影响训练稳定性。相反,大批量尺寸能提供更稳定的梯度估计,优化训练过程。训练时间:学习率调整:调整学习率对于较小的batch size至关重要。建议降低学习率,防止梯度更新过大引发训练波动,确保训练过程更加稳定。使用梯度累加的优势保持有效批次大小:减少训练步数:梯度累加可以减少训练步数,因为每次参数更新仍然基于较大的有效批次大小。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
