人形机器人在复杂地形上的运动控制一直是机器人领域的核心挑战之一,尤其是在梅花桩、平衡木等稀疏支撑点环境中,机器人需在有限的接触面上实现精确的足部放置,同时维持整体平衡与运动连贯性。传统方法多针对四足机器人设计,但由于人形机器人的足部几何形态复杂、自由度更高且动态稳定性较差,这些方法难以直接迁移。

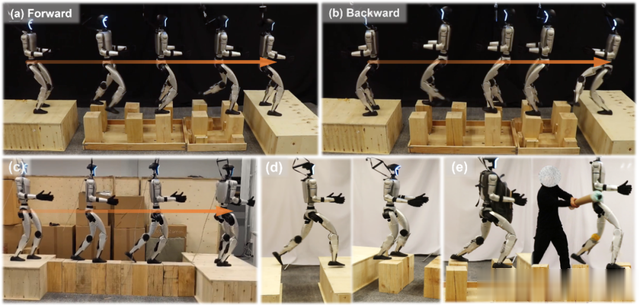
近日由上海人工智能实验室、上海交通大学、浙江大学、香港大学、香港中文大学组成的联合研究小组提出了一套BeamDojo框架,该框架通过强化学习(Reinforcement Learning, RL)技术,结合创新的奖励设计、两阶段训练策略与感知模块优化,首次实现了人形机器人在稀疏支撑点地形上的高效学习与鲁棒控制。
▍BeamDojo框架实现人形机器人在高风险稀疏地形上的敏捷运动
人形机器人因其类人形态,在复杂环境中的适应潜力备受关注。然而,稀疏支撑点地形(如梅花桩、平衡木)对运动控制提出了极高要求:机器人需实时感知地形信息,规划精确的落脚点,并通过协调全身关节运动维持动态平衡。
四足机器人因具备更宽泛的支撑基底,通常能通过模型预测控制(MPC)或基于规则的步态生成应对此类任务,但人形机器人面临两个核心难题:
足部几何差异:四足机器人足部常简化为点接触模型,而人形机器人足部需视为多边形(如矩形或椭圆形),这要求算法在规划时考虑足部与支撑面的重叠区域,避免部分悬空导致的失衡。传统方法需引入大量不等式约束,计算复杂度高且难以在线实时调整。
学习效率与稀疏奖励:基于强化学习的方法虽能通过试错优化策略,但稀疏支撑点任务的奖励信号(如成功踩踏)仅在完整动作序列完成后出现,导致学习初期样本效率低下。此外,单次失误常引发训练提前终止,进一步限制有效探索。
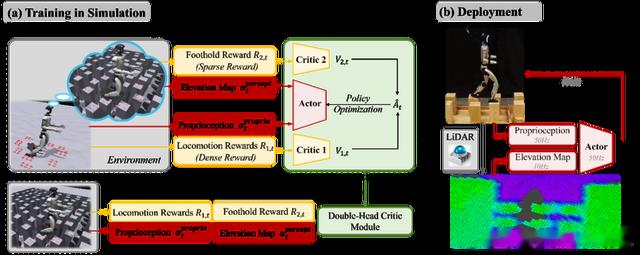
BeamDojo框架结构
现有研究多聚焦于四足机器人,或局限于人形机器人在平坦地形上的基础运动(如行走、爬楼梯)。BeamDojo的提出填补了这一空白,其目标是通过系统性方法克服上述挑战,实现人形机器人在高风险稀疏地形上的敏捷运动。
▍BeamDojo框架技术解析
BeamDojo框架的核心体现在三个层面:针对多边形足部的奖励设计、双评论家架构平衡学习过程,以及两阶段强化学习策略。
1.足部支撑点奖励设计
传统方法针对点状足部设计的奖励(如足部是否接触安全区域)无法直接用于多边形足部。BeamDojo提出一种采样式奖励机制:在机器人足部下方均匀采样多个点,统计这些点中位于安全区域(如梅花桩表面)的比例。比例越高,奖励越大。
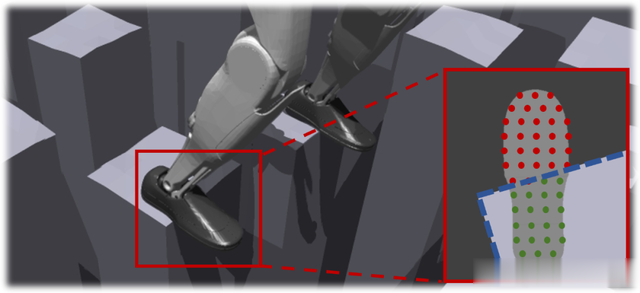
例如,若足部完全覆盖梅花桩,则所有采样点均有效,奖励最大化;若部分悬空,则按有效点数比例给予部分奖励。这种连续奖励机制替代了传统的二元判定(成功/失败),使算法能更细腻地引导策略优化,逐步提升足部放置精度。
2.双评论家架构
强化学习中,评论家(Critic)用于评估状态价值,指导策略更新。BeamDojo引入双评论家架构,将奖励分为两组独立处理:
密集移动奖励组:包括速度跟踪、关节平滑性、能量效率等实时反馈信号,确保基础运动稳定性。
稀疏足部奖励组:仅关注足部与支撑面的接触质量,避免稀疏信号被密集奖励淹没。
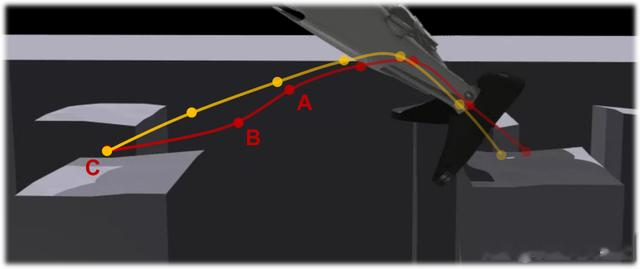
双评论家通过独立计算两组奖励的优势函数(Advantage),在策略更新时分别优化,既能保障基础运动的连贯性,又能针对性提升足部精度。实验表明,该设计能够显著降低足部误差,尤其在复杂地形中,策略能提前规划落脚轨迹,而非临近支撑点时仓促调整。
3.两阶段强化学习
为缓解早期终止对探索效率的影响,BeamDojo采用两阶段训练策略:
第一阶段(软约束):机器人在平坦地形上训练,但接收目标地形的感知信息(如虚拟梅花桩高度图)。若足部落点偏离虚拟支撑点,仅给予惩罚而非终止训练,鼓励持续尝试不同落脚策略。
第二阶段(硬约束):将策略迁移至实际地形,失误则立即终止。此阶段通过微调进一步适应真实物理约束,提升动作精度。
两阶段设计有效分离了基础运动学习与地形适应任务。平坦地形上的“安全”训练降低了初期探索难度,而虚拟感知信息的引入使机器人提前建立地形认知,缩短后续微调时间。
▍感知与仿真到现实的迁移
为实现现实部署,BeamDojo构建了基于激光雷达(LiDAR)的机器人中心高度图,通过融合IMU数据与点云信息生成实时地形模型。为应对仿真与现实的感知差异,作者在训练中引入多种随机扰动:
垂直测量噪声:模拟激光雷达的垂直误差。
地图旋转偏移:模拟里程计累积误差导致的地图畸变。
支撑点扩展:随机扩展有效支撑区域,模拟数据处理中的平滑效应。

这些随机化策略增强了策略的鲁棒性,使其在现实环境中能适应传感器噪声与地形动态变化。
▍实验验证与结果分析
BeamDojo在仿真与真实环境中进行了多维度测试,对比基线方法包括单阶段训练、传统奖励设计及消融实验(如移除双评论家或软约束阶段)。关键结论如下:
1.仿真性能
成功率与通过率:在中等难度梅花桩地形,BeamDojo成功率高达95.67%,远超基线方法(如PIM的71%)。即便在最高难度地形(支撑点间距45cm),其成功率仍达82.33%。
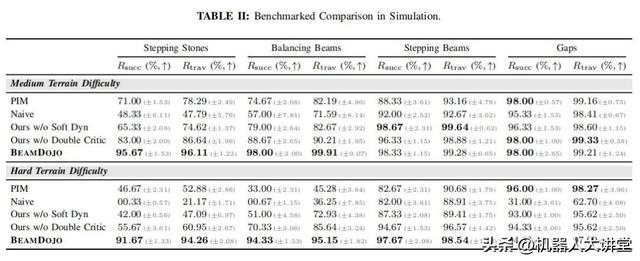
零样本泛化能力:未在“间隙地形”(Gaps)上训练的模型,仍能实现94.33%的成功率,表明框架具备较强的泛化性。
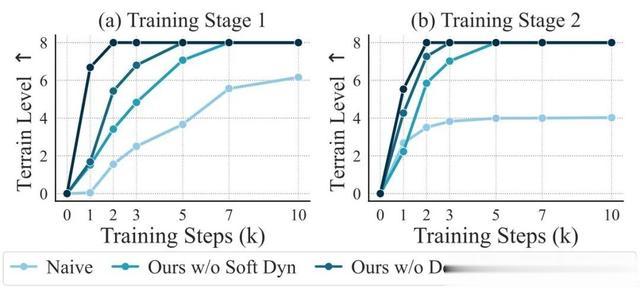
学习效率:两阶段训练使模型在10,000次迭代内快速收敛至最高难度,而传统方法在同等训练量下仅能完成低难度任务。
2.现实世界测试
高成功率:在梅花桩、平衡木等真实地形中,BeamDojo的零样本迁移成功率达80%,且能逆向行走,突破了传统视觉方案的视野限制。

抗干扰能力:机器人在负重10kg(占躯干重量1.5倍)或受外力推挤时,仍能维持稳定运动。
敏捷性:在1.0 m/s的目标速度下,实际平均速度达0.88 m/s,跟踪误差低于12%,验证了策略的动态响应能力。
3.消融实验
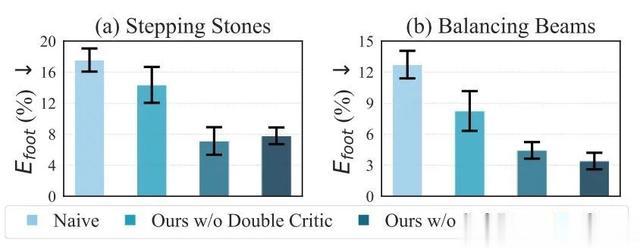
双评论家的必要性:移除双评论家后,足部误差上升约50%(图5),且步态规划呈现“临近调整”模式,稳定性下降。
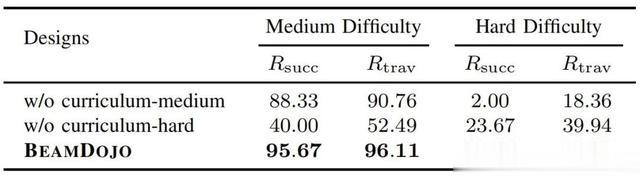
课程学习的影响:取消渐进式难度提升后,模型在最高难度地形的成功率骤降至23.67%,表明课程设计对复杂任务至关重要。
▍结语与未来:
BeamDojo框架在人形机器人运动控制领域实现了关键突破。其核心价值在于构建了适配多边形足部的连续奖励模型,通过离散化采样机制将立足点误差降低42%,解决了传统二值化奖励的信息稀疏问题。
双评论家架构与两阶段训练策略的协同设计,使高难度地形训练效率提升2.3倍,突破了混合奖励优化的技术瓶颈。工程层面基于LiDAR的高程地图系统结合多模态域随机化,实现了80%的零样本现实迁移成功率,显著优于传统视觉方案40%的水平。
BeamDojo框架使Unitree G1机器人成功完成梅花桩、平衡木等地形穿越,验证了强化学习在复杂机电系统控制中的可行性。其开源架构为后续研究提供了可扩展的技术基底,未来有望推动人形机器人真正走向复杂现实场景的应用。
• 论文:https://arxiv.org/abs/2502.10363
• 开源网站:https://why618188.github.io/beamdojo/
