
没有EUV , 使用浸没式光刻机(DUVi) +多重曝光(Multi-patterning) 作5nm芯片是可行的 , 不计代价甚至能做到3nm , 如果单以光刻(Litho)技术来说 , 拿28nm光刻机来作5nm芯片理论上也没问题 , 但这需要满足许多严苛的条件 , 更高的套刻精度(Overlay)只是其中之一 , 制造成本更是无法估量。
目前不论国产7nm还是5nm芯片都跟所谓国产设备没有太大关系 , 即便去年某旗舰手机横空出世 , 上面搭载的7nm芯片被称为全国产芯片 , 但此国产非彼国产,这仅是利用进口设备在国内生产出的半国产芯片。
有网友因该芯片的量产而幻想出国产光刻机已经出现在产线上,很显然是错误的,事实上7nm芯片咱们还是必须以进口设备来生产 , 当然国产设备目前正紧锣密鼓努力攻关中 , 如中微董事长尹总在2024年6月所言 , 先进制程现在的国产化率还是在2成以下 , 所以要利用国产设备生产先进制程芯片还有很长的路要走 , 7nm或5nm芯片的量产说明了国内先进制程的重大进步 , 但并不能代表国产设备的攻关已经完成 , 这是完全不同的两码事 。
9月刚推出炸裂的三折叠屏手机还是继续使用7nm芯片 , 此款超高端手机的销量有限 , 数十万台的级别对芯片的供应没有太大压力。
相比該旗舰手机去年8月底就推出的先锋计划 ,下一代继任者则一延再延,推迟到今天18号才正式预约,预约结束后的26号才开始发售,也不知道这预约是啥意思?不需要任何押金只要上商城就能任意预约,为啥不直接开卖呢?总感觉有点推延时间的味道。
可想而知,11月26号正式公布价格发售后,要拿到手机还得是一个非常漫长的过程,这是为什么呢?主要是两个原因一个是纯血OS系统的delay,另一个则是N+3芯片的产能与良率都出现问题。
从笔者了解的N+3芯片产能,10月份才调适到位开始少批量生产,良率目前笔者还没看到,但预计跟N+2初期一样在30%以下,随着明年良率的学习曲线拉升,笔者预估全年产能在1000万颗左右。
对于下游应用端,笔者不清楚品牌方会如何利用芯片去搭配各种型号的手机,但从总量上来看,N+3生产的手机SOC因为只有1000万颗/年,有限的产能大概率很难被M系列手机全面搭载,因为M系列旗舰手机销量应该会高于千万台,而且2025年中要推出的全新P系列高端机也要搭载N+3芯片,所以笔者的推测是M系列的基础机型会继续采用7nm芯片而非5nm,只有中高端机型才是所谓5nm芯片,当然这只是笔者根据产能的一个推测。
在新款旗舰手机上市之前,市场一直传言备货充足,不会再像去年一样因为缺芯而出货缓慢,消费者得高价抢手机或者等好几个月,这说法一半对一半不对,如果备货充足那自然不需要一延在延,备货充足的是7nm芯片,所谓的5nm芯片还是得抢破头,等手机真上市之后就会证明所谓备货充足是真还是假了,我可以肯定还是会有一堆人抢不到或等太久而骂娘。
对于今年N+2与N+3的产能有多少可以供应多少M系列以及明年的P系列 , 作者知识星球有详细的数据 , 今年年初市场所有预估都是该品牌手机重新回归,并且销售将达到7000万台以上 , 分析机构从供应链端甚至有超过一亿台的乐观预期 , 年初整个市场只有作者依照芯片产能与良率推算较乐观为4千万颗芯片的供应量 , 所以今年加上高通库存 , 合理全年该品牌手机总销量会在4500~5000万左右 , 明年可以供应SOC的芯片产能 。
从上游的芯片制造端我们不太清楚具体手机型号与芯片的搭配 , 本文章主要探讨如何用DUV+多曝来生产5nm芯片以及相关产能以及良率 。
如何用DUV来生产先进芯片 , 这里面有许多定义问题 , 比如行业里并没有所谓28nm光刻机 , 这只是为了给非业内的网民一个比较直观的说法而已 , 28nm光刻机泛指的是ArFi也就是大家所说的浸没式光刻机 , 事实上以目前的半导体技术28nm光刻机做7nm甚至5nm完全可行 , 但这并非单单依靠多重曝光 , 还有许许多多的制程手段 , 比如早期一点的PSM , 模型OPC校正 , Multi-patterning(LELE、SADP等), overEtch , ILT反演光刻 , 甚至最新的DSA技术在不依赖更高分辨率光刻的情况下也有机会生产5nm芯片 , 当然这么做需要高昂的代价 , 正常Fab厂不会采用如此极端的手段来生产 , 目前所熟知的技术都是经优胜劣汰筛选过最符合成本的制造方式 , 但不代表是唯一技术可行路线 , 也就是说即便没有最先进的EUV光刻机利用国外进口次一级设备在国内芯片工厂制造的”国产”5nm芯片正在来的路上 , 虽然与去年上一代相比推出时间出现了延误但大家稍安勿躁 , 该来的肯定会来。
大家都清楚西方对我国的EUV光刻机实施禁运 , 所以用什么样的制造方式才能让DUV光刻机能”较好的”生产5nm芯片 , 这将是我国半导体行业的重中之重 。
明年2025年全球将进入2nm时代 , 2027年台积电将推出2nm之后的1.6nm版本A16 , 2028或29年进入1.4nm节点几乎也是确定 。
网上所谓芯片性能已经过剩 , 7nm或者更高制程的芯片并不急迫的说法有很大的错误 , 因为5nm并不是只有手机上使用 , 超算或数中心的高性能运算 , 甚至更重要的AI芯片全部都需要先进的制造工艺 , 未来的AI时代算力代表着国力 , 从这一点看来 , 被严重制约的我国芯片行业形势严峻 。
所以如何利用我们手上被限制的芯片生产设备去生产更高级别的芯片就成为了我国半导体行业发展的重点方向 , 另外在从芯片结构设计上去优化比如提早进入GAA工艺 , 以上所有方法都是建立在芯片制造技术上 , 所以提升我国芯片制造工艺是当务之急 , 同时要发展的还有国产设备 , 但7nm的全国产化设备还需要不少时间 , 我们必须继续提升芯片制造技术(包含良率以及提升工艺节点)来帮国产设备的攻关争取更多时间 。
下面我们就来聊聊如何使用DUVi级别的tool来生产7nm甚至更先进的5nm芯片 。
芯片是怎样炼成的
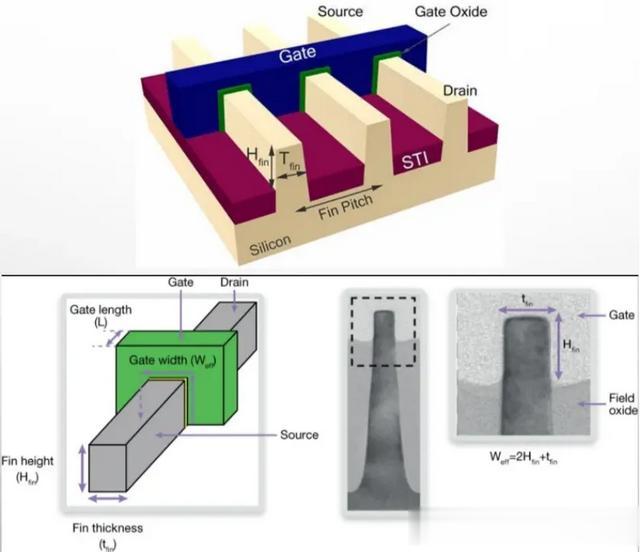
IC的微缩 , 除了利用光学微影(Optical Lithography)也就是俗称的光刻来缩小线宽以外 , 沉积(Deposition)、刻蚀(Etch)、扩散(Diffusion)等也是核心制程 , 再加上缩小线宽以外的技术比如更复杂立体的FinFET、Nanosheet结构也同样发挥至关重要的作用 , 毕竟半导体节点(Nodes)早在十年前的14nm以下就是等效的概念 , 而非传统意义的线宽。
想要搞清楚DUVi + Multi-patterning到底能否做到5nm这件事 , 我们还是需要先厘清什么是5nm , 衡量元件尺寸的关键指标之一为「晶体管栅极长度」(Gate length), 这个数字与 IC 速度直接相关。以场效晶体管来说,栅极长度愈小,电流可以花更少时间通过晶体管的漏极和源极 , 这就是为什么节点(线宽)越小 , 芯片性能越高的理论依据。

图1:MOSFET场效晶体管平面结构示意图
如果要表示元件微缩的程度,另一个关键指标为周距(Pitch) , 通常以金属层线与线的周距为参考基准 , Pitch做得愈小 , 线宽也愈小 , 元件微缩程度愈高 , 但线宽并不能作为衡量晶体管密度的特征参数 , 线宽虽然很小 , 如果间距很大 , 单位面积可以容纳的晶体管数目依然很少 , 所以在行业内Pitch的概念比线宽来的更重要一点。 国内大部分媒体把Pitch翻译成间距 , 个人感觉不是那么准确 , 因为间距应该是栅极跟栅极的距离 , 用周距来表示可能会好一点。作者用最简单的示意图让大家可以清楚直观的看出什么是线宽与周距。

图2:线宽/栅极长度、周距与半周距的关系
芯片制程节点的意义
90年代的0.35um以前 , 芯片的节点与半周距(Half-Pitch)与栅极长度(Gate length)均一致。Node突破点35之后 , 半周距与栅极长度继续微缩但与节点已出现分歧 , 2005年进入65nm节点主要是依靠ArF光刻机数值孔径(NA)从0.85到0.93的提升 , 再往下到45nm就是ArFi浸没式光刻机的出现才使半周距继续下降 , 45nm以后光刻机的分辨率一直停留在38nm(DUVi)止步不前 , 随着PSM , LELE , SAMP一系列降低k1值的办法陆续出现 , 在光刻机不变的情况下 , 工艺节点顺利推进到7nm , 直到波长13.5nm的EUV光刻机 , 才将分辨率推升到10nm左右 , 并继续搭配SAMP技术将节点往下微缩 , 从下面的图表我们可以清楚看出节点 , 半周距与栅极长度的关系与演变。
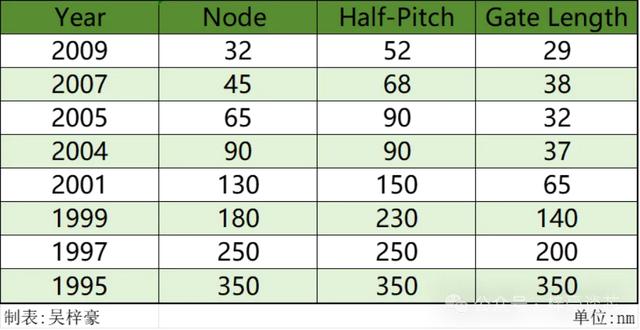
传统半导体科学再书本上学习的所谓多少nm节点就是指Gate length的尺寸 , 经历几十年的演变 , 制程的越复杂化 , 单用一两个关键尺寸(Critical Dimension)来解释经典COMS的微缩有点力不从心 , 如今多少nm节点的说法是指象征的意义 , 而不再代表任何实际物理尺寸 , 这样的情况20年以前就开始发生 , 所以许多朋友总是喜欢说现在各家半导体大厂宣称的多少nm工艺都是营销话术 , 这说法虽有其道理但同样也不明所以 , 严格意义上早在20年前所有节点都已是营销话术。
如上所说早在20年前就开始出现等效的概念 , 而10年前行业进入14nm 的FinFET立体结构时代就彻底地打破节点线宽的概念 , 没有统一的标准自然会被商家拿来玩文字游戏模糊概念 , 三星在14nm首开先河 , 台积电为了不落人后马上跟进 , 还羞答答的定义为16nm , 只有Intel傻傻地自许为坚定的摩尔定律追随者 , 在三星首开先河的第十年 , 也就是英特尔吃了十年大亏之后才改变死嗑传统线宽的命名方式 , 真实线宽的争论在2021年Intel全面修改节点命名跟随台积电之流的同时画下了句话 , 现在的芯片即便最小的M0、M1的半周距都远远高于节点2倍甚至3倍 , 未来这差距会越来越大 , 但这有问题吗? 其实一点问题都没有 , 毕竟芯片早不是平面而是立体结构 , 如果我们把线宽的概念转化为单位晶体管密度(MTr/mm2)就能一目了然 , 所谓的摩尔定律并没有消亡而是以不同的形态表现 , 即便线宽微缩受限 , 晶体管单位密度仍一直在增加。
如果你还是停留在半导体公司都不讲武德 , 虚标线宽都是搞营销的认知 , 那只能说你对半导体的一知半解 , 摩尔定律至始至终都没有定义任何尺寸 , 而是定义晶体管数量每18个月提升一倍 , 线宽只是几十年来行业的惯例沿用 , 线宽每减少0.7倍 , 面积就减少一半(0.7*0.7) , 单位密度自然提高一倍 , 所以我们看到的节点 , 每一代都比原本减少0.7倍 , 比如14nm、10nm、7nm等。
一种更有效的对比方式 : 单位晶体管密度(MTr/mm2)
针对晶体管的各种尺寸多而复杂 , 每一种尺寸也都有它的意义 , 每个厂商对于制程尺寸都有不同的定义设计 , 所以不同厂商相同制程工艺的产品也不完全具有可比性。
目前能清楚并直观的横向比较各家制程差异的唯一办法就是回归摩尔定律的本质 , 直接比较晶体管密度 ! 我们要找出那一家偷鸡哪一家营销不再是比线宽节点 , 而是晶体管密度。
下面的图表将可以让大家对主流Fab在各种节点的尺寸与晶体管密度变化有直观的比较 , 这张表将能让你对半导体行业有一个全新的认知。

备注1 : "CCP: 接触栅极间距" , "cell height: 单元高度" , "Fin Pitch: 鳍间距" , "MMP: 最小金属间距" , "MTr/mm2: 每平方毫米百万晶体管数量 "
备注2: N+2网传为98MTr/mm2 , 但根据TechInsight的麒麟9000s拆解报告 , 实际MTr为89而非98 , 2024下半年量产的N+3根据作者了解为120左右 , 约为台积电N6或N7+水平,与真正的5nm(180Mtr)差距很大。
备注3: TSMC 从3nm开始采用PPA也就是功耗(Power)、性能(Performance)和面积(Area)来阐述芯片制程的提升 , 密度仅作为辅助数据 , 旧的MTr路线图不再适用 , 3nm的MTr仅供参考 , 今年推出的N3E PPA高于去年的N3B但晶体管密度却更低 .
从上图我们可以直接比较全球主流Fab在先进制程中单位晶体管密度的不同 , 在14nm时代不论英特尔、台积电、三星或者慢了5年量产的中芯国际 , 单位晶体管数量都是在0.3亿每平方毫米左右 , 最先宣布量产为2014年的龙头大哥大英特尔 , 紧追其后的是梁孟松竭力扶持的三星 , 这时的三星挟memory霸主地位 , 由梁孟松坐镇硬闯logic并激起一池春水 , 台积电在更早之前的28nm逆向投资大获全胜 , 成功挤入竞争圈 , 此时也如小媳妇般的跟随三星把应该叫22nm的节点改为16nm , 而联电与GF眼见大势已去 , 宣布14nm以后不再研发先进制程 , 退出这钱多烧的慌的游戏。
10nm时代开始出现分化 , 首先英特尔将原本的14nm+++改为intel 10 , 这一改 ,名字是跟上了 , 但晶体管数量却成了倒数第一(见上图) , 而三星则是在10nm的优化版8nm才提升至与台积电大致水平 , 稍微领先的台积电此时已具备王者之姿 , 蓄势待发。 中芯国际采用SATP技术的N+1与大厂10nm的晶体管密度相比只稍微落后一点 , 量产时间则还是维持5年的差距(2016/2021) , 这个N+1你可以叫他14nm优化版、10nm、8nm或者7nm先期版 , 什么叫法都行 , 毕竟这些叫法都是厂家自己定义的 , 没有统一标准 , 比如从上表我们可以看出三星在10nm之下自己还加了个8nm , 但还是属于10nm , 这里也解释了为何你永远搞不明白各家工艺节点如此混乱的原因。
2017年台积电利用1980 DUVi光刻机+SAQP四重曝光技术率先量产7nm , 三星在隔年以更先进的EUV光刻机应战 , 但失去了先机 , 加上对EUV光刻机的熟悉不足 , 良率低下 , 最后以自家三星手机放弃自家猎户座芯片转而搭载高通芯片以及比台积电低30%的价格的屈辱条件才免强留下大客户高通 , 老大哥英特尔这时候还在挤14nm+++的牙膏步履蹒跚 , 疲态尽显 , 7nm一役台积电大杀四方 , 奠定了半导体王者地位 , 摩尔定律引领者英特尔跌落神坛。
台积电7nm从DUVi的N7、N7P到EUV的N7+及N6共四个版本 , 晶体管密度从0.91提升到1.16亿 , 三星为0.95亿 , 英特尔则骂咧咧的在2年后的2020年才量产1亿体管密度并高喊我才是正统的intel 10nm , 并大骂台积电三星不讲武德以次充好的假7nm , 但这何尝不是英特尔恼羞成怒的吶喊 , 不管名字如何叫 , 单论晶体管密度或量产时间 , 英特尔确实落后了 , 名字成了英特尔最后的遮羞布 , 在英特尔生产出晶体管密度达1亿的真7nm时 , 台积电已先一步帮华为生产出全球首款5nm手机芯片晶体管密度达1.5亿+的麒麟9000。
国内最大Foundry厂在台积电量产7nm的5年后用更先进两个世代的2050i光刻机+SAQP成功量产N+2也就是7nm , 大量出货则在隔年的2023年 , 使用了套刻精度比台积电1980ci更高两个等级的光刻机但良率却还是有不少差距 , 这几年来国内最大Foundry厂一直保持与全球领先者5年的差距没太大变化 , 未来到底是能拉近还是扩大 , 值得关注。
5nm时代在2020年到来 , H推出的颠峰之作全球首款5nm芯片由台积电代工 , 三星同年也宣布量产5nm , 著名的高通火龙888芯片横空出世 , 从此高通心死转向台积电生产旗舰芯片不再贪图便宜 , 此时与三星合作的高通 , 被跟台积电合作的联发科 , 海思以及苹果打的落花流水 , 火龙888成了压垮骆驼的最后一根稻草 , 2015年苹果A9芯片门也让苹果将原本三星台积电各半的订单 , 从此全部交给台积电 , 历史再一次重演 , 这些事件关注半导体或通讯行业的朋友或许耳熟能详 , 而根据作者统计的表格对比 , 我们发现了一些不为人所熟知的情况 , 三星的5nm其实只是7nm的升级版 , 仅仅只有1.27亿的晶体管密度甚至最终改良版1.37亿的4nm也远远不如台积电初代5nm的1.5亿 , 与台积电1.8亿的5nm改良版N4P差距更大 , 更离谱的是三星刚宣布量产的所谓3nm , 晶体管密度竟然不如台积电上一代5nm的最低版本 , 很显然从5nm开始三星已经掉队 , 这正好解释了为何高通从5nm开始将旗舰芯片放在台积电的疑问 , 三星的5nm与3nm是完全靠名字撑场面的假节点 , 梁孟松在14nm帮三星建立的优势已荡然无存 , 转而报效祖国的梁孟松持续发力14nm、 N+1、N+2快速的突破让国内最大Foundry厂保持与全球领先者的距离没有被甩开。
全球三大的制程节点量产时间表

备注1: 32/28nm与14nm之间依照技术路线图还有一个22nm
备注2: 2022年底TSMC 3nm已完成风险试产 , Ready状态
备注3: 三星在2010年32nm在这个logic节点是落后Intel与TSMC , 梁孟松加入后突飞猛进在14nm对台积电进行反超 , 梁孟松前台积电研发处长 , 师承前台积电技术长世界FinFET之父胡正明 , 2011年入职三星
2021年当了十年大冤种的英特尔再也坐不住 , 宣布全面改名节点 , 英特尔10nm改成intel 7 , 原本的7nm改成intel 4 , 并把后续节点细化成了intel 3、intel 20A、 intel 18A , CEO基辛格宣布了4年5节点的宏伟计划 , 当时笔者瞠目结舌 , 4年5个节点? 这可是摩尔定律的3倍速度 , 但看看笔者整理的表格 , 仔细推敲 , 我们会发现英特尔鸡贼的将原本的4个节点细化成5个 , 而intel 7这节点是他原本就能量产的10nm , 所以这5年实际上他真正要攻克的是3个节点 , 但即便英特尔完成这个不可能任务 , 最终其intel 18A的晶体管密度也不如台积电的2nm , 吊诡的是最终玩弄文字游戏的反倒成了英特尔 , 这里咱们又解开了一个许多人当初搞不明白的疑问 , 当然论节操英特尔还是不及三星 , 完全落后一整个世代的晶体管密度 , 确实只有三星不会脸红。
根据作者与台积电与英特尔的了解 , intel 18A进度大概率要delay , 至少得2026年或者更久 , 而2025年底台积电第一代的2nm是可以低良率产出 , 但2025年台积电2nm会不会有客户不确定 , 目前苹果正在犹豫中 , 去年苹果A17就是急着搭载第一代3nm 也就是N3B的升级效果不明显 , 我们从表中可以对比出N4与N3B是1.8亿跟1.9亿的单位晶体管密度 , 数据说明物理晶体管提升幅度真的很小 , 所以苹果可能会改变打法 , 不着急使用第一代2nm , 而是让台积电继续深挖3nm潜能 , 比如今年苹果A18将用上N3E , 虽说跟去年的A17都是3nm , 但根据作者的表格可以看到晶体管密度的提升 , 对比其他竟品都在1.8亿以下且都是良率很低的小批量生产 , 我想所有想在侧端发力AI的手机芯片 , 台积电N3E是唯一选择 , 高通的8 gen 4与联发科的9400扎堆台积电3nm , 由此可以看出来这些大厂不得不下单台积电的无奈 , 高端手机芯片不使用台积电的制程就没有竞争力 , 这意味着失去市场。
从上面的表格我们可以清楚看出 , 2024年全球三大半导体制造公司同台竞技的最先进节点分别是1.8亿晶体管密度的intel 4、 2亿的台积电N3E以及1.5亿的三星3GAE , 熟强熟弱一眼就能分辨 , 不管你号称多少nm穿着什么马甲! 未来比较各家制程节点好坏就是换算成单位晶体管密度 , 聪明的你是否get到了!
有一个现象是值得我们注意的那就是摩尔定律的节点推进时间从原本18个月到24个月 , 进入7nm以后则是延缓到30个月 , 2018年量产7nm , 2020年量产5nm , 2023量产3nm , 2025量产2nm , 大概为3年推进一代的轨迹 , 节点推进时间拉长这个趋势在未来会继续 , 以目前可知技术来看到1.4nm还能保持目前速度 , 1.0nm往后节点拉长到40个月以上是大概率 , 但这只是线宽微缩的放缓 , 未来凭借各式各样的先进封装技术 , 在可以确定的20年内 , 芯片晶体管的总数将持续快速增长 , 甚至在单芯片功耗上超越原本的摩尔定律 , 比如3月份台积电的刘德音与黄汉森在IEEE发表的文章 , 计算出不用十年 , 人类就可以制造出一万亿颗晶体管的GPU单芯片 , 未来不再是只通过制程改善这单一手段来提升晶体管数量 , 立体结构的优化、2D新材料以及先进封装每一个技术都能有效并持续的提升晶体管数量。
有兴趣的可以去IEEE看下这篇文章 How We’ll Reach a 1 Trillion Transistor GPU - IEEE Spectrum

比别人更早的量产时间是英特尔、三星、台积电三强竞争的重要关键 , 谁先量产就能掌握先机 , 但现在各家对节点定义的差距巨大 , 你说你量产5nm我也说我量产5nm , 但实际上晶体管密度却比别人上一代还不如 , 从作者的表就能看出 , 三星在这块玩得炉火纯青 , 甚至让非业内人士不明所以的认为三星是台积电强力的竞争者 , 其实三星已不再竞争行列 , 真正对台积电还有一点点威胁的是英特尔 , 但对比两者的晶体管密度差距 , 英特尔基本上也掀不起太大风浪。
三星一直以来还有个玩法就是在良率上动手脚 , 这是包含许多业内人士都会搞混的一个高级玩法 , 一个新节点多少良率才算是达到量产水平 , 这是最说不清的环节 , 以台积电为例都是以有外部客户愿意为此良率下单并顺利产出才称为量产 , 这就是所谓的商业量产 , 而三星每个节点的第一个客户都是自己内部的三星电子 , 低良率的风险试生产 , 三星也可以对外宣称量产 , 所以我们经常可以看到三星总是提早台积电半年宣布新节点量产 , 但客户却永远都下单给更慢量产的台积电 , 这其中的奥妙就是晶体管密度跟良率 , 只要Yield不是0 , 将研发中不到个位数良率的节点宣布量产 , 也没人知道真相 , 但这么做也只是为了宣传不会有任何实质意义 , 因为客户不傻 , 良率不足的坏片惯例是由客户承担 , 同等密度情况下肯定是优先下单给良率最高的Foundry。在密度跟良率都落后的情况下 , 追赶者除了将每片代工价格降低以外 , 还得承担客户因自身良率不足的坏片 , 三星即便在这样的条件下也只能拿下零星订单 , Foundry厂这么干是没有任何赚钱的可能性。
同样情况的还有国内的Foundry , 以还在风险试产的良率宣布量产 , 后面再慢慢拉抬 , 以7nm来说 , 在经过两年的良率拉升之后 , 根据作者在下游手机芯片封装厂的实际good die计算 , 2024年国内7nm真实良率只有45~50% , 当然未来还有拉升空间 , 但两年拉到5成的良率确实有点不尽人意 , 相关厂家有时候会透露自己良率已经到60甚至70 , 其实他们也没说谎 , 70%的良率只是矿机ASIC这种简单芯片的良率 , 手机SOC则还不到一半 , 如果是GPU那从国内做CoWoS先进封装的厂家了解到是0~20% , 并非能一直稳定在20%而是有一大半wafer良率是0,这也是行业的猫腻之一 , 同样的7nm生产不同产品 , 良率是截然不同的 , 但厂家可能只告诉你最好的那个 , 想搞明白半导体行业的朋友这一点也得拧清楚。
国内Foundry良率不高其实问题也不大 , 半导体是国内重点扶持的科技产业 , 尤其是先进制程 , 生产芯片最大的成本也就是设备 , 很大一部分受到地方政府各种形式的补贴(设备折旧摊提占每片芯片制造成本70%+) , 生产成本中最大头减轻了 , 所以即便良率低最终还是能有不错的业绩与利润 , 补贴跟保护让国内不具备国际竞争力的芯片制造业在追赶阶段也能获得足够的利润并持续投入 , 如此一来才有机会追赶领先者 , 要不然在这只有赢家通吃Winner take all效应明显的半导体制造业 , 老二经常连汤都喝不上。
虽然我国的半导体行业在面临西方限制下还能有如此强大的发展能力确实是令人赞叹 , 但技术这条路必然是一步一脚印走出来的 , 毫无疑问勤奋的中国有比别人更快的推进速度 , 别人搞三年我们一两年 , 但良率这些问题牵涉千千万万的参数甚至牵涉一个国家的机械、化工、材料跟仪器等基础科学 , 这都是需要时间积累也就是不断的试错才能一步一步完善的 , 大家还要明白的一点目前我们中国半导体行业的成就甚至所谓突破封锁都是建立在西方的技术之上 , 也就是想尽各种办法拿到西方的先进设备与材料 , 虽然这几年大力发展国产替代 , 但先进制程谈全面国产替代还真的是太早 , 即便所有行业内的人充满信心 , 并在各自领域没日没夜的干着 , 我们确实开发了不少先进制程的替代产品 , 但很多人包含那些只负责自己一亩三分地努力攻关的工程师们都忽略了很重要的一点 , 即便我们完成了现在手上的所谓技术攻关 , 兴高采烈之余 , 回顾四周我们还是会发现 , 在这供应链极度之长的半导体制造领域 , 敌我双方的差距依然没有减少太多 !
千辛万苦用许多尖端进口零部件把国产设备做起来 , 结果核心的零部件被禁了 , 需要从零部件开发重新做起 , 千辛万苦弄回来了先进光刻机 , 结果光刻胶被禁了 , 维修被禁了 , 专门用来校正光路的special tool 别人不给了 , 光刻机成了废铁 , 自研光刻胶除了强大的化工材料基础还得要进口的顶尖分析仪器 , 这一切的一切都必须建立在西方的技术之上。 作者一直以来强调认识差距 , 努力追赶 , 或许有些人会认为作者泼冷水 , 唱衰 , 但中国半导体更需要的是客观与事实 , 甚至是监督 , 而不是无脑捧杀最终一地鸡毛 , 从中赚钱的人盆满钵满 , 中国半导体行业折腾一圈还是原地踏步 , 这是作者最害怕看到的结果。
对于国产替代去年作者写了不少文章 , 去年至今也看到了许多同行的努力与成果 , 我之前的分析到现在看来基本也没啥大变化 , 不过目前中国半导体所取得的成果是令我一个20多年经验的半导体人难以想象的 , 确实在这20年来全世界都没有人以咱们这样的方式干过半导体 , 完全超越了作者既有的认知 , 但这样的好也没有网络上各种小作文胡说八道的那般 , 一切还是需要时间 , 这不会是短短二三年之功 , 国内的半导体行业缺乏的是真正具备全面宏观的产业能力以及愿意客观事实说出来的人 , 这对国人来说是一件憾事 , 有幸去年作者的多篇文章被中央部委主办的国家级刊物认可与发表 , 也算替我国的半导体行业发展尽了一份微薄之力。
回到正题 , 简而言之 , Fab厂的量产时间与良率是一个可以大做文章的模糊地带 , 大家必须清楚这里面的关系才能看明白半导体行业 , 这绝非简单的同比 , 不论海外巨头或者国内都一样 , 目前能参考的标准只有台积电标准 , 行业也必须有个标竿才好去横向对比 , 最好的晶体管密度以及真正可以拿到商业客户订单的量产时间与良率才叫商业量产 , 其他只有内部客户的宣称或者依靠非市场的补贴跟真正的商业量产差距到底有多大 , 非当事人很难窥一二 。
目前制程节点的同比已经失去意义 , 比如2020年三星宣布比台积电更早量产5nm芯片 , 看似三星赢了 , 但一比较两者晶体管密度与良率 , 我们会得出完全相反的结果 , 这就是半导体行业的重大秘密 , 希望大家看完我的文章能对此有多一份理解 , 不然你只能在各种蒙逼之中对半导体行业的认知偏差越来越大。
摩尔定律已死?
70年代 , IEEE和电子工程师协会设立了一个叫ITRS的组织 , 他们每年都会发布一份半导体技术路线图——ITRS路线图。 但在2017年 , IEEE停止更新ITRS , 并将其重新重命名为IRDS , 因为原本的方式已经不合时宜 , 至此摩尔定律用不同以往的方式延续着 , 诸如IRDS在2020提出的More Moore , 其中很重要的PPAC概念 , 即每2-3年P(性能)提升15% , P(功耗)减少30% , A(面积)减少30% , C(成本)晶圆成本增加少于30% , 包含业界提出的Moore than Moore和Beyond COMS 都将在后摩尔定律时代发光发热并不断的持续提升芯片性能。
各位喜爱半导体的朋友们 , 以后请不要再说摩尔定律即将消亡 , 这是一个天大的谬论 , 经典COMS的线宽微缩确实未来空间不大 , 但通过制程改善(High-NA、 Hyper-NA EUV)、2D材料、立体结构改善(GAA、FSFET、CFET)等多种技术 , 再加上无穷无尽可能性的先进封装 , 这些手段都能确保半导体在2nm之后进入A14(1.4nm)、A10、A7、A5、A3到A2。
从下面IMEC的路线图我们可以清楚看出来 , 即便线宽不再微缩 , MMP一直停留在16nm利用更加复杂的立体堆栈也可以将摩尔定律推进到0.2nm , 所以那些整天期盼摩尔定律停止 , 未来我们将有大把时间追赶的谬论 , 真心希望可以停止 , 现已不是大清朝 , 缺乏基本常识的反智言论犹如义和团的刀枪不入 , 庙堂之上如果真听信这些胡说八道 , 那未来谈何希望?

非EUV路线的5nm制程
对半导体感兴趣的朋友都会高度关注光刻机 , 由台积电研发副总林本坚博士提出的浸没式技术并与ASML合作开发出的ArFi光刻机几乎是半导体历史上横跨节点最多的机型 , 从45nm、28nm、14nm、10nm、7nm经历5个世代 , 甚至未来还能继续突破到5nm甚至3nm , 用ArFi做5nm芯片必然是没多少商业价值的方式 , 但这对被西方限制EUV的我国来说确实是一剂良方。
我们从林本坚的讲座可以了解,到底如何用非EUV来做5nm芯片 , 这一切让我们先从一个核心的光学分辨率公式开始:这公式看起来唬人但只是简单的乘除 , 大家可以一起来算算 , 真心一点都不难
半周距(Half Pitch)= k1λ/sinθ
² Half Pitch:一条线宽加上线与线的间距后乘以 1/2。分辨率高时 , Half Pitch做得愈小 , 意味着线宽可以愈小。
² k1:与制程有关的系数 , 缩小Half Pitch的关键 , 这是所有半导体工程师致力缩小的目标 , 一般为0.28。
² λ:光刻制程中使用的光源波长 , 从一开始g-line的436 nm , 现已降到EUV 的13.5 nm , 这是光刻机制造商努力的目标。
² sinθ:与物镜聚光至成像面的角度有关 , 基本上由物镜决定 , 这也是光刻机制造商努力的目标。
算例 : 193nm波长的ArF光刻机半周距(分辨率)计算为 k1(0.28) * 193(波长) / 0.93(数值孔径, 参考ASML数据) = 58nm(分辨率,半周距) , 根据算例我们可以了解ArF也就是干式DUV光刻机最低可以曝光58nm特征尺寸的图形 , 意思就是最低能做58nm的芯片 , 以节点来看干式DUV就是能到65nm的光刻机

光线通过透镜系统聚焦成像示意图 , n为介质折射率 , θ为物镜聚焦至成像面的角度。
由于光在不同介质中 , 波长会有所改变 , 因此我们在考虑如何增加分辨率时 , 可将物镜与成像面(Wafer)之间的介质(折射率n)一并纳入考量,将λ改以λ0/n 表示,λ0是真空中的波长。
半周距(Half Pitch)= k1λ0/n sinθ
因此, 增加分辨率(减少半周距)的努力有四个方向:
v 增加 sinθ(聚光角度)
v 降低 λ0 (波长)
v 降低k1 (工艺系数)
v 增加n (介质折射率)
另一方面,为了让光刻有足够大的曝光清晰面积,物镜成像的景深(DOF)数字愈大愈好(DOF=k3λ/sin2(θ/2), k3是因应高 NA 值的曝光镜头所引入之系数) , 但是DOF变大的副作用是——Half Pitch也会跟着变大 , 因此在制程改良上必须考虑两者的平衡或相互牺牲 , 目前大芯片如GPU都已经达到光罩上限 , 极限曝光面积带来的分辨率问题对良率产生很大影响 , 所以GPU的良率都不高的原因就在这里。
增加 sinθ:巨大复杂的物镜sinθ 与物镜聚光角度有关 , 数值由物镜决定 , sinθ愈大 , 分辨率愈高。光刻机所使用的镜头 , 并不如我们平常使用的相机或望远镜那般简单——而是由非常多大大小小、 不同厚薄及曲率的透镜 , 经过精确计算后 , 仔细堆栈组成的(如下图)。

光刻机的物镜设计相当复杂 , 图中为例 NA = n.sinθ = 0.9 , 空气折射率 n 约为1 , 故此镜头 sinθ为0.9 , 数值孔径也就是NA值 , 我们可以从光刻机厂家获取 , 一般媒体会直接引用NA , 作者把NA如何来的公式提出来 , 让读者能直观明白其中组成。
目前光刻机的物镜系统6,000 万美金的镜头已不足为奇 , EUV的物镜系统甚至超过一亿美元。 物镜做得这样复杂是为了尽可能将 sinθ 逼近它的理论极值也就是1 , 目前的ArF光刻机的物镜可将 sinθ值做到0.93 , EUV光刻机则只能达到0.33 , 2024年ASML即将交付0.55NA的 High-NA EUV光刻机 , 0.75NA的Hyper-NA EUV是ASML的终极项目 , Hyper-NA将是EUV的最终章 , 如果没有新技术被发明出来 , 这也很可能是芯片物理光学微影技术的终结。
缩短波长:材料与物镜的精准搭配提高分辨率的第二个方法是缩短波长。 缩短波长主要依靠光源的改变 , 比如g-Line , i-Line的UV(紫外光) , KrF , ArF的DUV(深紫外光)再到目前13.5nm波长的EUV(极紫外光) , 如果波长再短就是X-ray了。在EUV波长区域,并没有天然的材料与机制可以产生激光,现行的13.5nm波长 EUV是以二氧化碳激光照射掉落的锡液滴所激发的次级光源。
可产生EUV光源的办法目前学术界有同步辐射光源、自由电子激光器、放电等离子体(DPP)光源、和激光等离子体(LPP)光源共四种方式 , 30多年前半导体产业界针对这四种方法不断的论证 , 经历可写成一本书的千辛万苦 , 最终ASML代表的LPP路线胜出成为EUV光刻机采用的光源技术 。去年清华的SSMB同步辐射EUV光源项目在国内掀起广泛讨论 , 但很显然就只是对30年前全球产业界早已经论证完成的技术路线的一次冷饭新炒 , 箇中原由作者在之前文章已经有上万字的详细阐述 , 有兴趣的可以去看看。
因为不同波长的光经过透镜后的折射方向不同 , 虽说改变使用的光源 , 就能得到不同的波长因此物镜的材料也必须相应改变。当波长愈缩愈短 , 我们能选择的镜头材料也愈来愈少 , 最后就只剩两三种可以用。
另一种解决问题的方法,则是在物镜的组成中加入反射镜,这样的镜头组合称为反射折射式光学系统(Catadioptric system)。因为不管是什么波长的光,遇到镜面的入射角和反射角都是相等的,因此若能以一些反射镜面取代透镜,就可以增加对光波频宽的容忍度。

上图为波长 193nm的ArF光刻机所使用的物镜模块,从图中可看到在透镜组合之间加入了反射镜。
到了EUV的13.5nm波长时 , 则必须整组镜头都使用反光镜,称为全反射式光学系统(All reflective system), 这种全反射镜的系统,必须设计得让光束相互避开,使镜片不挡住光线。此外 , 相较于透镜穿透的角度 , 镜面反射的角度对误差的容忍度更低 , 镜面角度必须非常非常精准。这大大增加了设计的困难度。
曝光波长的改变还会牵涉到底下的曝光光刻胶 , 光刻胶从化学性质、透光度到感光度等各项特性 , 都必须随着曝光波长的改变而调整 , 光刻胶是个浩大的工程 , 有无数的材料以及配方跟组合去应对不同制程的layer。其中感光速度非常重要 , 是节省制造成本的关键 , 每次曝光多几秒那对芯片制造来说都是不可承受的成本 , 这就牵涉到光源的功率与光刻胶的感光速度。
增加 n:浸润式微影技术在增加分辨率的路上,还可以动手脚的就是物镜与Wafer之间的介质。由前台积电研发副总林本坚提出的浸润式微影技术中 , 将介质从折射率 n~1 的空气,改成n= 1.44 的水(对应波长为 193 奈米的光) , 形同193nm波长等效缩小为134 nm。

干式微影光学系统与浸润式微影光学系统的差异。
浸润式技术让半导体制程可以继续使用同样的波长和光罩 , 只要把水放到镜头底部和Wafer之间就好。 理论很简单但是工程落实却相当麻烦 , 例如DI Water中的空气会产生气泡 , 必须完全移除。另外 , 放进去的DI Water必须很均匀 , 在透光区照到光的水 , 会变得比遮蔽区的水要热一些 , 这个温差就会让DI Wate变得不均匀 , 影响成像 , 为了避免温差,必须让DI Wate快速流动混合,但这又可能会产生漩涡 , 如何让水流快速均匀又不起漩涡?这是个大学问。
作者曾接触过由浙大孵化出配套国产光刻机浸液系统的厂家 , 达到了高精度的液体温控误差正负0.001度的成果 , 但是作为一个20多年的半导体人 , 我想说的是这样静态的成果跟实际生产状况是完全两码事 , 首先温差的取样位置、数量以及时间分别是多少? 更关键的是浸液温控系统是经过光源曝光之后取样量测的吗? 是1小时、 2小时或者是24小时不间断曝光? 每小时曝光频率又是多少? 很可惜的是咱们攻关的单位还只是完成静态成果的阶段 , 要知道ASML浸没式光刻机的Alpha机单单浸液系统在台积电南科专门给ASML的厂区跟林本坚团队修改了7~8回耗时两年多 , 单单一个浸液系统。
Alpha机完成后的Beta还得组织庞大的人力在Fab浪费无数Wafer , 把原本上千个defects , 降到几百个、几十个 , 最后降到零 , 这是一个艰苦的过程。
降低 k1:分辨率增益技术(RET)提高分辨率的最后一条路 , 就是如何降低 k1 , 这个k1则是Fab里Litho工程师们工作的重中之重 , 工程师们从开始至今创造了许多令人赞叹的技术来想方设法降低k1。
我们可以不用制造出全世界只有蔡司一家能制造且天价的EUV物镜系统 , 也可以不用研发全世界都发愁的EUV光源。只要我们的半导体工程师用聪明才智与创造力 , 将k1降下来 , 而这k1就是DUV光刻机能否制作5nm芯片的重要关键。
首先是「防震动」,就好像拍照开防手震功能一样,在曝光时设法减少Wafer和光罩相对的震动,使曝光图形更加精准,恢复因震动损失的分辨率。再来是「减少无用反射」, 在曝光时有很多表面会产生不需要的反射 , 要设法消除。 改良上述两项 , k1基本可以达到 0.65的水平。
提高分辨率还可以使用双光束成像(2-beam Imaging)的方法,分别有偏轴式曝光(OAI)及移相光罩PSM)两种。
偏轴式曝光是调整光源入射角度 , 让光线斜射进入光罩。透过角度的调整 , 可以很巧妙地让这两道光相互干涉来成像 , 使分辨率增加并增加景深。
移相光罩则是在光罩上动些手脚 , 让穿过相邻透光区的光 , 有 180 度的相位差。这两种做法都可以让 k1减少一半 , 不过这两种方法都是用 2-beam Imaging 的概念,不能叠加使用。
国内媒体提到较多的是移相光罩技术 , 却很少提到目前业界主要使用的偏轴式曝光技术,这是有点诡异 , 其实移相光罩除了成本高,更大的问题是不能任意设计图案。k1降到0.28这几乎是上述所有技术所能做到的 k1极限了。
要再进一步降低 k1 , 最终的杀手剪!就是用两个以上的光罩 , 也就是大家耳熟能详的多重曝光(Multi-patterning) 。

28nm光刻机使用的光罩示意图,光透过白色孔照射在晶圆的光刻胶上呈现黄色圆点,借助2个光罩分两次曝光,以实现分辨率的提升
用最通俗的话来说 , 它将密集的图案分工给两个以上图案较宽松的光罩 , 轮流曝光在晶圆上 , 这样可以避免透光区过于接近 , 使图案模糊的问题。 多曝的缺点则是因为曝光次数加倍 , 在WPH不变的情况下 , Wafer产出效率降低了一半 , 而多一次的曝光也将导致良率的降低 , 更低的产出加上更低的良率 , 这对成本是一切的半导体行业来说是不可承受之重 , 因层数增加导致的低产出无可避免 , 工程师们唯一可以挽救的唯有良率。
最终我们根据一开始提供的分辨率公式
半周距(Half Pitch)= k1λ0/n sinθ
再加上ASML的光刻机数值孔径可以得出
ArFi浸没式光刻机的半周距(分辨率)为0.28(系数) * 193(波长) / 1.44(水折射率) * 0.93 (聚光角度) = 40nm
EUV光刻机的半周距(分辨率)为0.28(系数) * 13.5(波长) / 1(真空折射率) * 0.33 (聚光角度) = 11.5nm
从上面算式我们看出 , 浸没式光刻机可以曝光40nm的图形 , 也就是芯片45nm的节点 , 再往下就必须上述的k1系数降低办法
在浸没式光刻机上使用OPC的SMO及其他技术的叠加策略 , 能让k1继续下探至0.2 , 分辨率能达到28nm , 使用SADP双重曝光则k1从初始的0.28降至0.14 , 分辨率则达到20nm。使用SAQP四重曝光则k1降到0.07 , 分辨率达到10nm左右 , 这样的结果甚至比EUV光刻机的11.5nm的分辨率来的更好 , 而这就是DUVi + Multi-patterning可以做到7nm、 5nmg甚至3nm的理论依据 , 网上看到许多DUV利用多曝能否做7nm或者5nm的文章 , 经常会提到诸如LELELE , SAQP等技术 , 但几乎没有人提到这理论基础的由来。

明白浸没式光刻机+多曝是根据什么做到5甚至3nm , 但这仅仅是理论可行 , 真要实践可就没那么简单 , 文前提到多如牛毛的技术 , 其中自对准多曝光SAMP( self-aligned Multi-patterning) 最为重要 , 从公式中我们可以看到它降低k1值的效果最显著 , 而SAMP技术最关键的就是光刻机的套刻精度(Overlay) , 虽然自对准技术比LELELE能获得较好良率 , 但更多重的曝光意味着上下层对准的精度必须更高 , 多一重曝光良率下降必然 , 提高套刻精度的办法除了拿到更高精度的Tool比如2100i光刻机以外 , 每一家Fab掌握的技术也相差甚大 , 能把多台套刻精度(MMO)做到无限接近单台套刻精度(DCO)的全世界仅台积电一家 , 这是基于光刻机性能以外的know how , 这里有两个数据可供参考 , 台积电用MMO:2.5nm的1980ci光刻机+四重曝光良率超过80% , 而国内用MMO:1.5nm也就是高两个级别的2050i同样在四重曝光下 , 经过2年的不断努力也只能接近50% 。
其实IMEC在去年就发布了DUVi SAOP(八重曝光)做5nm的技术方案 , 还有IMEC和Mentor共同创建不需添加任何冗余金属 , 没有额外的电容SALELE(自对准-光刻-刻蚀) , 以及跳脱了传统使用光罩的光刻 , 以材料研发为方向 , 先合成聚合物再加热处理产生特殊的化学交互作用 , 就会自动对齐成为比原来小四分之一结构的「定向自组装技术」(Directed Self-Assembly, DSA) , 国内南方某大厂也申请了SAQP四重曝光的国家专利 , 虽然这专利只是简单地将6,7年前就已经成熟的四重曝光原理介绍一遍 , 没有针对制程细节的实际优化 , 但也说明了国内半导体行业对新技术的追求。
全球半导体研发机构与Fab厂的不断研发探索各种制程新技术 , 海外设备巨头们也没有闲着 , ASML即将推出的High-NA EUV , 让EUV光刻机拥有更高的NA似乎是ASML唯一办法 , 因为EUV太容易被吸收 , 无法像DUV一样用水折射增加n值 , High-NA , Hyper-NA成为ASML提高EUV分辨率的唯一可选项 , 所以Fab制程端可以大幅度降低k1的Multi-patterning就成了不论DUV还是EUV都绕不开的技术 , 而这也意味沉积(Deposition)与刻蚀(Etch)设备更加的重要 , AMAT、LAM、TEL三巨头无不卯足了劲发展相关技术 , 更复杂的脉冲 , 更精细的控制 , 更大功率的Tool , 尤其是原子层技术 , 不论ALD还是ALE都将改变原来的工艺路线。
总结
根据ASML的公开数据显示 , 已有2100i光刻机进口国内 , 这是做多重曝光的神兵利器 , 拥有目前市面上最高套刻精度的DUV浸没式光刻机 , 那么用2100i光刻机是否就能做到5nm芯片呢? 从上述各式各样的光刻技术来看当然没问题 , 但这一切需要搭配性能更好的沉积(Deposition)、刻蚀(Etch)设备 , 没有这些更好的配套设备很遗憾 , 即便有EUV光刻机也无法做到真5nm , 更何况目前国内只有DUVi,毕竟整个芯片制程不是只有光刻 , 这是目前国内半导体面临的最严峻问题 , 因为不论沉积或刻蚀制程中最高端的设备都掌握在美国的AMAT以及LAM手上 , 日本TEL虽然很强但在许多细分领域也没有可替代品。
可以这么说 , 此时此刻国内Fab在7nm以下先进制程上遇到最大的瓶颈并非光刻机 ,而是被美国拿捏的先进沉积与刻蚀设备 , 因为我们手上的光刻机理论都能达到5nm , 无非套刻精度也就是良率高低的差别 , 也正是这个原因 , 我们只能利用既有的设备在7nm这个环节不断优化 , 再回到最初作者整理的各家单位晶体管密度的表中 , 我们能发现未来国产芯片不论N+3或者N+4晶体管密度都难达到真正5nm的180MTr/mm2 , 而是像三星一样只是7nm的优化再优化 , 当然优化版的N+3推出之际 , 必然又会扑天盖地各种突破封锁 , 国产5nm达成 , 透过文章我们可以清楚 , 未来的所谓国产5nm是以获取国外先进设备与材料为基础 , 高昂的生产成本(多重曝光)为代价 , 加上玩点文字游戏取得的成果 , 我们必须客观地看待 , 当然被重重限制的我们能取得这样的成就是真心令人赞叹 , 但不应该无脑并背离事实的吹嘘与捧杀。
此时此刻对于国内导体行业来说 , 夯实技术能力与攻关突破同样重要 , 在发展光刻机的同时更要重点突破先进制程需要的沉积与刻蚀设备 , 针对性的突破必然更快速 , 能买到的设备先利用起来 , 重点攻关极需且缺乏的设备 , 这能给被制约的我国半导体行业争取更多时间 , 必须用一切办法与全球领先集团保持固定距离而不被拉开 , 所谓攻关突破是要加入时间因素考量的 , 因为对手一直在进步 , 压根没有摩尔定律将终止 , 对手会在原地等我们的可能 , 如果攻关突破不限时间 , 没日没夜的工程师埋头苦干之后是对手越跑越远 , 那这样的突破就失去了意义 。
再回到文章第二部分的晶体管密度表,即将推出的国产旗舰手机上的国产芯片不论节点名称叫“5nm”还是“N+3”,都不是重点,因为它与真正的5nm还有很大的差距 , 重要的是芯片晶体管密度是否能够提升,只要性能有所提升即便是微幅提升那毫无疑问也是下一代工艺 , 证明我国半导体行业从上到下的努力不放弃 , 即便在西方重重封锁之下 , 我们也必须向施压者证明 , 一切并不会如西方所愿 , 让我们失去继续迭代的能力 , 这个信号的释放绝对是必要的。
