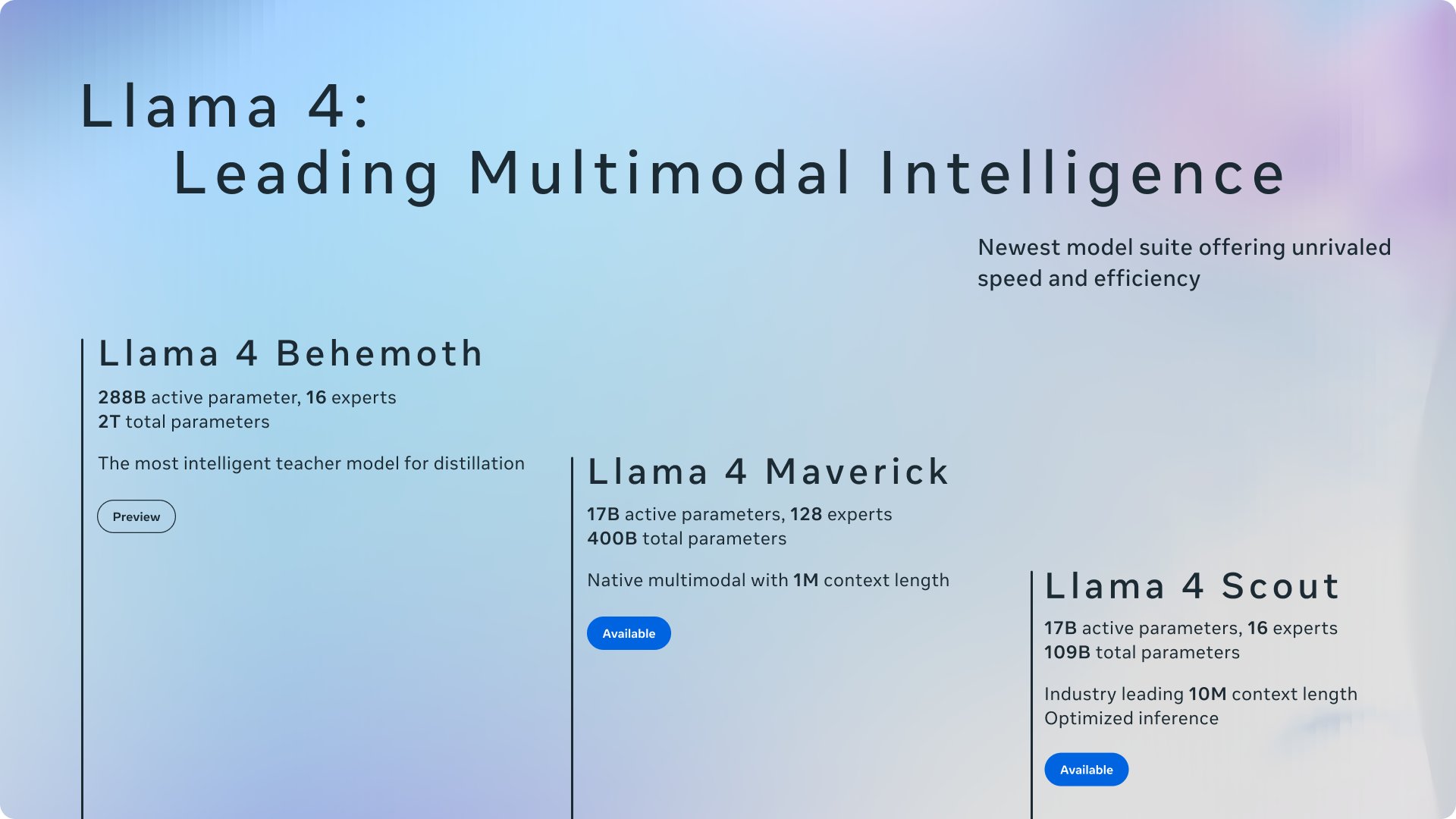
Meta今日凌晨发布旗下最新Llama4系列开源AI模型,包含Llama4Scout、Llama4Maverick和Llama4Behemoth。
Meta表示,这些模型都经过了“大量未标注的文本、图像和视频数据”的训练,以使它们具备“广泛的视觉理解能力”。
“今天标志着原生多模态人工智能创新的新纪元的开启。我们推出了首批Llama4模型:Llama4Scout和Llama4Maverick——这是我们迄今为止最先进的模型,也是多模态领域中同类最佳的模型。”
具体来看:
Llama4Scout
•170亿活跃参数模型,配备16个专家。
•行业领先的上下文窗口,可处理1000万标记。
•在广泛认可的多项基准测试中,表现优于Gemma3、Gemini2.0Flash-Lite和Mistral3.1。
Llama4Maverick
•170亿活跃参数模型,配备128个专家。
•在图像定位方面处于行业顶尖水平,能够将用户提示与相关的视觉概念对齐,并将模型响应锚定在图像的特定区域。
•在广泛认可的多项基准测试中,表现优于GPT-4o和Gemini2.0Flash。
•在推理和编码方面,与DeepSeekv3取得了相当的结果,而活跃参数仅为后者的一半。
•在性价比方面,其聊天版本在LMArena上的ELO得分为1417。
Meta表示,这些模型之所以成为其迄今为止最好的模型,得益于从Llama4Behemoth中进行的知识蒸馏,而Llama4Behemoth是其迄今为止最强大的模型。Llama4Behemoth仍在训练中,目前在专注于STEM的基准测试中,表现优于GPT-4.5、ClaudeSonnet3.7和Gemini2.0Pro。
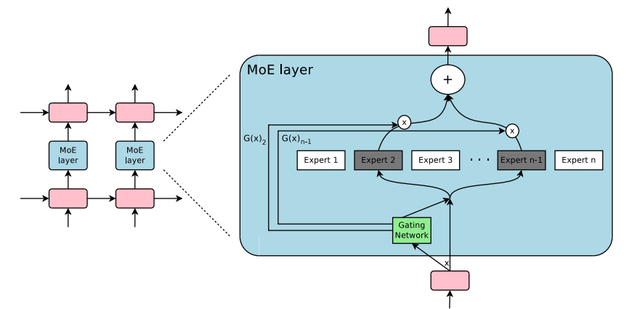
Llama4系列模型是该公司旗下首批采用混合专家(MoE)架构的模型,这种架构在训练和回答用户查询时的效率更高。
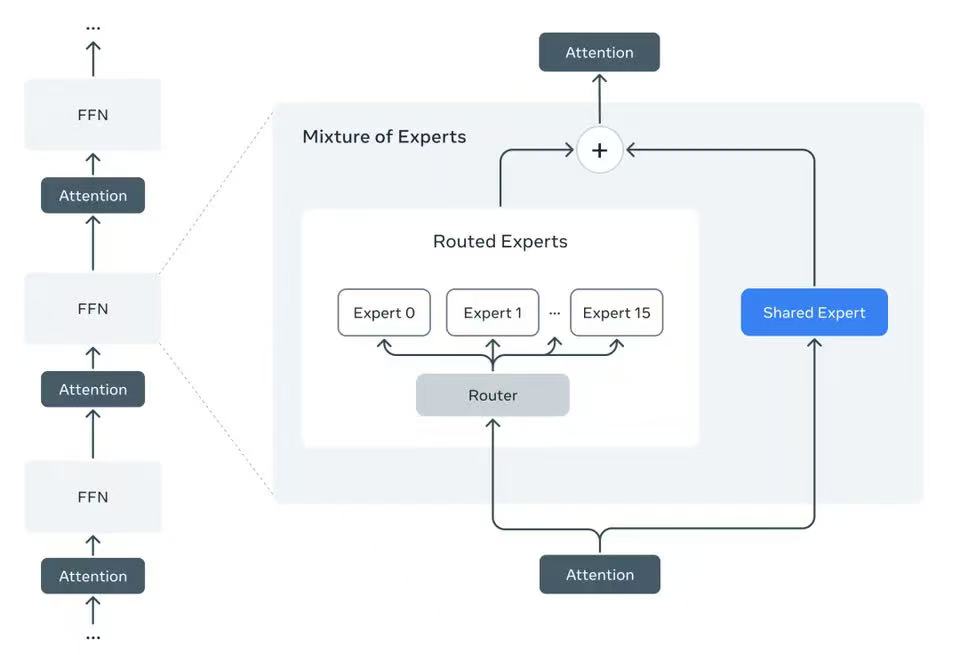
“混合专家架构”是将数据处理任务分解为子任务,然后将它们委派给更小的、专门的“专家”模型。(三言科技)


枕头什么都知道
热烈欢迎越来越多的开源大模型进入市场,特别是meta这一次把大量的视觉和视频数据投入到训练当中,使大模型具有比较强大的多模态能力。
唧唧?
遥遥领先得一直吹,除了习惯靠垄断的盈利模式,其它都卷不过东边[大笑]
puff...
跟着deepseek学的moe
蓝调
内部测试显示相关模型表现佳,证明利大。混合专家大模型可以大大的节省算力,而且在训练的时候可以进行分布式的训练,也大大的节省了再次训练所需要的算力。 Deepseek和Llama 现在都拥抱了混合专家,看起来一定是一个重要的开源发展的方向。
沉阁
希望我们的deepseek抓紧赶上、赶超!