
Meta 刚刚开源了 Llama 4,这一举动无疑在 AI 界掀起了巨浪。
它不仅标志着 Llama 生态系统进入了一个全新的纪元,更预示着开源多模态大模型领域格局的重大变革。
Llama 4究竟有何魅力,能让开发者如此兴奋?

它又将如何影响 AI 的未来?
Llama 4 的开源和原生多模态特性使其成为AI领域的一颗耀眼新星。
所有开发者现在都可以在llama.com和Hugging Face上下载这两款最新的模型。

这意味着更多人可以参与到Llama的生态建设中,推动AI技术的快速发展。
更重要的是,Llama 4原生支持多模态输入,为AI应用打开了更广阔的想象空间。
DeepSeek V3 曾是开源模型中的佼佼者,但 Llama 4 的出现使其面临强劲挑战。
这次的开源浪潮是否会促使 DeepSeek 加快 R2 的发布?
这无疑是AI 社区关注的焦点。
Llama 4的出现,也为其他开源模型的发展提供了新的思路和方向。
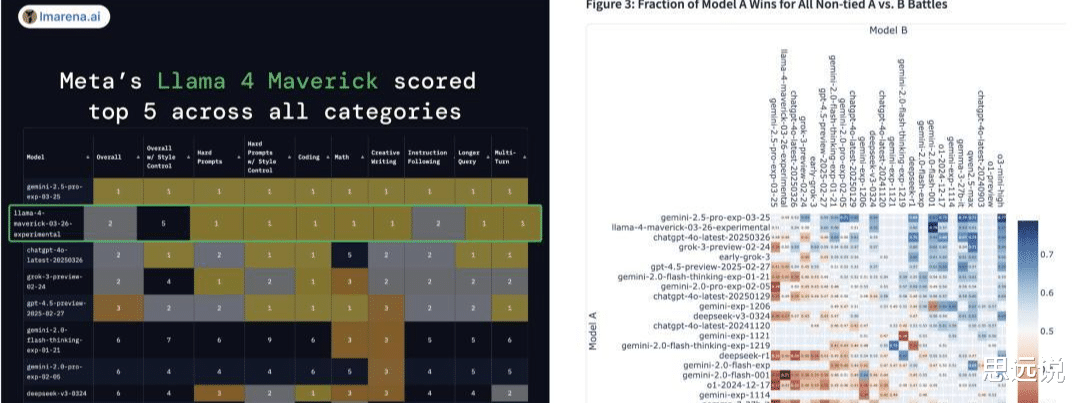
Llama 4 家族包含 Scout、Maverick 和 Behemoth 三个版本,分别针对不同的应用场景和性能需求。
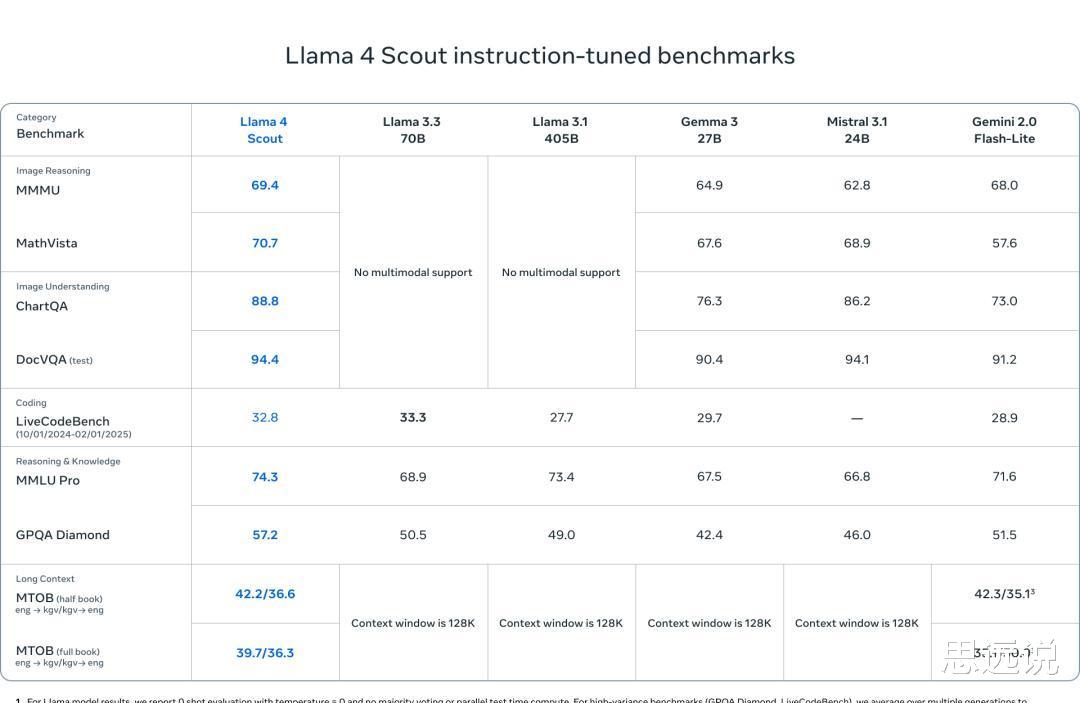
Llama 4 Scout 拥有 1090 亿参数,最大的亮点是支持 1000 万上下文,相当于可以处理 20 多个小时的视频,而且仅需单块 H100 GPU 就能运行。
这在以往是难以想象的。
它在基准测试中,性能也超越了 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1。
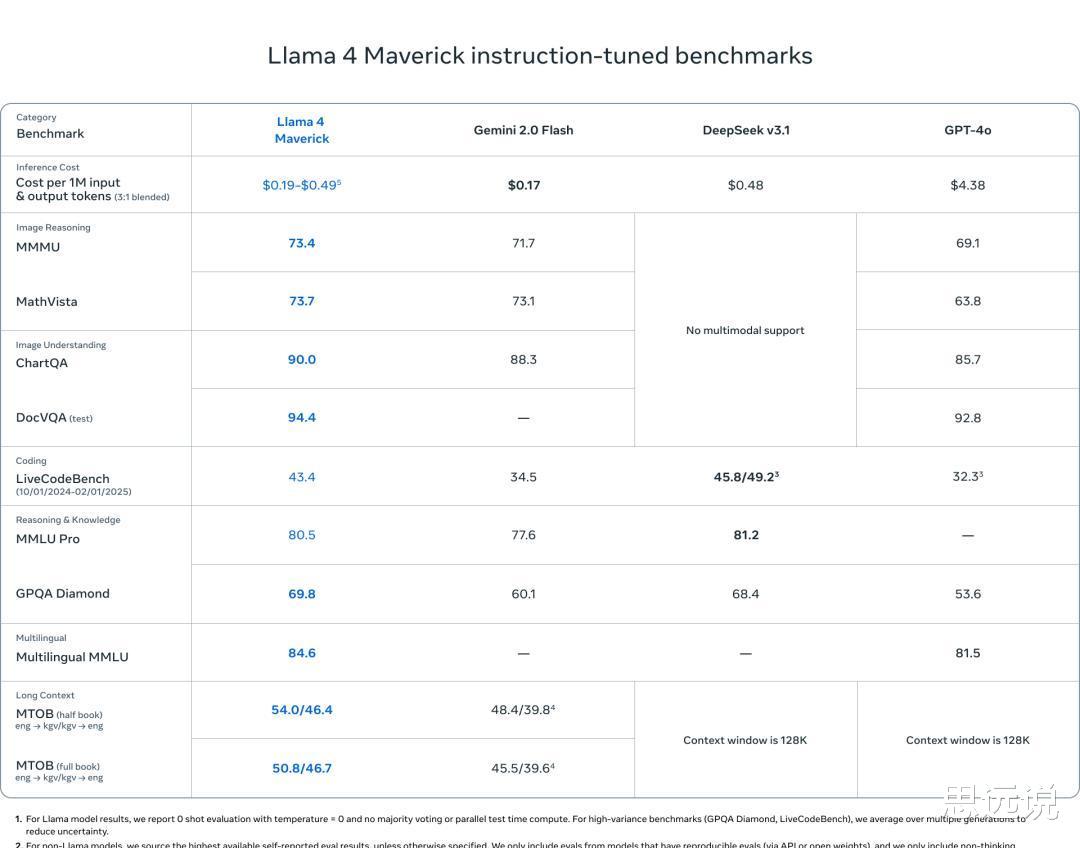
Llama 4 Maverick 则拥有 4000 亿参数,其性能更是令人瞩目。
它仅用一半参数就达到了与 DeepSeek-v3-0324 相当的推理编码能力,在大模型LMSYS排行榜上仅次于闭源的 Gemini 2.5 Pro。
Maverick 的出现,为那些需要高性能但资源有限的开发者提供了新的选择。
而仍在训练中的 Llama 4 Behemoth,更是拥有惊人的 2 万亿参数。
作为 Maverick 协同蒸馏的教师模型,Behemoth 在 STEM 基准测试中已经超越了 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。

它的未来表现令人期待。
Llama 4 的强大性能得益于一系列技术创新。
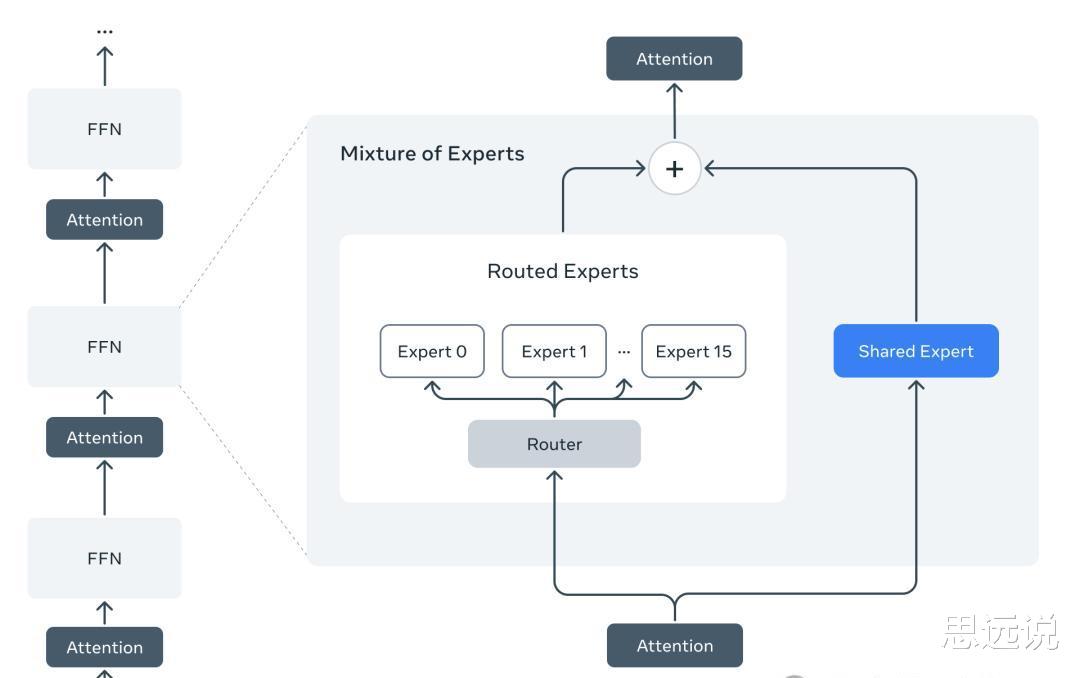
它是 Llama 系列中首批采用混合专家(MoE)架构的模型。

MoE 架构使得模型在训练和推理时计算效率更高,并在相同的训练 FLOPs 预算下,能够生成更高质量的结果。
Maverick 模型的 4000 亿总参数中,只有 170 亿是活跃参数,极大地提高了推理效率。
Llama 4 还采用了原生多模态设计,将文本和视觉 token 无缝整合到统一的模型框架中。
这得益于早期融合技术,以及基于 MetaCLIP 升级的视觉编码器。
此外,Meta 还开发了 MetaP 训练方法,能够更可靠地设置关键模型超参数。
为了训练 Llama 4,Meta 团队付出了巨大的努力。
他们采用了 FP8 精度进行高效的模型训练,并使用了超过 30 万亿个 token 的文本、图片和视频数据集。
这比 Llama 3 的预训练数据量翻了一倍还多。
“中期训练”的方式进一步提升了模型的核心能力,并为 Scout 解锁了 1000 万的输入上下文长度。

Llama 4 的后训练流程也经过了精心设计,采用了轻量级监督微调(SFT)、在线强化学习(RL)和轻量级直接偏好优化(DPO)相结合的方式。
针对不同模型的特点,Meta 还开发了相应的特定后训练方法。
例如,为了训练 Maverick,他们重新设计了后训练流程,并使用 Llama 模型作为评判者筛选数据。

为了训练拥有 2 万亿参数的 Behemoth,Meta 团队也进行了大量的改进和创新。
他们精简了 95% 的 SFT 数据,并采用了轻量级的 SFT 后接大规模 RL 的策略。
此外,他们还开发了完全异步的在线 RL 训练框架,将训练效率提升了约 10 倍。

Llama 4 的开源,无疑将对多模态大模型领域产生深远的影响。
它为开发者提供了更强大、更高效的工具,也为 AI 应用的创新提供了更多可能性。
那么,Llama 4 的出现是否会引发新一轮的 AI 技术竞赛?

它又将如何塑造 AI 的未来?
让我们拭目以待。
