 一、什么是大模型缩放定律?
一、什么是大模型缩放定律?
用一句话概括:AI模型就像气球,吹得越大,能装的“知识”就越多,但需要的气(算力)和力气(数据)也越大。
(1)核心规律
科学家发现,当同时增加以下三要素时,AI能力会显著提升:
参数规模:相当于大脑神经元数量,GPT-3有1750亿个参数,能记住更多知识
训练数据:相当于学习资料,GPT-4用了45TB文本,覆盖几乎所有领域的知识
计算资源:相当于学习时间,训练GPT-4用了上万块顶级显卡,耗时3个月
这三者遵循幂律关系:投入资源翻10倍,性能可能提升30%(类似考试刷题,刷得越多成绩越好,但进步会逐渐变慢)。
二、为什么大模型更聪明?
(1) 核心技术支撑
Transformer架构:像“超级记忆网”,能同时分析整段话的逻辑(比如理解“他”指代谁)
分布式训练:把模型拆分到数万台电脑上训练,类似万人合唱团分声部练习
数据筛选:先学数学公式再背诗歌,优先学习高质量内容(如专业论文而非网络八卦)
(1) 涌现现象
当参数超过千亿级时,AI会突然解锁新能力。例如:
GPT-3(1750亿参数)突然会写代码GPT-4(约1.8万亿参数)能解微积分题这就像人类青春期智力突增,无法用小模型预测
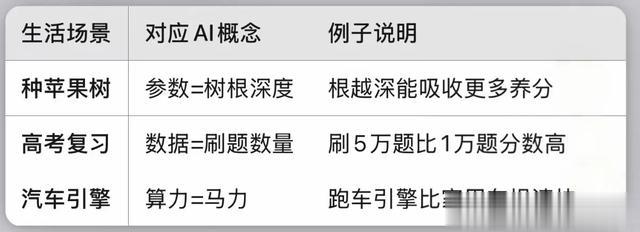
三、生活中的类比
 四、技术瓶颈与突破
四、技术瓶颈与突破
(1)当前挑战
成本爆炸:训练GPT-5预计耗电相当于10万户家庭一年用电量
数据荒:互联网优质文本即将被耗尽,新数据获取成本飙升
性能天花板:参数翻10倍,性能可能只提升5%
(2) 未来方向
小模型+云计算:手机端小模型遇到难题时求助云端大模型(类似在线问专家)
合成数据:用AI生成训练数据,解决素材短缺问题
光子芯片:用光速传输替代电流,降低能耗
五、普通人需要知道什么? AI不是魔法:ChatGPT的聪明源于海量数据和算力堆砌,而非真正的思考越大≠越好:医疗诊断可能不需要万亿参数,专业小模型更实惠警惕泡沫:部分企业用“千亿参数”炒作概念,实际效果可能注水
AI不是魔法:ChatGPT的聪明源于海量数据和算力堆砌,而非真正的思考越大≠越好:医疗诊断可能不需要万亿参数,专业小模型更实惠警惕泡沫:部分企业用“千亿参数”炒作概念,实际效果可能注水理解这些规律,你就能看懂AI新闻里的“参数军备竞赛”,理性看待技术发展啦!
