
在现代前端开发中,DOM操作始终是核心技能之一。当我们需要遍历复杂的文档结构时,传统的递归遍历或querySelectorAll 往往存在性能或灵活性不足的问题。
我将介绍一个被低估的强大API——TreeWalker,它能帮助我们以更高效、更灵活的方式遍历DOM树。
TreeWalkerTreeWalker API是DOM Level 2规范中定义的接口,提供了对文档节点的高效遍历能力。与简单粗暴的 querySelectorAll 相比,它具有以下优势:
惰性遍历:按需获取节点,节省内存双向遍历:支持向前/向后移动灵活过滤:可定制节点过滤规则高性能:浏览器原生实现,遍历效率更高基本用法创建TreeWalker实例

关键参数解析
whatToShow
通过位掩码指定要包含的节点类型,常用值:

多个类型组合使用位或运算符:

filter
自定义过滤函数,返回以下值之一:
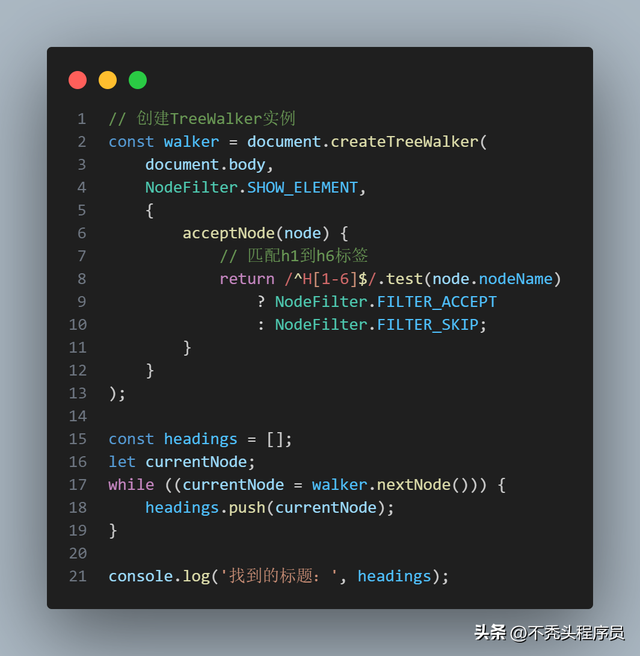
NodeFilter.FILTER_ACCEPTNodeFilter.FILTER_SKIPNodeFilter.FILTER_REJECT示例示例1:收集所有标题元素
示例2:文本内容搜索高亮
 高级技巧
高级技巧双向遍历
TreeWalker 支持向前和向后遍历:

状态保持
TreeWalker 实例会记住当前遍历位置,适合分步遍历:

性能对比
我们通过基准测试比较不同方法的性能:

测试结果说明 TreeWalker 在大型文档遍历中具有明显优势
使用场景推荐大型文档处理:当需要处理数千个节点时自定义遍历逻辑:需要复杂过滤条件时分块处理:逐步处理节点避免阻塞主线程无障碍功能:实现自定义的阅读顺序遍历兼容性
