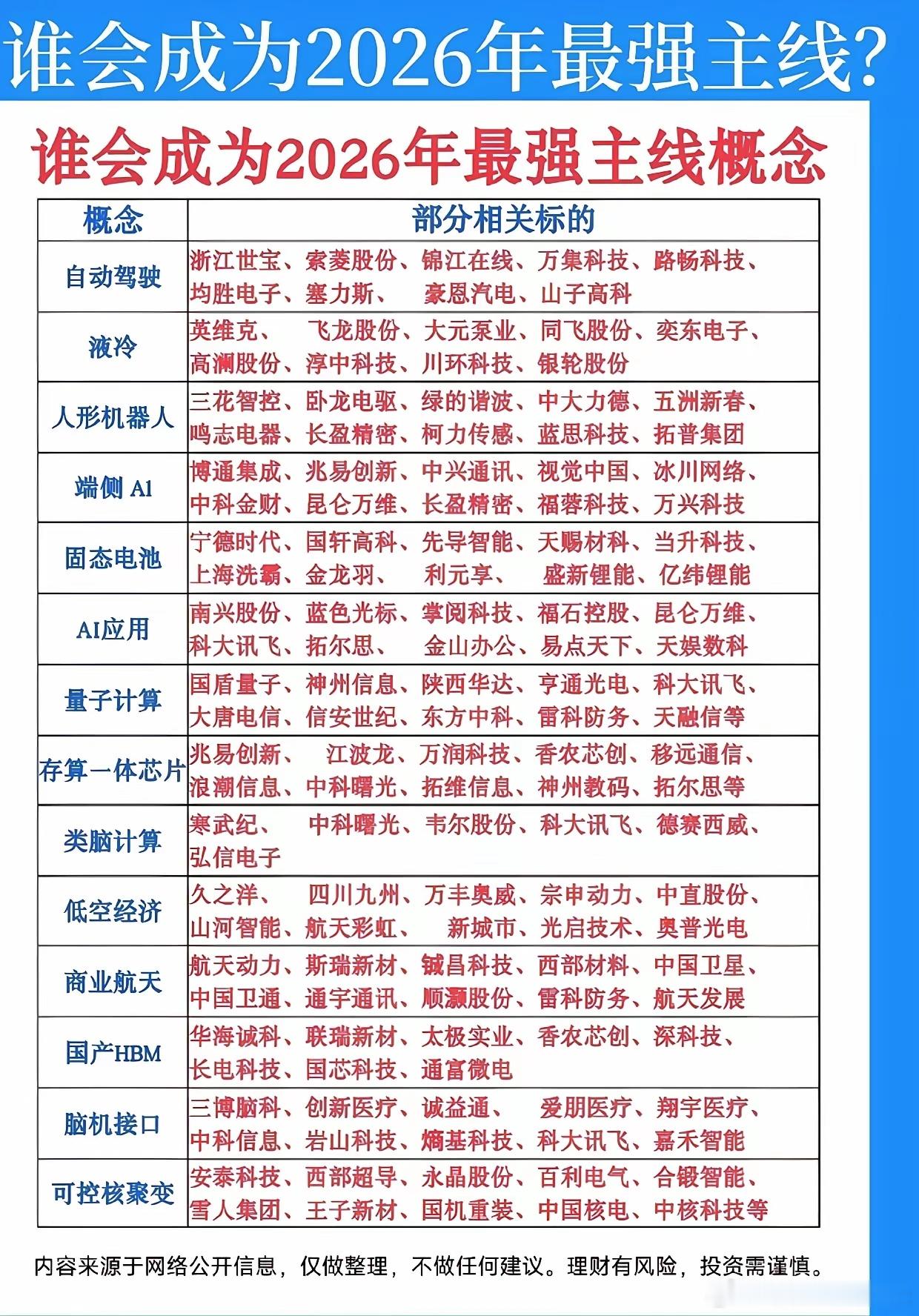
梁文锋又冲上热搜了! 这次既不是团队内讧也不是技术翻车, 反倒给AI圈扔了颗惊雷。而是他们居然又 开发了新的模型!1月21日外媒曝光,梁文锋在DeepSeek发布推理模型R1一周年之际,新模型“MODEL1”的项目名在开源社区悄然出现。 1 月 21 日,正是 DeepSeek 推理模型 R1 发布一周年的日子。没有铺天盖地的宣传,没有明星嘉宾站台,甚至连官方一句预热都没有,有开发者在 GitHub 翻代码时,突然发现了一个陌生的名字:MODEL1。 它就安安静静地藏在百余份核心代码里,和现有模型关联引用,不声不响,却自带惊雷气场,一曝光就炸懵了整个 AI 圈。 很多人说,这就是一次普通的模型迭代,没必要大惊小怪。但懂行的人都清楚,这根本不是偶然,是梁文锋蓄谋已久的布局,更是一次对着 AI 圈内卷乱象,明目张胆的 “反杀”。 现在的 AI 圈,早就乱成了一锅粥:国内同行拼尽全力比谁的参数多、算力猛,动辄喊出 “千亿参数”“万亿 tokens” 的口号,发布会开得比演唱会还热闹,可实际落地能力拉胯,换汤不换药;还有些企业喊着 “开源普惠” 的口号,实则搞 “伪开源”,核心技术捂得严严实实,只开放一点皮毛,目的就是收割流量和关注度。 再看国外阵营,更是乱中藏险。曾经的开源旗手 Meta,放话要在 2026 年第一季度上线闭源的 Avocado 大模型,彻底抛弃自己坚守的开源路线;而一直走纯闭源路线的 OpenAI,反倒开始松动,偷偷开源轻量级模型,试探稀疏化技术的市场反应。 开源和闭源的边界彻底乱了,大家互相试探、互相模仿,唯独没人静下心来,好好做技术、做真正能落地的模型 ——这就是当下 AI 圈的真相,浮躁又荒诞。 而梁文锋,偏偏反着来。别人忙着高调造势,他偏要低调藏拙;别人忙着堆参数、炒概念,他偏要扎进技术里,拼效率、做实事。这一切,从 R1 模型就能看出端倪。去年 1 月,R1 横空出世,没有高调官宣,却凭实力出圈:四千万人民币的训练成本,就实现了比肩国际顶尖模型的性能,推理成本低到每百万 token 只要 1 块钱,直接打破了 “算力决定上限” 的行业迷信。 上线至今,R1 在全球最大开源平台的下载量,已经突破 1090 万次,相关研究论文还登上了《自然》封面,完整披露训练细节,用实打实的学术背书,打了那些 “伪开源”“伪创新” 企业的脸。 有人说,R1 已经够成功了,DeepSeek 安安稳稳吃红利就好,没必要再冒风险搞新模型。可梁文锋偏不,MODEL1 的出现,从来不是 R1 的简单迭代,而是他跳出内卷、改写 AI 圈竞争规则的关键一步,更是对当下全球 AI 竞合局势的精准预判。 从曝光的代码能看出,MODEL1 完全走出了差异化路线:它延续了 R1 的效率优势,加入了全新的解码模块,同等参数规模下,显存消耗直接降低 35%,跑起来更快、更省资源;同时,它不贪多求全,避开了通用推理的红海,专门聚焦编程、数学这些 R1 已经形成优势的细分场景,实现强强互补,而不是重复内耗。 更绝的是梁文锋的布局思路 — 借 R1 的东风,托举 MODEL1 的成长。R1 这一年积累的,不只是千万级的下载量,更是全球开发者的信任,是 “真开源、重技术” 的口碑。MODEL1 选在 R1 周年庆节点低调露头,就是要借助这份口碑,让全球开发者主动参与进来,测试代码、反馈问题,用分布式创新的力量,快速打磨模型细节。 这种 “不造势、只做事” 的打法,看似被动,实则高明,既避开了同行的针对性布局,又能牢牢抓住开源生态的核心 — 开发者,比那些铺天盖地的发布会,管用一百倍。 当下的 AI 圈,还有一个致命的短板,同质化严重,核心创新不足。国内很多开源模型,看似百花齐放,实则都是模仿国外的技术路线,换个参数、改个名字,就敢号称 “全新模型”,根本没有自己的核心技术,更谈不上商业化落地。 而 DeepSeek 不一样,从 R1 的纯强化学习机制,到 MODEL1 的差异化技术路径,每一步都在坚持自主创新,每一步都在构建自己的开源生态闭环 —— 用学术背书夯实技术根基,用高效模型吸引开发者,用细分场景突破实现落地,最终实现 “技术普惠” 和 “商业可持续” 的双赢。 现在,越来越多的开发者开始关注 MODEL1,越来越多的业内人士开始重新审视 DeepSeek。没人知道 MODEL1 正式官宣时会带来多大的惊喜,但所有人都清楚,梁文锋这一次,又要改写 AI 圈的规则了。毕竟,能在浮躁的行业里守住本心,能在混乱的局势中找准方向,这样的企业,这样的布局,想不脱颖而出都难。