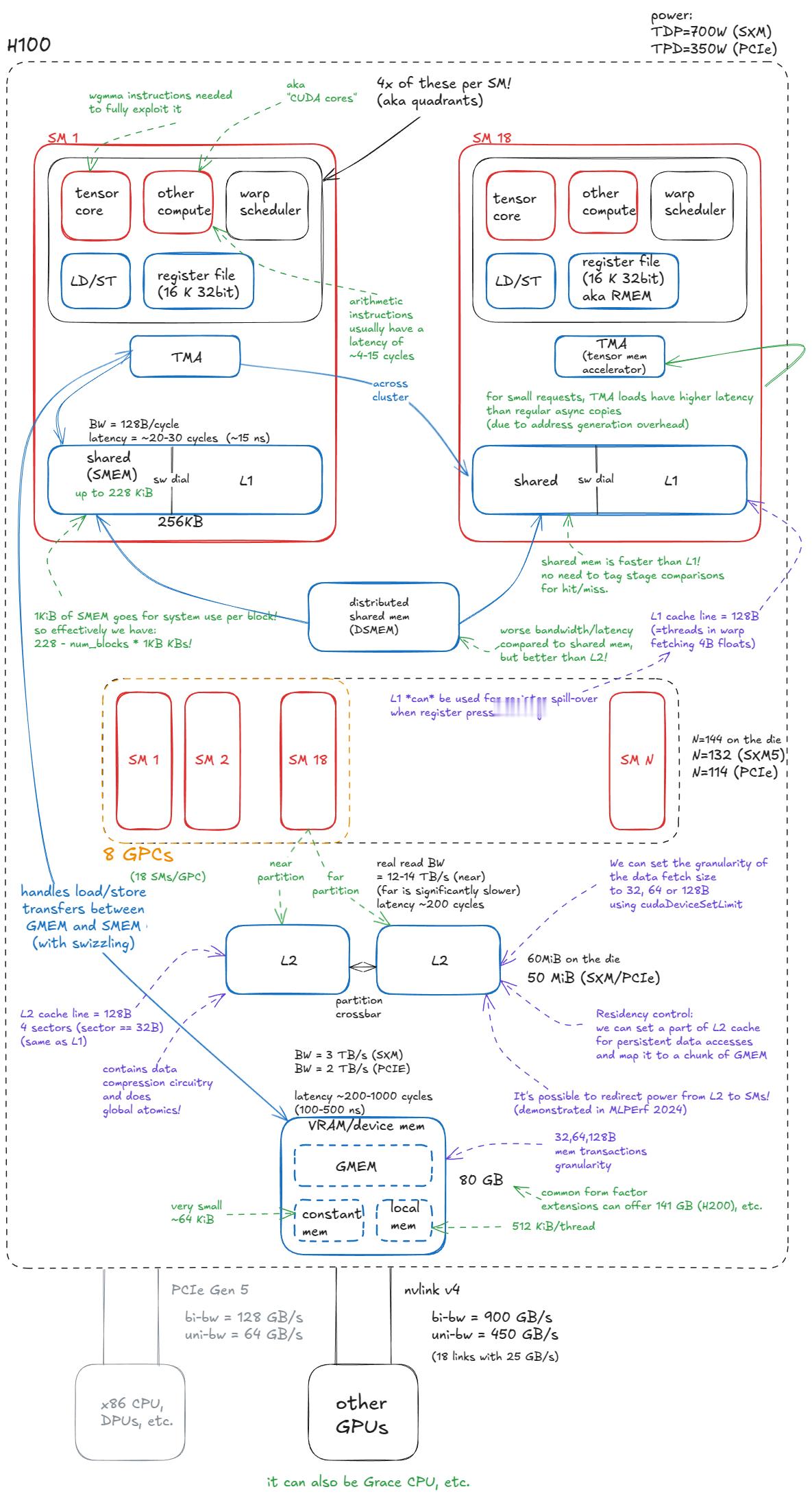
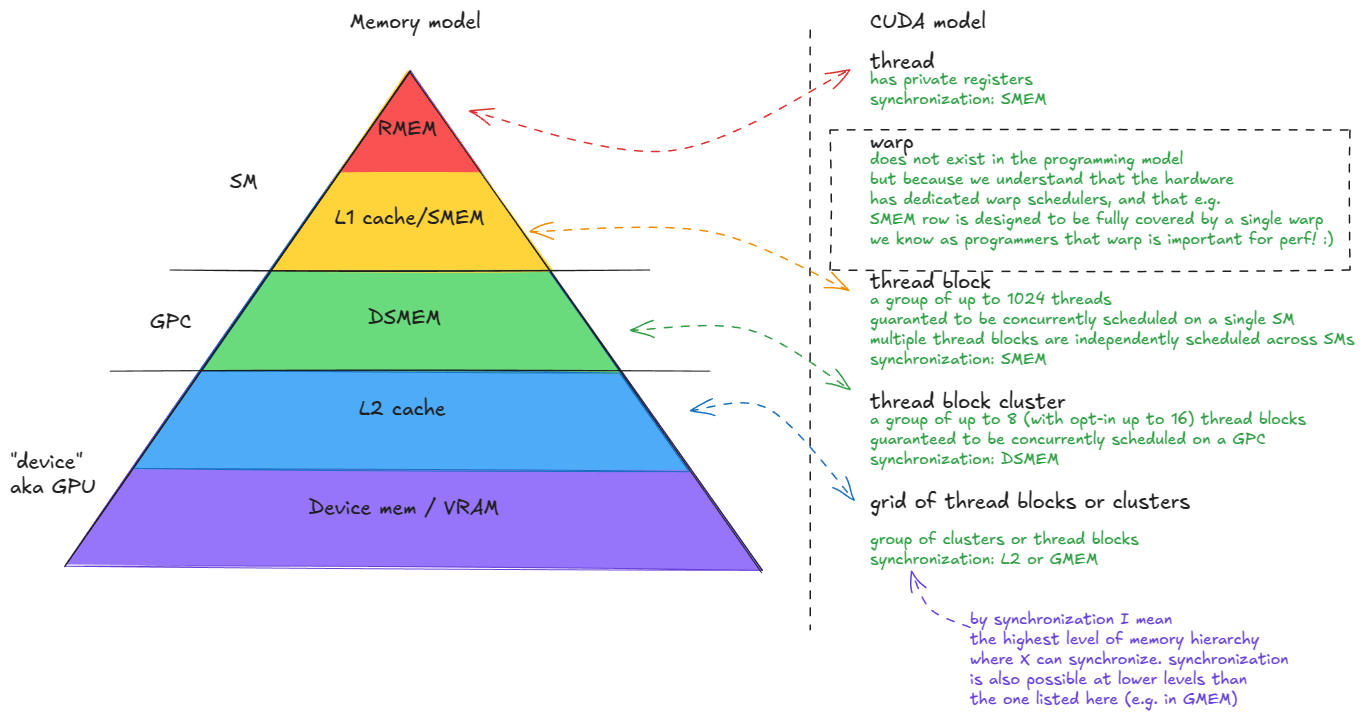
长篇博文: 深入 NVIDIA GPU:高性能矩阵乘法内核剖析www.aleksagordic.com/blog/matmul"在这篇文章中,我将逐步介绍支撑最先进(SOTA)NVIDIA GPU 矩阵乘法(matmul)内核的所有核心硬件概念和编程技术。为什么关注矩阵乘法? Transformer 模型在训练和推理过程中,其绝大部分浮点运算(FLOPs)都消耗在矩阵乘法上(例如 MLP 中的线性层、Attention 的 QKV 投影、输出投影等)。这些操作本质上是高度并行(embarrassingly parallel)的,因此与 GPU 天然契合。最后,理解矩阵乘法内核的工作原理,将为你提供设计几乎任何其他高性能 GPU 内核所需的工具包。本文分为四个部分:1️⃣NVIDIA GPU 架构基础: 全局内存、共享内存、L1/L2 缓存、功耗节流(power throttling)对光速极限(SOL)的影响等。2️⃣GPU 汇编语言: SASS 和 PTX。3️⃣设计接近 SOTA 的同步矩阵乘法内核: Warp 分块(warp-tiling)方法。4️⃣在 Hopper 架构上设计 SOTA 异步矩阵乘法内核: 利用 Tensor Cores、TMA(Tensor Memory Accelerator)、计算与加载/存储重叠、希尔伯特曲线(Hilbert curves)等。我的目标是让这篇文章自成一体:细节丰富足以独立成篇,同时足够精炼,避免写成一本教科书。"科技先锋官AI创造营