英伟达AI服务器:NVLink版与PCIe版的揭秘与选择

英伟达的两款 GPU 版本为 AI 服务器提供了不同的选择:
NVLink(SXM)版本:
* 高带宽连接,专为高吞吐量工作负载和密集型训练模型而设计。
PCIe 版本:
* 通用性更强,适用于广泛的应用程序,包括边缘计算和推理。
在选择时,考虑以下因素:
* 工作负载要求:对于需要高带宽的训练模型,NVLink 版本是理想选择。
* 部署场景:对于需要灵活性和通用性的部署,PCIe 版本更为合适。
NVLink版的服务器
SXM架构,英伟达专为高速GPU互联开发的高带宽插座解决方案。它使GPU与DGX和HGX系统无缝对接,为每代英伟达GPU提供特定SXM插座,包括H800、H100、A800、A100、P100和V100,确保最佳连接。例如,浪潮NF5488A5 HGX系统上的8块A100 SXM卡并行工作展示了其强大集成能力,实现了GPU之间的高速互联。

HGX 系统主板采用先进的 NVLink 技术,将 8 个 GPU 无缝连接在一起,构建出高速带宽网络。每个 H100 GPU 连接至 4 个 NVLink 交换芯片,实现惊人的 900 GB/s NVLink 带宽。此外,每个 GPU 还通过 PCIe 接口与 CPU 相连,确保数据快速传送到 CPU 处理。

由 NVSwitch 芯片赋能的高性能互联,无缝连接 DGX 和 HGX 系统板上的 SXM 版 GPU,打造高效的 GPU 数据交换网络。
* A100 GPU 提供高达 600GB/s 的 NVLink 带宽
* H100 GPU 提升至惊人的 900GB/s
* 针对特定市场优化的 A800 和 H800 仍保持 400GB/s 的高速互连性能

NVIDIA DGX:
- 出厂预装的完整服务器解决方案
- 同等体积下业界领先性能
- 多台 DGX 可通过 NVSwitch 轻松组合为 SuperPod
NVIDIA HGX:
- 原始设备制造商 (OEM) 定制整机方案
PCIe版的服务器
受限于PCIe架构,PCIe版GPU仅能与相邻GPU通过NVLink Bridge连接,导致非直接相连GPU间的通信效率受限。与PCIe最大128GB/s的带宽相比,NVLink提供显著更高的超高带宽,从而限制了PCIe版GPU的性能发挥。

PCIe 版 GPU 的单卡计算能力与 SXM 版堪比。对于注重单卡计算性能、对 GPU 间高速互联要求不高的应用,如中小型模型训练和推理部署,PCIe 版的互联带宽不会显著影响性能。
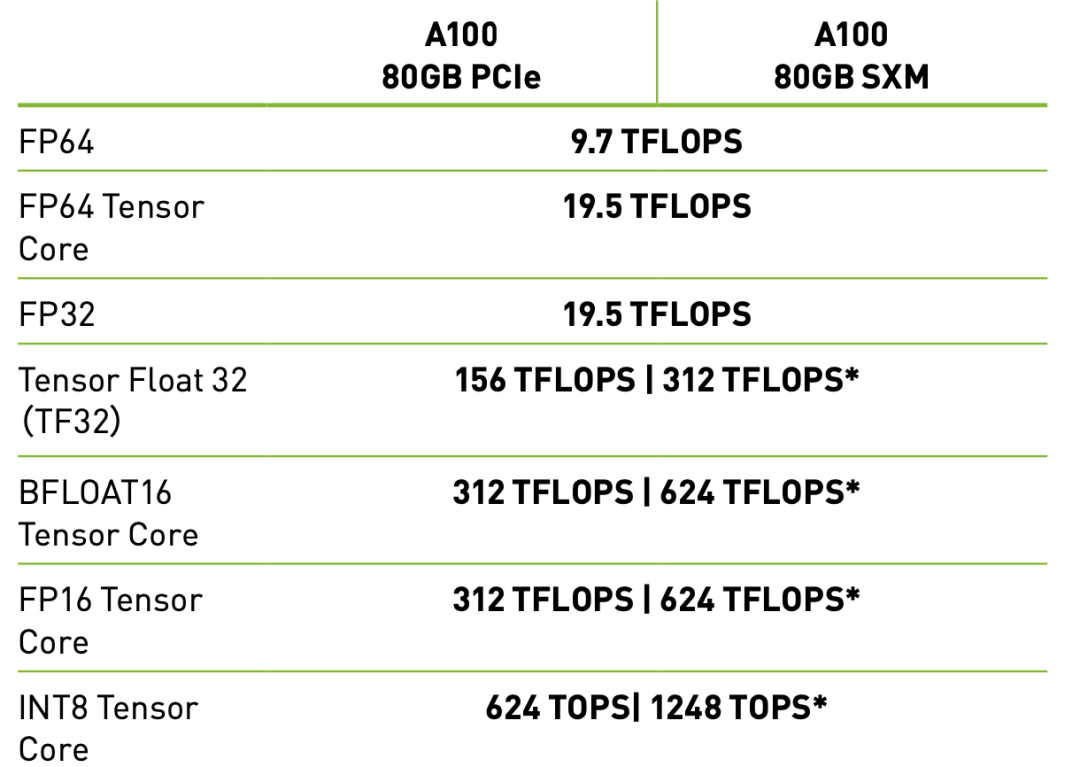
该如何选择?
PCIe 版 GPU 的优势在于其灵活性:
* 工作负载较小的用户可灵活配置 GPU 数量,满足不同需求。
* 可支持 4 张或更少 GPU 卡,实现服务器小型化。
* 嵌入 1U 或 2U 服务器机箱,节省数据中心机架空间。
在推理应用中,虚拟化技术可实现 CPU 和 GPU 一对一匹配,其中:
* PCIe GPU 能耗约为 300W/GPU,兼容性高,适合大多数情况。
* SXM GPU 功率可达 500W/GPU,牺牲能效但提供卓越互联性能。
对于要求极高 GPU 间互联带宽的大规模 AI 模型训练任务,NVLink 版 GPU 提供了无与伦比的性能,使其成为理想选择。
对于更注重灵活性、成本和广泛兼容性的用户,PCIe 版 GPU 是轻量级工作负载和推理应用场景的绝佳选择。
定制您的英伟达AI服务器,以满足您独特的业务需求。全面评估两种GPU服务器版本的优劣,并考虑以下关键因素:
* 当前业务需求和未来增长计划
* 计算效能和成本效益
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
