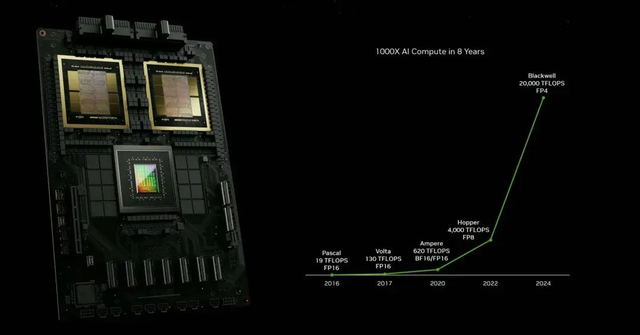
想挑战Transformer的新架构有很多,来自谷歌的“正统”继承者Titan架构更受关注。

英伟达把测试时间计算(Test-timeComputing)称为大模型的第三个ScalingLaw。
OpenAI把它用在推理(Reasoning),谷歌这次把它用在了记忆(Memory)。
一作AliBehrouz表示:
Titans比Transformers和现代线性RNN更高效,并且可以有效地扩展到超过200万上下文窗口,性能比GPT4、Llama3等大模型更好。
他还解释了这篇研究的动机,团队认为Transformer中的注意力机制表现为短期记忆,因此还需要一个能记住很久以前信息的神经记忆模块。

新的长期记忆模块
提到记忆,大家可能会想到LSTM、Transformer等经典模型,它们从不同角度模拟了人脑记忆,但仍有局限性:
要么将数据压缩到固定大小的隐状态,容量有限;
要么可以捕捉长程依赖,但计算开销随序列长度平方级增长。
并且,仅仅记住训练数据在实际使用时可能没有帮助,因为测试数据可能在分布外。
为此,Titans团队打算将过去信息编码到神经网络的参数中,训练了一个在线元模型(Onlinemeta-model),该模型学习如何在测试时记住/忘记特定数据。
他们从神经心理学中汲取灵感,设计了一个神经长期记忆模块,它借鉴了人脑原理:
意料之外的事件(即“惊喜”)更容易被记住。
惊喜程度由记忆模块对输入的梯度来衡量,梯度越大说明输入越出人意料。
引入动量机制和遗忘机制,前者将短期内的惊喜累积起来形成长期记忆,后者可以擦除不再需要的旧记忆,防止记忆溢出。
记忆模块由多层MLP组成,可以存储深层次的数据抽象,比传统的矩阵记忆更强大。
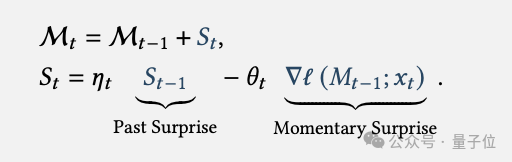
这种在线元学习范式,避免了模型记住无用的训练数据细节,而是学到了如何根据新数据调整自己,具有更好的泛化能力。
另外,团队还验证了这个模块可以并行计算。
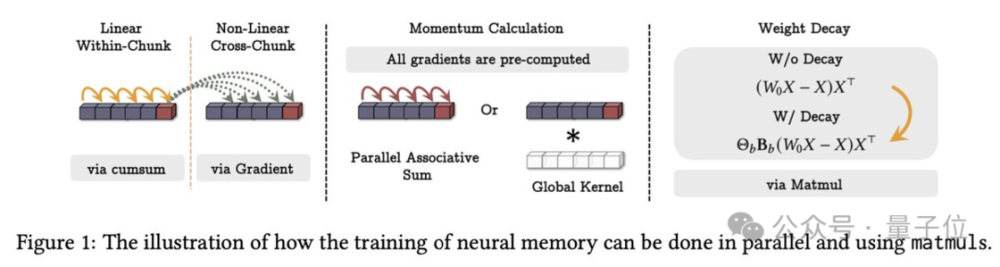
如何将这个强大的记忆模块融入深度学习架构中呢?
为此,Titans提出了三种变体:
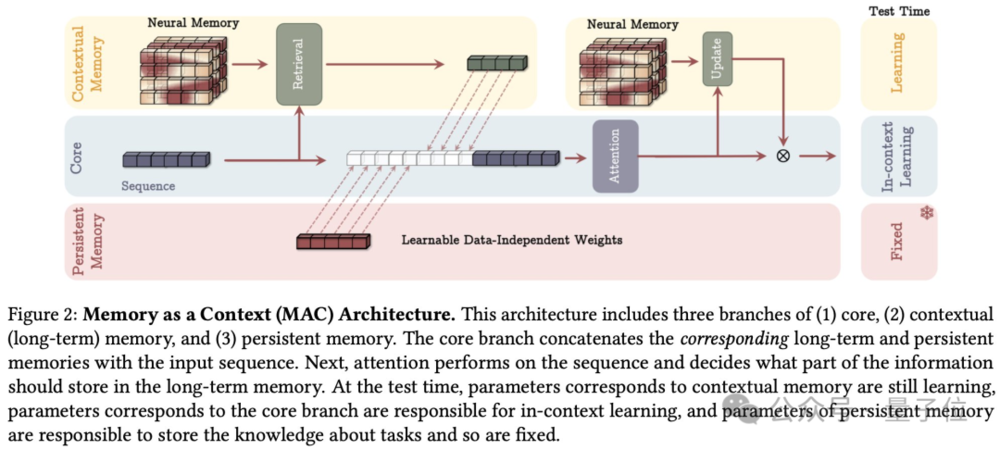
MAC,记忆作为上下文
将长期记忆和持久记忆(编码任务知识的不变参数)作为当前输入的上下文,一起输入给attention。
MAG,记忆作为门
在记忆模块和滑动窗口attention两个分支上进行门控融合。
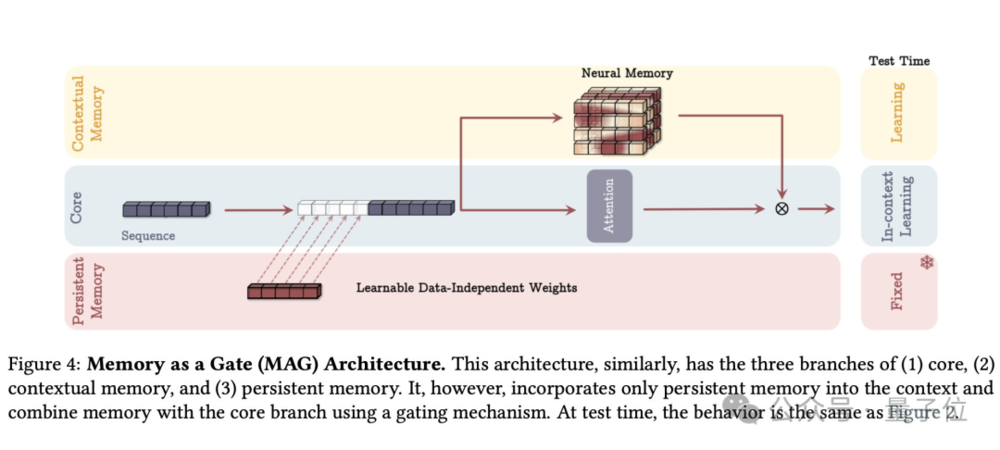
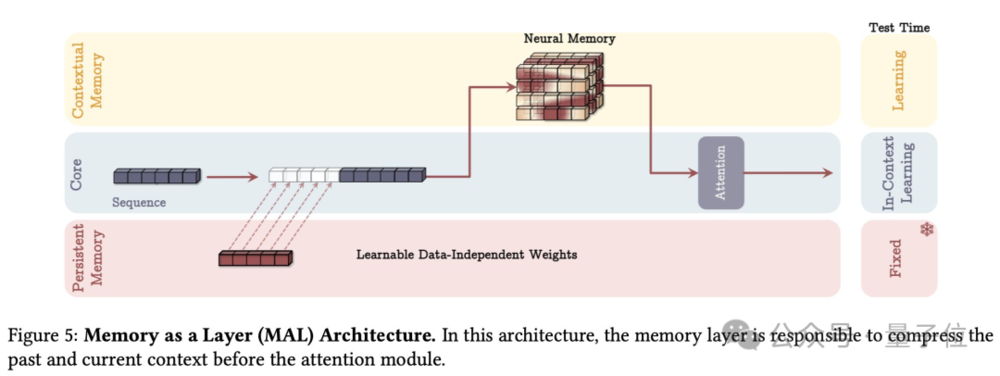
MAL,记忆作为层
将记忆模块作为独立的一层,压缩历史信息后再输入给attention。
在实验中,发现每种方法都有自己的优缺点。
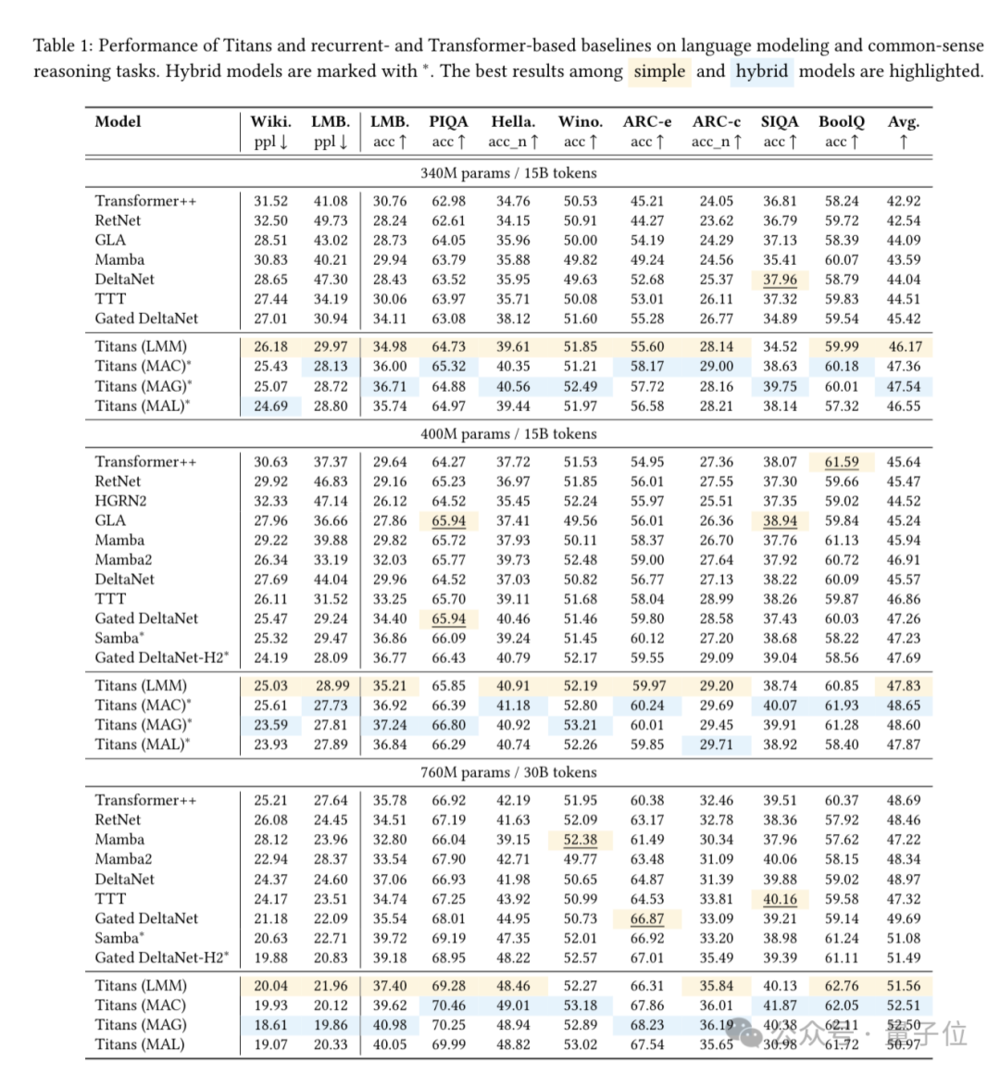
Titans在语言建模、常识推理、时间序列预测等任务上全面超越Transformer和Mamba等各路架构的SOTA模型。
并且仅靠长期记忆模块(LMM,Long-termMemoryModule)本身,就在多个任务上击败基线。
证明了即使没有短期记忆(也就是Attention),该机制也具备独立学习的能力。
在长文本中寻找细粒度线索的“大海捞针”测试中,序列长度从2k增加到16k,准确率保持在90%左右。
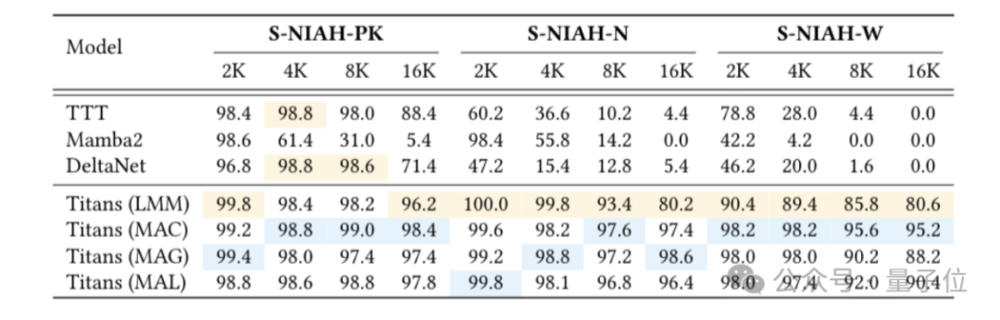
但团队认为,这些通用的测试已经体现不出Titans在长文本上的优势。
在另一项需要对分布在极长文档中的事实做推理的任务中,Titans表现超过了GPT4、Mamba等,以及Llama3.1+RAG的系统。
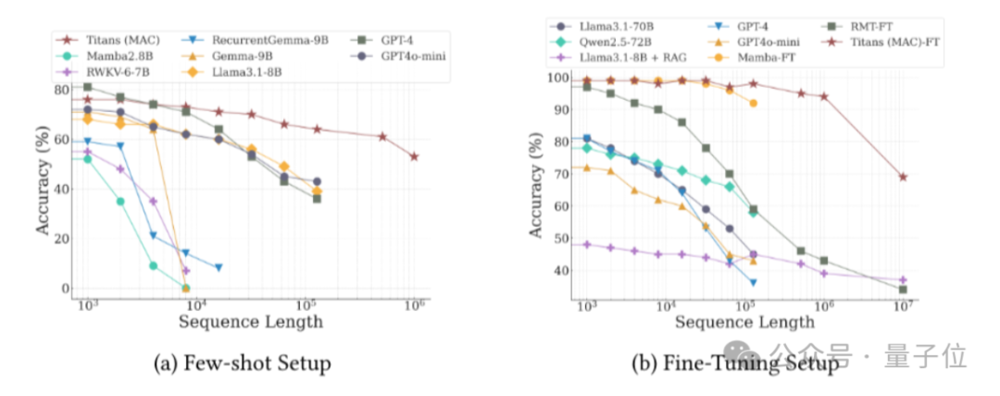
另外在时间序列预测、DNA序列建模等特定任务中,Titans也取得不错的表现。
三位作者来自GoogleResearchNYC算法和优化团队,目前还没被合并到GoogleDeepMind。
一作是AliBehrouz来自康奈尔大学的实习生。
钟沛林是清华姚班校友,博士毕业于哥伦比亚大学,2021年起加入谷歌任研究科学家。
2016年,钟沛林本科期间的一作论文被顶会STOC2016接收,是首次有中国本科生在STOC上发表一作论文。

领队的VahabMirrokni是GoogleFellow以及VP。

团队表示Titians是用Pytorch和Jax中实现的,打算很快提供用于训练和评估模型的代码。
论文地址:https://arxiv.org/abs/2501.00663v1
参考链接:[1]https://x.com/behrouz_ali/status/1878859086227255347