开源模型上下文窗口卷到超长,达400万token!刚刚,“大模型六小强”之一MiniMax开源最新模型——MiniMax-01系列,包含两个模型:基础语言模型MiniMax-Text-01、视觉多模态模型MiniMax-VL-01。MiniMax-01首次大规模扩展了新型Lightning Attention架构,替代了传统Transformer架构,使模型能够高效处理4M token上下文。
这不仅是MiniMax首次将模型开源,也是MiniMax首次公开其技术细节。在此之前,MiniMax一直以闭源模型的身份示人,外界对其底层模型细节知之甚少。
MiniMax发布了MiniMax-01的技术报告。技术报告中透露了MiniMax基础大模型的大胆创新:一是线性注意力机制(Linear Attention)的大规模训练,二是400万Token的超长上下文。
之所以说“大胆创新”,是因为研究一个新的架构风险极大,有去无回。

研究背景: 随着大语言模型和视觉语言模型的发展,现有模型上下文窗口长度不足,而扩展窗口面临注意力机制计算复杂度过高的问题。尽管已有多种降低计算复杂度的方法,但在商业规模模型中应用有限,且现有分布式训练和推理框架主要针对 softmax 注意力,难以支持新型架构。研究贡献:成功构建 MiniMax-01 系列模型,在标准学术基准测试上表现优异,长上下文处理能力突出,支持长达 400 万标记的输入,远超现有模型。首次大规模应用线性注意力机制,并通过混合架构有效解决其检索能力不足的问题,详细阐述了算法设计与工程优化细节,为后续研究提供重要参考。

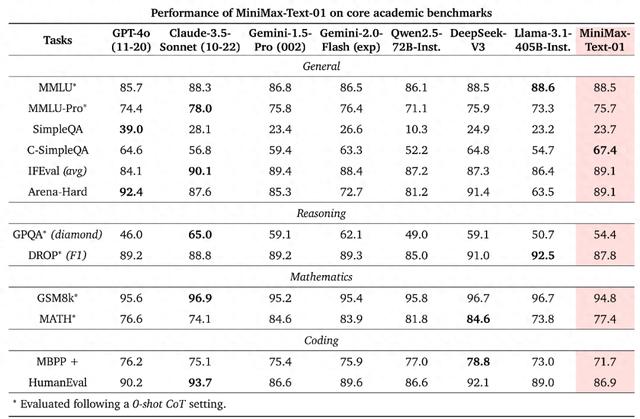
在 MiniMax-01系列模型中,我们做了大胆创新:首次大规模实现线性注意力机制,传统Transformer架构不再是唯一的选择。这个模型的参数量高达4560亿,其中单次激活459亿。模型综合性能比肩海外顶尖模型,同时能够高效处理全球最长400万token的上下文,是GPT-4o的32倍,Claude-3.5-Sonnet的20倍。超长上下文、开启Agent时代我们相信2025年会是Agent高速发展的一年,不管是单Agent的系统需要持续的记忆,还是多Agent的系统中Agent之间大量的相互通信,都需要越来越长的上下文。在这个模型中,我们走出了第一步,并希望使用这个架构持续建立复杂Agent所需的基础能力。
DeepSeek-V3 则在保持高效训练和推理的同时,在数学和编码任务上表现出色,并且在长上下文理解方面也展现出强大的能力。
两者都采用了 MoE 架构和先进的训练策略,在提升模型性能的同时,也考虑了训练成本和效率。
未来,随着硬件和算法的不断发展,MiniMax-01 和 DeepSeek-V3 都有望在各自的领域取得更大的突破,推动 LLM 的发展。
