
说到维基百科,大家都不陌生。
光在差评的资料来源里,你就能经常看到它。
世超每次写那些带点历史的、科普性质的文章时,就会查维基百科的解释,完了再顺着底部的参考资料挖一挖,能延伸出更多信息点。
可以说,维基百科是普通人弄懂一个概念,最便捷也最权威的方式之一。
维基百科的运营机构,是一个叫维基媒体的非盈利组织。组织旗下除了有维基百科,还有维基共享资源,维基词典,维基教科书等项目。
这些项目都是免费给大家用的,因为维基媒体的核心价值观就是让知识能自由获取和共享 。
但最近,维基媒体真的被AI 公司们闹麻了。
这些公司为了训练大模型,派了无数个 AI 爬虫源源不断爬取维基媒体上面的数据。
但说起来你可能不信:维基媒体居然没告这些 AI 公司,而是选择了——主动上交。
“各位大哥,我把资料都整理好了,你们别爬了行不。”

前段时间,维基媒体把英语、法语的维基百科内容托管在社区平台 Kaggle,告诉那些 AI 公司,要资源自取。
光给资源还不行,维基还要服务好这些大哥,专门把资料针对AI 模型的口味优化了一遍。
因为机器和人类不一样,我们看起来清晰直观的页面,他们还需要多动点脑子,来判断每一部分是啥。

所以维基就把页面做成了 JSON 格式的结构化内容,那些标题、摘要、解释都按照统一格式分好。
这样 AI 在查看时更容易读懂每一段的内容和数据,从而降低了 AI 公司的成本。

这一波啊,这一波属于是为了保护老巢不被冲垮,维基给狼群做了一盘美味的肉,扔在了别的地方。
世超觉得,维基这么做真挺无奈的。
早在 4 月 1 号时,他们已经发过博客吐槽了:从 2024 年以来,平台用来下载多媒体内容的流量增加了 50%。
本以为是大家更爱学习了,结果一查发现全 TM 是 AI 公司的爬虫。爬虫们源源不断地把资源爬回去,然后拿去训练大模型。

爬虫对维基的影响,还真挺大的。
因为维基媒体在全球有多个区域数据中心(欧洲、亚洲、南美等)和一个核心数据中心(美国弗吉尼亚州阿什本)。
核心数据中心存着所有的资料,而区域数据中心会临时缓存一些热门词条。

这么做好处是啥呢?
比如最近很多亚洲人在查“ Speed ”这个词,那“ Speed ”就会被缓存到亚洲的区域数据中心。
这样后来的亚洲网友查看“ Speed ”时,这些数据就会走同城快递,从亚洲数据中心出发,不用再从美国的数据中心走国际物流了。
这高频词条走廉价通道,低频词条走高价通道的办法,不光提高了各个区域用户的加载速度,也降低了维基媒体的服务器压力。
但问题是: AI 管你这的那的?
只要是个词条,它都要访问,而且批量性访问。
这就导致不断有流量走高价通道。
前段时间维基媒体就发现,那些走美国数据中心的高成本流量,居然有 65% 都是 AI 爬虫糟蹋的。

要知道维基是免费的,但它的服务器不是,每年都有 300 万美元托管成本呢。

不过吐槽可能并没啥用,所以几周后维基媒体选择把资源整理出来,托管在其他平台,让 AI 公司自取。
其实不光是维基百科,从内容平台到开源项目,从个人播客到媒体网站大家都遇到过类似问题。
去年夏天,iFixit 老板就在推特上吐槽 Claude 的爬虫在一天访问了自家网站 100 万次。。。
看到这,你可能会说,不是一个有机器人协议 robot.txt 么,不想让 AI 爬虫访问自己的网站,可以把它写进协议里。

啊对,在 ifixit 把 Claude 爬虫添加到 robots.txt 后,爬行确实暂停了下(变成了30分钟一次)
在曾经的互联网时代,robots 协议的确是个一劳永逸的技术,也有公司因为不遵守吃到了官司。
但搁现在,这个君子协议只能算纸老虎。
现在的大模型公司,能爬尽爬。
毕竟别家都在爬,你不爬,那你的语料库就不如别人强大,大模型起跑线就会低人一等。
那咋办——给爬虫换一个名字呗(user-agent)。你只说不让鲁迅爬,又没让说不让周树人爬。
有没有大模型这么无耻?可太多了。
之前就有 reddit 网友明明在协议中禁止 OpenAI 的爬虫,结果对面改了下名字,继续爬。

再比如 perplexity 也被科技媒体 WIRED 抓包过,根本无视 robots 协议。

这些年呢,大家也在尝试各种新的办法。
有人研究出在 robots 协议中放一个坏死链接,但凡点进链接的一定是爬虫,毕竟正常用户是不会点击这个协议。
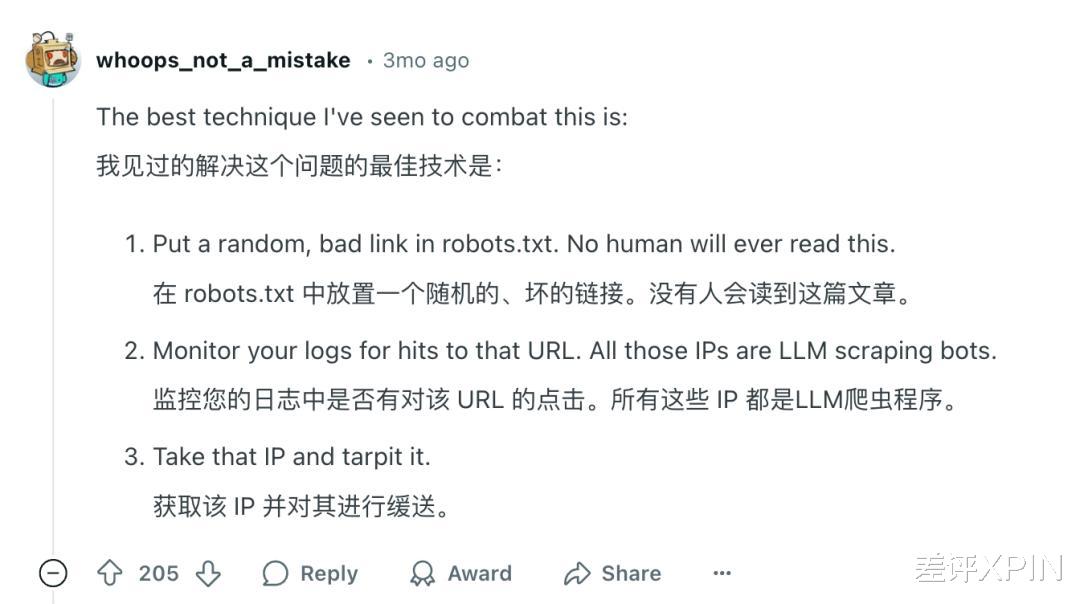
还有人选择借助 Web 应用程序防火墙 ( WAF ),基于 IP 地址、请求模式、行为分析综合识别恶意爬虫。
也有人决定给网站弄一套验证码。

但基本上这些办法,往往道高一尺,魔高一丈。你抵抗越狠,AI 公司也会采取更残暴的爬取手段。
所以赛博菩萨 cloudflare 前段时间出了一套技术是监测到有恶意爬虫,就索性让爬虫进来。
当然放它进来,不是给它好吃的,而是做了一道“错饭”——提供一串和被抓取网站无关的网页,让 AI 在里面慢慢看。

cloudflare 的操作还算是收敛着了。
今年 1 月,有网友写了一款更凶狠的工具,叫 Nepenthes 猪笼草。
和猪笼草杀死昆虫一样,“ 猪笼草 ”将 AI 爬虫困在没有出口链接的 “ 无限迷宫 ” 静态文件中,让它们抓不了真实内容。

不光如此,“ 猪笼草 ”还不断向爬虫投喂 “ 马尔可夫乱语 ”,来污染 AI 的训练数据。据说这个技术目前仅有 OpenAI 的爬虫能逃脱。
好好好,原来 AI 攻防战,在大模型训练源头就已经打响了。
当然了,平台们也可以和 AI 公司达成协议。
比如 Reddit 和推特都向 AI 公司推出了收费套餐,每月使用多少 API、访问多少推文,我就收你多少钱。
也有没谈成还打起官司的。比如《纽约时报 》商量无果后,就起诉了 OpenAI 抓取自家文章。
看到这你可能会好奇:为什么维基百科不告这些 AI 爬虫呢?
世超猜测,这可能和维基百科本身有关。
维基百科的许可协议非常开放。
它大部分内容是允许任何人( 包括 AI 公司 )在遵守署名和相同协议共享的条件下,自由地使用、复制、修改和分发。
所以从法律角度来看,AI 公司抓取、使用维基百科的数据进行模型训练,大概率还是合法的。
而且就算把 AI 公司告上法庭,但现在业内也没有对 AI 侵权这块有个明确的法律界限。这种风险大、成本高、消耗时间久的选择,对维基媒体来说,并不切合实际。
最主要的是,维基媒体的使命就是——让地球上的每个人都能自由获取所有知识。
虽然 AI 爬虫带来的服务器成本是一个问题,但通过法律手段或商业协议,来限制别人获取资源,或许和他们的使命相违背吧。
照这么来看,维基媒体选择把数据整理好,给 AI 公司拿去训练,也许是最合适,但也最无奈的办法吧。



Tricolorviol
robots协议防君子不防小人,六年前ai还没火的时候,我的站点就被字节的爬虫爬瘫过,无视robots,每分钟大几千次抓取,一天干130多万次请求,带宽全被它占了,正常访问站点动不动就502
并不在线
字节的Bytespider[doge]当时头条刚开始做搜索引擎,头条搜索还没上线,爬虫先搞一波大规模暴力抓取
咚咚滴个咚咚
请客吃饭,结果被请的人一点不客气,连吃带拿,包括但不限于被请客人家的七大姑,八大姨,甚至是狗🌚
文子
哈哈哈,AI爬百度怎么样,会不会被广告带偏。
我有一个大拇指
别人是凿壁偷光,他们是直接把邻居的整面墙给砸了。。。。 [捂脸哭]
恰好。
比百度百科全面深入的百科网站
吃棉花糖的布丁
“自由、共享”不是去别人那打包搜刮理由。有钱去爬取资源,不如捐助一下别人的服务器 [无奈吐舌]
豆友203160342
来你怎么看待它 如果你把它看做媒体 那它的作用可老大就
旎旎
这其实就相当于商业偷窃
林烦
感觉也像是一种欺负好人
zhulinda2014
不是,二狗只做硬件部的内容
筱忧万岁
[doge]就那个把b21改成六代机的那个
莫怨MY青春
现在有新的协议出来了,就可以给ai数据
维尼de小猪
二狗莫名打了个喷嚏ing [大笑]
小小月亮
免费试用不代表你可以拿着打包盒过去,连吃带拿呀[doge]你这何止是拿打包盒啊,直接拿着卡车去拖了一车一车的拖
二阳
Hugging face 不是都已经打包好了吗,应该不是公司,估计是很多学习的人爬的[捂脸哭]
野生的家猫
随着AI的x成熟,世界正在从春秋走向战国,也可以让自家AI爬取别人的AI训练成功嘛[笑着哭]
磨成
差友们,这是我们自己的账号哦!!
心有城堡lqy
到时候搞得大家都没得用就老实了[滑稽笑]
持槍朱麗葉
主要和大家分享些前沿科技好玩的科普,分享些有趣的资讯动态。 [害羞]
芽衣
我有个问题,为什么我单线程去抓取的时候会给我断掉,但是多线程的时候却不会给我断?
我去上学了
维基百科可以任何人编译,哪怕自己造个身份都行[doge]