
从诸多大佬的表态来看,端到端+大模型可能就是自动驾驶技术路线的终局。
不过,正如各家的端到端千姿百态一样,大模型也没有标准答案。
01兵无常势,水无常形。
在真实世界中,技术也是高度可重构的,随着时间的推移、新技术的出现,未来在不断改进,不断进化。
自2022年年底OpenAI发布大语言模型ChatGPT以后,生成式AI大模型逐渐演化出了两大分支:语言模型和世界模型。

语言模型继续在数字世界深耕,从单一的文本模态走向包含图片、视频在内的多模态,使其具备了文生图、看图说话、图生图、文生视频的能力,比较典型的代表有今年2月份发布的Sora和4月份发布的GPT4-o。

世界模型则从数字世界走向物理世界,从一维形式的数字智能走向三维形式的空间智能。
根据出生于北京、大成于美国的AI教母李飞飞的表述,空间智能指的是AI在三维空间和时间中以三维方式感知、推理和行动,并与现实世界进行交互。

两者的区别在于,大语言模型的基础是通过文本序列对世界进行一维表示。
具备图像理解和视频理解能力的多模态语言模型不过是将其它模态的数据进行Token化,然后硬塞进文本这个一维的序列表示中。
空间智能则是把三维当成了表达的核心。

换个角度思考一下它们的区别:语言本质上来说是一种纯粹生成的信号,世界上原本没有语言,说的人多了,也就成了语言。
不过,既然是纯粹生成,当然可以信口胡说,从而无视这个世界的物理规律。
但是,世界模型旨在理解并掌握物理规律,遵循物理规律跟物理世界产生交互,物理规律不可欺,自盘古开天辟地以来,3D世界及其物理规律就一直存在在那里。

从这种划分来看,在自动驾驶大模型的赛道上,小鹏汽车的全域大语言模型和理想汽车的视觉语言模型都是在文本之上叠加了图片和视频模态的语言模型,而蔚来汽车和特斯拉的世界模型则属于空间智能这一阵营。
02树欲静而风不止。
智能电动汽车行业的玩家们除了要在产品、技术、渠道层面展开竞争,营销层面的拉高踩低、明吹暗讽也是一直暗流涌动。
在7月31日的智能驾驶系统发布会上,何小鹏暗怼理想汽车数据为王的观点。
何小鹏表示:如果有厂商说他们数据多,所以能力强,千万不要相信他。
因为在新的端到端范式之下,很多数据需要重新标注。
即便有了自动标注工具的帮助,数据标注也是一项非常非常繁重的工作,2022年夏天,马斯克在接受车友访谈时表示,特斯拉大约有1500名人类标注师!

不过,这并不意味着姿势不对,起来重睡,端到端来了,之前积累的很多精标BEV+OCC数据通通作废。
而是说,在规则+算法为主的分模块时代,车企的主要精力放在了增强感知能力上。
到了端到端时代,需要在BEV和占用空间之外做进一步的标注,比如与规划决策密切相关的自车和其它交通参与者的位姿、速度、加速度,这一类数据标注需要重新补齐,以构建预测与规划数据集。

端到端+大模型之后,大模型引入了新的数据标注需求。
在基于语言模型的自动驾驶大模型中,其输入是当前驾驶场景的图片,其输出是各类交通参与者、道路拓扑、交通信号标识的语义信息,这种模型不具备自回归特性,进行有监督学习,其训练需要海量的数据标注工作。

在基于世界模型的自动驾驶大模型中,其输入是当前摄像头数据,输出是下一个时间步长后的摄像头数据,这类自回归模型和GPT大语言模型依靠过去的Token预测下一个Token非常类似,其训练过程是无需数据标注的无监督学习。
无监督学习和有监督学习的核心区别就是不需要进行数据标注。
也就是说,世界模型可以从此告别劳动密集型的人工智能,应对比海量更海量的数据驱动新范式。
03据说东北老铁在干仗前会先吼一句你瞅啥?湖南人则是人狠话不多,先干了再说。
语言模型就像东北大哥,先是一声吼,然后再决定出手不出手,只给出对当前驾驶场景的理解,输入给决策神经网络做参考,自己并不直接输出最终的决策结果-车辆的行驶轨迹。
世界模型就像湖南老表,相当干脆利索,直接出手给出车辆的行驶轨迹。

从理想汽车展示的VLM的能力可以看出,它给出的都是车道选择、是否减速这些中间层面的建议,并不直接给出车辆最终的行驶轨迹。
蔚来汽车的世界模型则是推演万千平行世界,从中选择最优解,在0.1秒之内生成216种可能的行驶轨迹,选择出最优的行驶轨迹,行驶轨迹可以直接给到下游的执行模块,控制车辆的驾驶行为。

直接给出行驶轨迹是世界模型的第1个优势,第2个优势则在于它可以通过海量的无监督学习训练出对驾驶场景的深度理解能力,实现了从感知到认知的能力跃升。

BEV+OCC的感知能力对安全、舒适、高效的完全自动驾驶是不够的。
一个很明显的例子就是,BEV和OCC不清楚当前的光照条件如何,天气情况怎么样,而光照和天气恰恰是可以影响自动驾驶车辆行驶的关键要素。
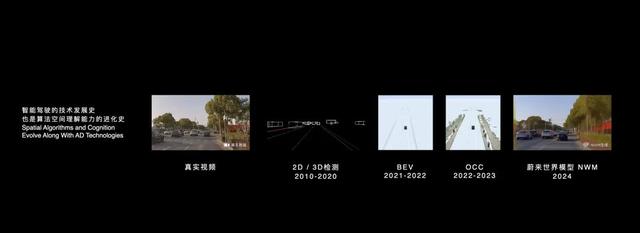
世界模型显然具备比BEV+OCC更加细力度的场景理解能力。
因为它的本质是建立对当下空间的深度理解能力,然后基于物理规律和当前世界,对未来时刻的世界做想象推演,为了准确推演下一时刻的世界,世界模型必须建立对当前世界的深度理解能力。

这种能力是通过对海量数据的无监督训练学习得来的,拿一个15-30秒的视频片段Clips,划分好时间刻度,将下一时刻的传感器数据作为世界模型的真值进行训练,通过一次又一次的刷题,世界模型就具备了场景的深度理解能力。
从世界模型的能力来看,它会消耗比语言模型更加多的算力,也许这才是采用4颗Orin的蔚来选择世界模型、采用两颗Orin的理想和小鹏选择语言模型的真正原因。
随着算力的升级,理想和小鹏从语言模型过渡到世界模型将会是一个大概率事件。
