“地球上最聪明的人工智能”、“20万块英伟达GPU训练”
2月18日,特斯拉创始人埃隆·马斯克旗下XAI举行Grok 3发布会,超过100万人在线观看,关注度拉满。

是不是“地表最强”且不论,马斯克 “有钱任性”确实是真的。
为了支持Grok3训练,团队仅用92天就已经实现了超算集群的算力翻倍,GPU数量已达20万块。啥概念呢?光是GPU消耗的电费就相当于30万个家庭一年的用电量,仅电力支出就高达约2.6亿美元。并且,xAI与戴尔达成50亿美元协议,戴尔或将今年向xAI交付搭载英伟达GB200芯片的服务器。

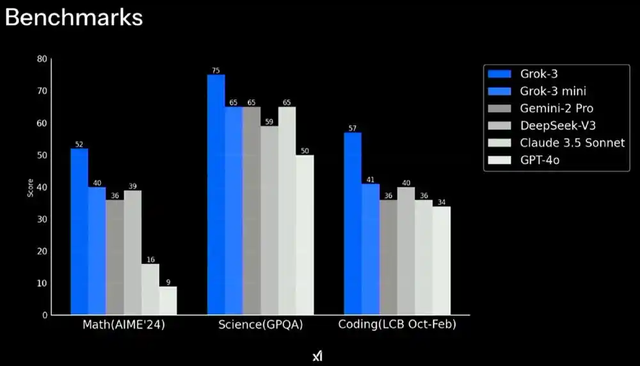
根据xAI公布的测试数据,Grok 3在数学(AIME24测试得分52分)、科学(GPQA评估)和编程能力(LCB测试)上超过谷歌Gemini-2 Pro、DeepSeek-V3、Claude 3.5等模型,甚至在推理测试中达到93分(Grok 3 Reasoning Beta版)。
同时,引入“思维链”(Chain of Thought)机制,分步骤解决复杂问题,提升逻辑连贯性;DeepSearch功能可扫描互联网信息并生成摘要,增强信息检索效率。
尽管官方数据亮眼,独立测试显示其代码生成能力不稳定(例如无法正确处理100个小球的弹跳模拟),且基础逻辑问题(如判断9.8与9.11大小)需依赖“推理模式”解决。此外,Grok 3未开源,核心算法被遮蔽,仅通过订阅服务(如X平台Premium Plus)提供访问,限制开放生态构建。
反观被部分网友称之为“国民AI”的DeepSeek,之所以能快速出圈,“性能、成本、速度”都走在了行业前列。
据每日经济新闻报道,DeepSeek R1的预训练费用只有557.6万美元,仅是OpenAI ChatGPT-4o模型训练成本的不到十分之一。在摆脱硬件束缚的情况下,仍然在推理性能等方面接近ChatGPT-o1,部分领域还有所超越。

不是GPT用不起,而是DeepSeek更具性价比。
有了DeepSeek这个”大黑马”,对于Grok 3的发布网友评价也呈现分化:
看好:
“看评测效果还不错,榜单上的确是第一。”
“Grok 3是首个突破1400分的模型,并且在所有类别中排名第一”
不看好:
“有量变,无质变,性价比不高。我感觉马斯克的 Grok3 走错了方向,或者说,被 OpenAI 带沟里去了。”
“在ds r1已经如此强大且开源的情况下,基模出现突破的重要性已经没那么高了,而多模态和与大模型匹配的硬件的发展还有很大空间。”
这里我们不妨问问当局者“DeepSeek”怎么看这件事:

它给出的总结是:
“Grok 3在数学、科学等硬核任务中表现更强,但其高成本与闭源模式限制了普及性;DeepSeek则以性价比和场景适配性见长。两者并非零和竞争,而是代表了AI发展的不同方向——技术极致化与应用普惠化的共存。未来,模型性能的边际效益递减可能促使行业更多转向应用创新与伦理治理的平衡。”
同时,DeepSeek给出了自己的核心竞争力:
● 性价比与轻量化:DeepSeek-R1以行业1/50的训练成本实现顶级性能,API调用成本低至0.001元/千Tokens,且无需依赖超算集群即可高效部署。
● 本土化与场景适配:在中文语义理解、政务流程优化(如深圳福田区政务效率提升60%)等场景中表现突出,更贴合中国市场实际需求。
● 开源与生态优势:通过开源策略快速激活开发者社区,覆盖近百种语言实时互译,并内置严格的伦理约束机制,避免争议性输出。
你怎么看马斯克 Grok 3 大模型的发布,他夸下海口的“地表最强AI”名副其实吗?
