vLLM不但第一时间支持了DeepSeek-V3.2-Exp,还做了个新增的稀疏注意力(DSA)是如何工作的图解。
👇为让AI结合该图解做的解释:
------------
DeepSeek 稀疏注意力,简称 DSA,是一种为了提升大语言模型在处理长文本时的效率而设计的架构。它的核心思想是避免让模型在每一步都计算当前词与上下文中所有词之间的注意力关系,因为这会导致计算量随文本长度的平方增长,非常耗时。取而代之的是,DSA 采用了一种两阶段的智能筛选方法。
第一阶段是一个快速的预筛选过程,由一个叫做“闪电索引器”的轻量级组件完成。第二阶段则是由一个更强大的主注意力模块,即稀疏多潜注意力(Sparse MLA),来对预筛选出的关键信息进行精细计算。下面我们分步骤详细说明这个过程。
第一步是准备计算所需的各种向量。当模型接收到一个隐藏状态输入时,它会通过不同的线性变换,也就是投影,生成多组不同的向量。一部分是为最终的稀疏 MLA 主注意力模块准备的标准查询(Query)、键(Key)和值(Value)向量。另一部分则是专门为闪电索引器准备的,这些向量的维度更小,计算起来更快。一个特别之处在于,模型还会从隐藏状态中生成一组额外的“头部权重”向量,这组权重将在索引器的评分阶段扮演重要角色。
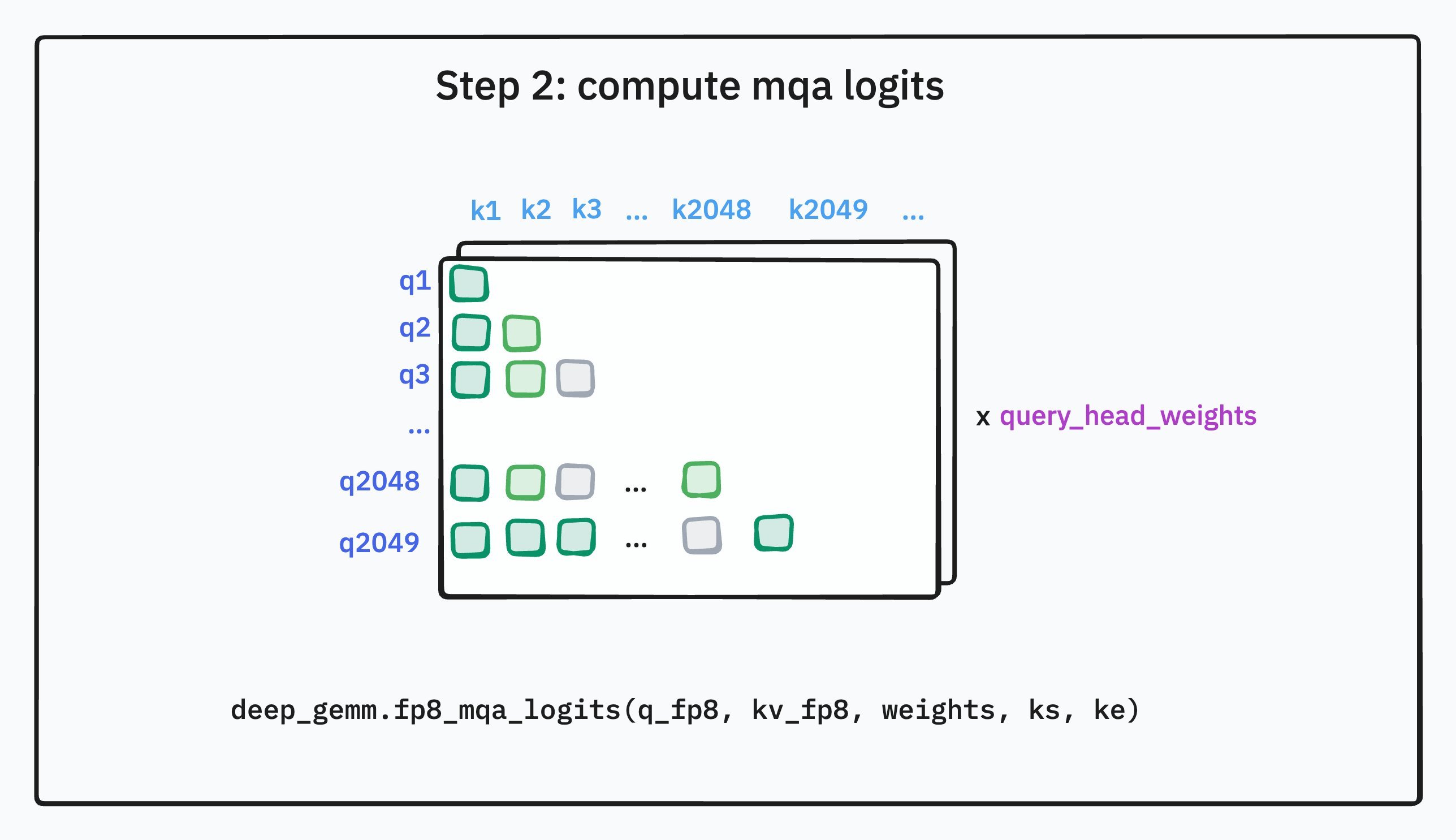
第二步是闪电索引器进行评分。索引器的工作就是快速评估上下文中每一个过去的词(Key)对于当前词(Query)的重要性。它通过计算索引器版本的查询向量和键向量之间的关系来得到一个分数。这个评分过程并非简单的点积相似度计算,而是更加精巧。索引器内部有多个“头”,每个头都会算出一个相似度分数,然后模型会用上一步生成的“头部权重”来对这些头的得分进行加权求和。这种机制使得模型可以根据当前的上下文,动态地判断哪种类型的相似性更重要,从而更准确地找出最相关的词。这个过程虽然也需要扫描整个上下文,但由于索引器本身的计算非常轻量,所以总体开销远小于完整的主注意力计算。
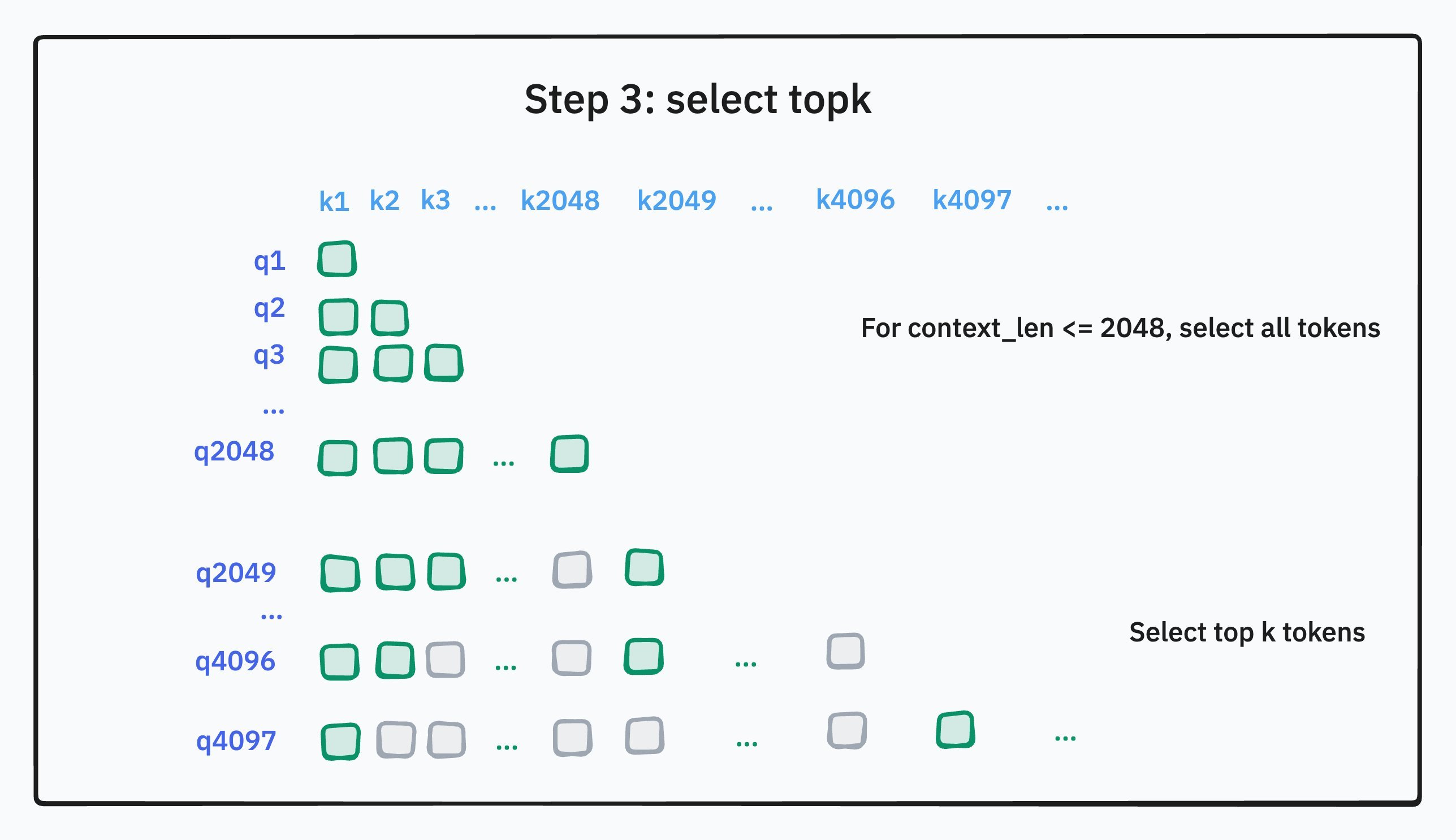
第三步是根据评分进行筛选,即 Top-k 选择。在索引器为当前查询词计算出与所有历史词的分数后,系统会从这些分数中选出得分最高的若干个,比如最高的 2048 个。这意味着,无论上下文有多长,模型在下一步都只需要关注这 2048 个被认为最相关的词。如果上下文本身就不足 2048 个词,那么所有的词都会被选中。这一步是实现“稀疏”的关键,它将一个原本需要密集计算的注意力矩阵,变成了一个只需要在少数几个位置进行计算的稀疏矩阵。
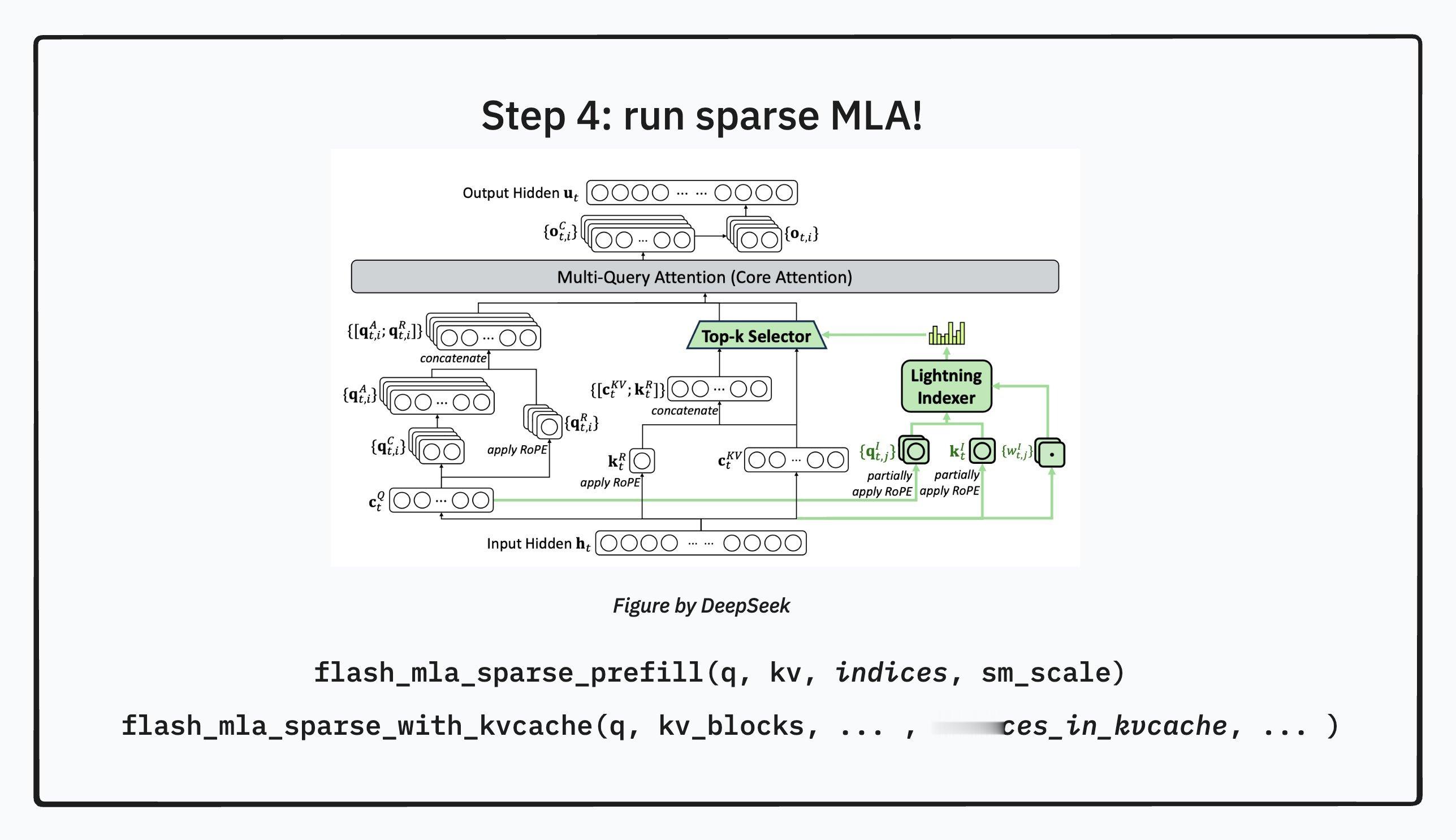
第四步是运行稀疏主注意力模块。现在,模型进入了真正的主注意力计算阶段。但是,与标准模型不同,这里的查询向量不会再与上下文中的所有键值对进行计算。它只会与上一步筛选出的那 2048 个最重要的键值对进行注意力计算。这样一来,核心计算的复杂度就从与文本总长度的平方相关,降低到只与文本总长度乘以 2048 这个固定值相关,极大地提升了效率。为了在硬件上高效执行这种跳跃式的稀疏计算,模型还会调用专门优化的计算核函数,例如 FlashMLA 稀疏核函数,以确保计算速度最大化。
DSA 的核心思想是一种分工合作的策略。它用一个“快而粗”的闪电索引器来完成大海捞针式的全局搜索任务,快速定位出最可能相关的信息。然后,再用一个“慢而精”的稀疏主注意力模块,集中全部计算资源,对这些被精选出来的信息进行深度处理。通过这种方式,DSA 在保持了对关键信息精确捕捉能力的同时,显著降低了长文本处理的计算成本,实现了效率和性能的平衡。
DeepSeek新模型发布