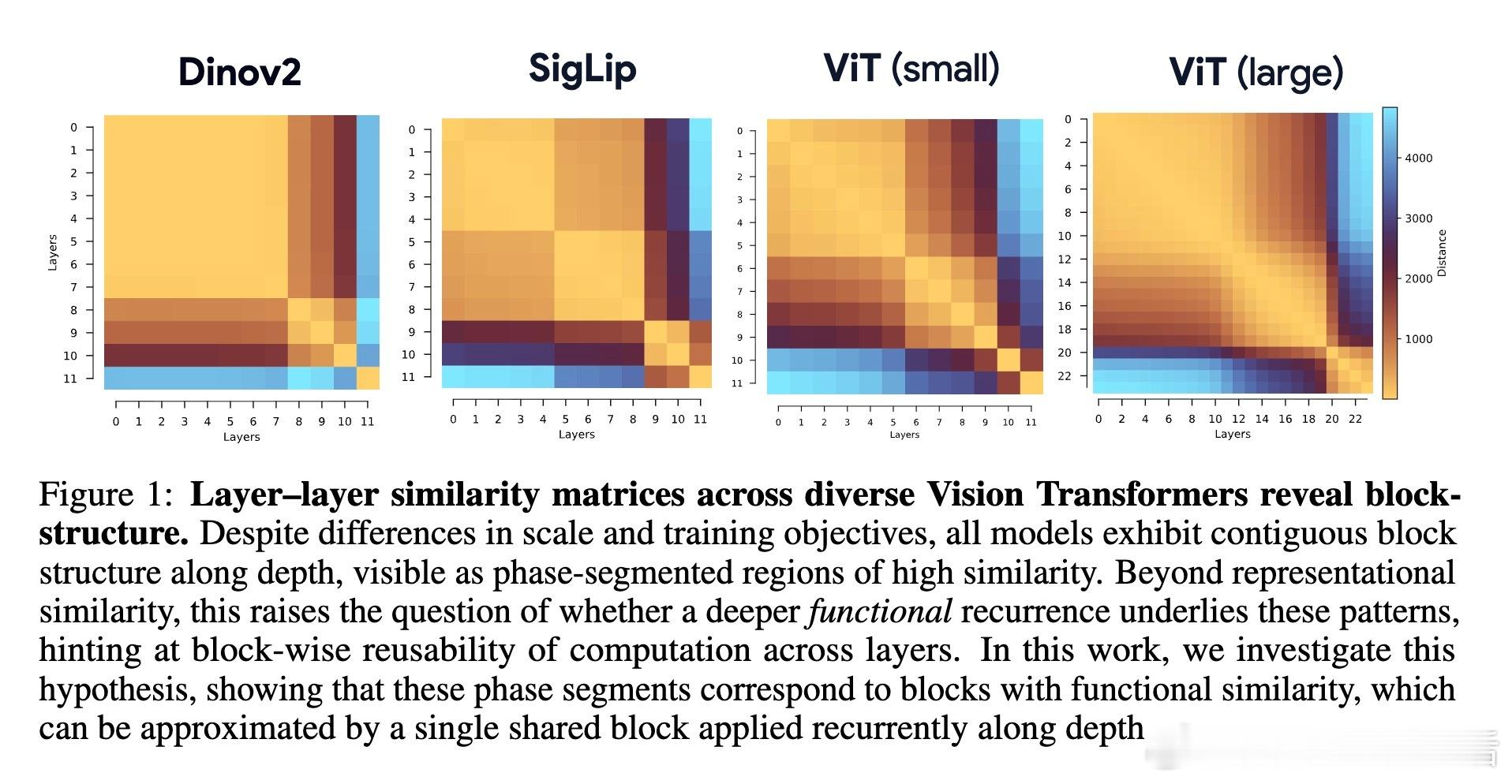
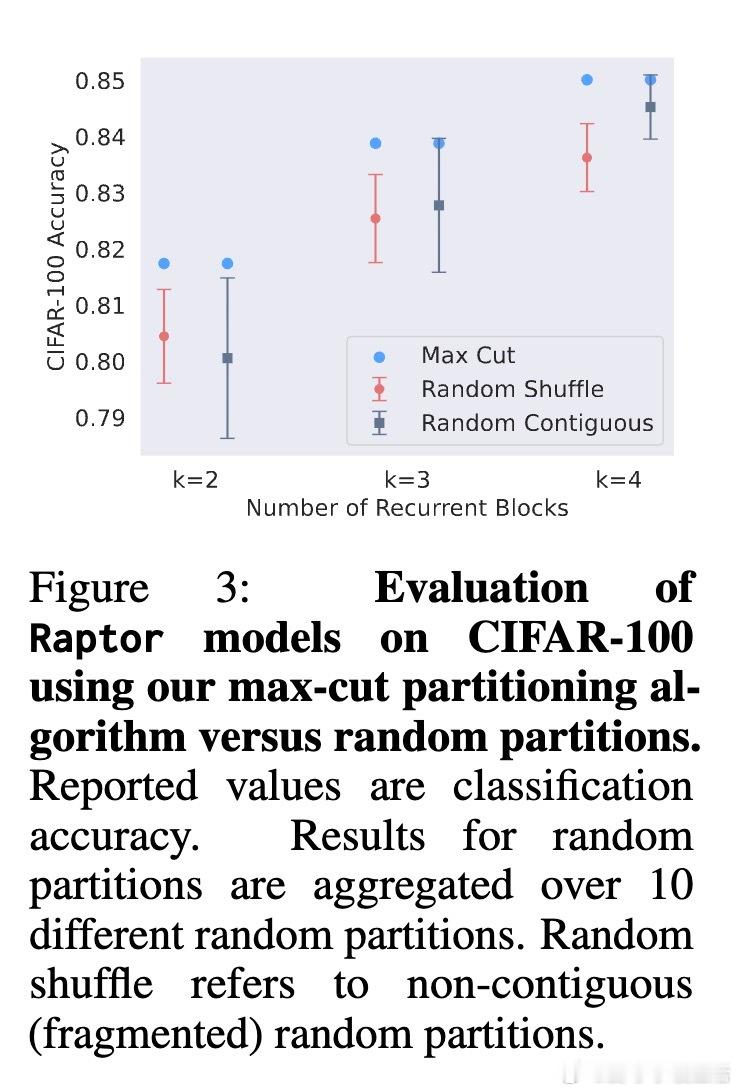
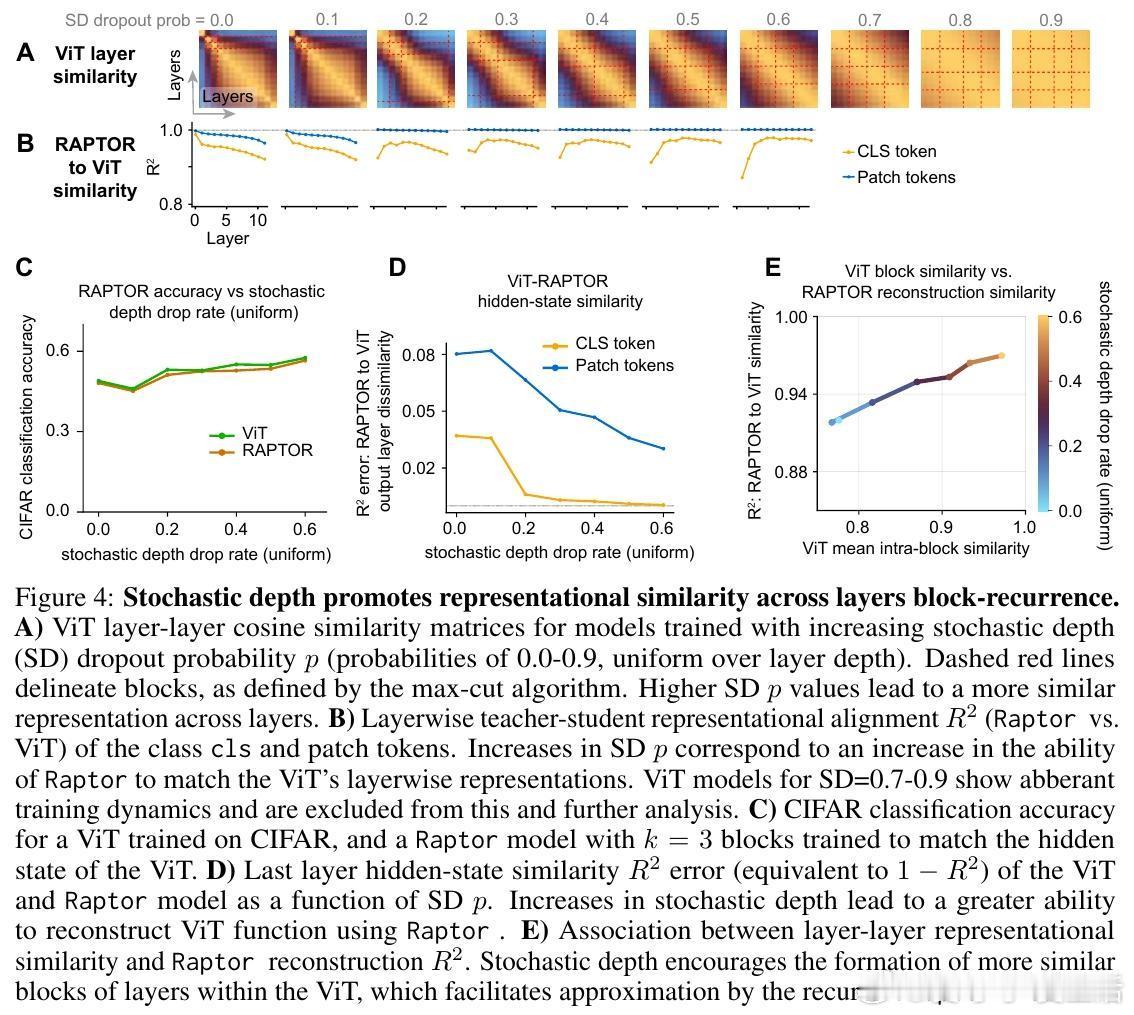
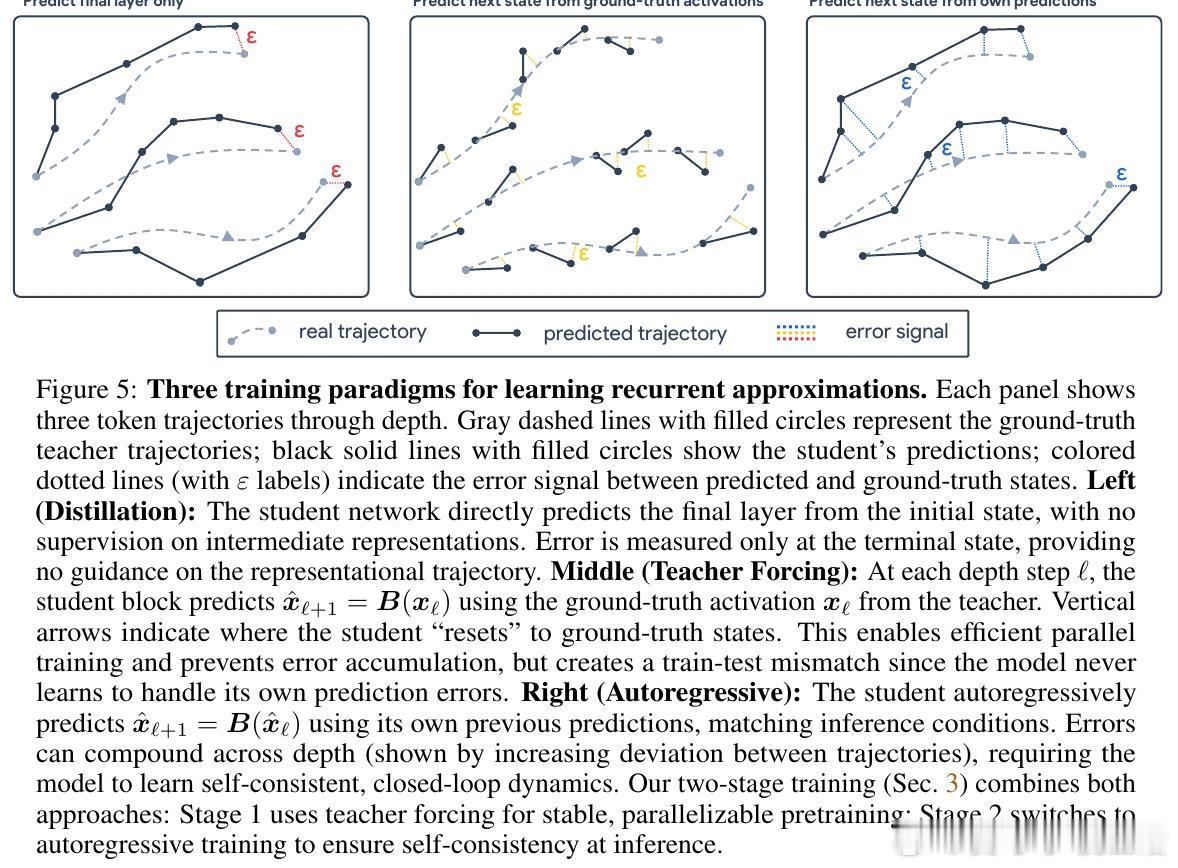
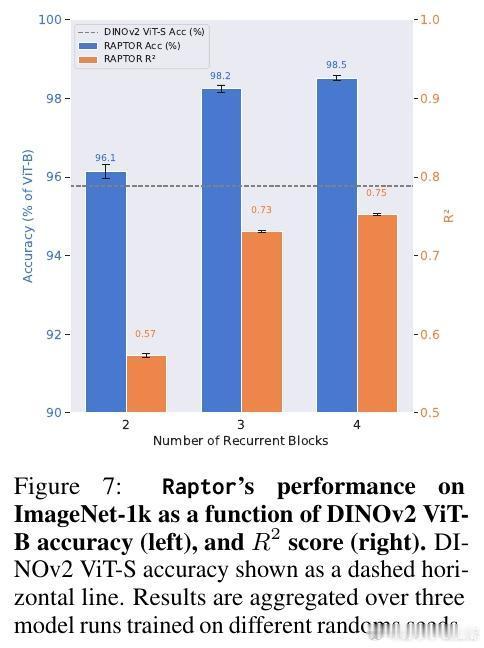
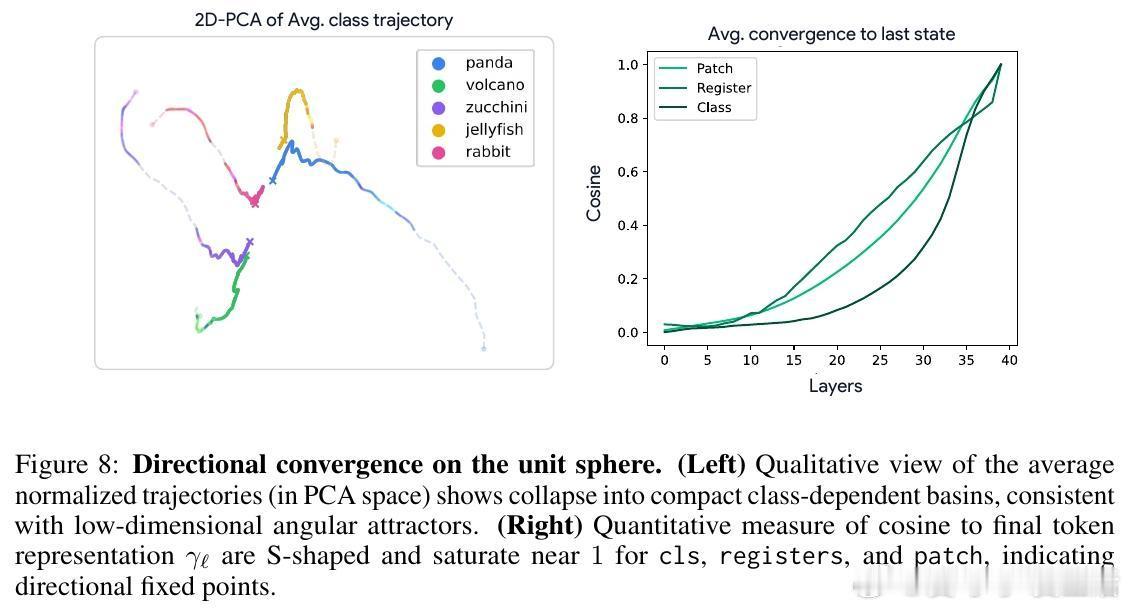
[CV]《Block-Recurrent Dynamics in Vision Transformers》M Jacobs, T Fel, R Hakim, A Brondetta... [Harvard University] (2025) 深度不一定是长度,也可能是循环。长期以来,我们习惯将视觉Transformer(ViT)视为层层堆叠的阶梯,认为每一层都在执行独特的计算。本文提出了块循环假设(Block-Recurrent Hypothesis),彻底颠覆了这种认知。这项研究告诉我们:ViT的深度其实是一种被掩盖的循环。1. 块循环假设:深度的真相研究者发现,训练后的ViT在深度方向上会自动组织成几个连续的阶段。这意味着,原本几十层的复杂模型,实际上可以用极少数(比如2到3个)不断重复调用的功能块来重写。这不仅是表示层面的相似,更是功能层面的重用。2. Raptor:用循环重构模型为了验证这一假设,研究者开发了Raptor模型。令人惊讶的是,仅使用2个循环块,就能恢复DINOv2在ImageNet上96%的性能;增加到3个块时,性能恢复率达到了98%。这意味着,ViT在设计上虽然是前馈的,但在运行逻辑上却演化出了极高的算法简洁性。3. 随机深度的功劳为什么会产生这种循环结构?研究发现,训练过程中的随机深度(Stochastic Depth)起到了关键作用。这种正则化手段迫使模型层与层之间产生功能冗余,从而促进了块循环结构的涌现。4. 动力学解释:深度即流动当我们将深度视为一种离散时间的动力系统流时,奇妙的现象发生了:- 走向吸引子:所有Token的表征方向最终都会收敛到特定的角吸引子盆地中,表现出极强的自纠错能力。- Token的分工:CLS Token在后期会经历剧烈的重新定向以整合全局信息,而Patch Token则表现出强烈的集体相干性,类似于平均场效应。- 低秩坍缩:随着深度增加,层与层之间的更新会坍缩到极低维的子空间。这说明模型在后期并不是在做加法,而是在精简和聚焦。5. 深度思考:回归简洁这项研究揭示了一个深刻的规律:优秀的神经网络往往具有极低的算法复杂度(Levin Complexity)。模型在追求高性能的过程中,会自动发现并利用重复的算法原语。正如文中所言:在深度学习中,循环总会找到自己的出路。这种循环诱导的简洁性偏置,为我们理解大模型打开了一扇窗。如果复杂的模型本质上是简单的循环,那么我们离真正的机械可解释性(Mechanistic Interpretability)就又近了一步。原文链接:arxiv.org/abs/2512.19941