在追求人工智能极限的道路上,「更大即更强」似乎已成为共识。特别是在数学推理这一被视为AI终极挑战的领域,业界普遍认为需要海量数据和复杂的强化学习才能获得突破。然而,来自上海交通大学的最新研究却给出了一个令人震惊的答案:仅需817条精心设计的样本,就能让模型在数学竞赛级别的题目上超越当前许多最先进模型。这一发现不仅挑战了传统认知,更揭示了一个可能被我们忽视的事实:大模型的数学能力或许一直都在,关键在于如何唤醒它。
 论文标题:LIMO: Less is More for Reasoning论文地址:https://arxiv.org/pdf/2502.03387代码地址:https://github.com/GAIR-NLP/LIMO数据集地址:https://huggingface.co/datasets/GAIR/LIMO模型地址:https://huggingface.co/GAIR/LIMO
论文标题:LIMO: Less is More for Reasoning论文地址:https://arxiv.org/pdf/2502.03387代码地址:https://github.com/GAIR-NLP/LIMO数据集地址:https://huggingface.co/datasets/GAIR/LIMO模型地址:https://huggingface.co/GAIR/LIMO从规模竞赛到范式创新
继OpenAI推出o1系列、打响推理能力竞赛的第一枪后,DeepSeek-R1以惊人的数学推理能力震撼业界,引发全球复现狂潮。各大公司和研究机构纷纷遵循同一范式:用更庞大的数据集,结合更复杂的强化学习(RL)算法,试图「教会」模型如何推理。
如果把经过充分预训练的大语言模型比作一名天赋异禀的学生,那么主流的RL Scaling方法就像是不停地训练、奖惩这位学生,直到他能解出各种复杂数学题。这一策略无疑带来了显著成效——从Claude到GPT-4,从o1-preview到DeepSeek-R1,每一次性能跃升的背后,都是训练数据规模的指数级增长和强化学习算法的持续优化。
然而,在这场看似无休止的数据竞赛中,上海交通大学的研究团队却提出了一个发人深省的问题:如果这位「学生」在预训练阶段已掌握了所有必要的知识,我们真的需要庞大数据集来重新训练他吗?还是只需精妙的引导,就能激活他的潜在能力?
他们的最新研究LIMO(Less Is More for Reasoning)给出了令人震撼的答案:仅用817条精心设计的训练样本,借助简单的监督微调,LIMO就全面超越了使用十万量级数据训练的主流模型,包括o1-preview和QwQ等顶级选手。这一「少即是多」的现象,不仅挑战了「更大数据 = 更强推理」的传统认知,更揭示了一个可能被忽视的事实:在AI推理能力的突破中,方向可能比力量更重要。
实验结果无可辩驳地印证了这一点。在竞赛级别的美国数学竞赛邀请赛(AIME) 测试中,相比传统方法(以Numina-Math为例),LIMO的准确率从6.5%飙升至57.1%。更令人惊讶的是LIMO的泛化能力:在10个不同的基准测试上,它实现了40.5%的绝对性能提升,超越了使用100倍数据训练的模型。这一突破直接挑战了「监督式微调主要导致记忆而非泛化」的传统观点,证明了高质量、小规模的数据,远比低效的海量训练更能激发LLM的真正推理能力。

相比使用10万条数据的NuminaMath,LIMO在使用不到1%的数据就取得了显著的进步,并在各种数学和多学科基准测试中表现出色。
Less is More:从对齐到推理的跨越

自2023年LIMA(Less Is More for Alignment)提出以来,业界逐渐意识到,在对齐(alignment)任务上,「少即是多」并非一句空话。LIMA仅用1000条高质量数据,就让大语言模型学会了如何生成符合人类偏好的对话。这个发现颠覆了「模型训练需要海量数据」的传统认知。
然而,将这一理念扩展到数学推理领域却面临着独特的挑战。与简单的对话格式不同,数学推理被认为是一项需要大量练习和训练才能掌握的复杂认知技能。这就像是教一个学生解题:教会他用礼貌的语气说话,和教会他解决复杂的数学问题,难度显然不可同日而语。因此,一个关键问题是:少即是多(Less is More)原则能否适用于推理?
LIMO的研究给出了肯定的答案,并揭示了实现这一突破的两个核心前提:
第一,知识基础革命(Knowledge Foundation Revolution)。近年来,大模型在预训练阶段已纳入海量数学知识。例如,比起全领域训练数据只有1.8T的Llama2,Llama 3仅在数学推理上的训练数据就高达3.7万亿token,这意味着现代LLM早已「知道」大量数学知识,关键是如何「唤醒」它们。第二,推理计算革命(Inference-time Computation Scaling Revolution)。最新研究表明,推理链(chain-of-thought, CoT)的长度,与模型的推理能力密切相关。与其在训练阶段硬灌大规模监督数据,不如在推理阶段提供更优质的问题和示范,让模型自主展开深入思考。基于这两点,LIMO团队提出了一个全新的理论视角:大模型的推理能力本质上是「潜伏」的而非「缺失」的。传统的RL Scaling方法在尝试「训练」模型获得新能力,而LIMO则专注于如何有效地「激活」模型本就具备的能力。正是建立在这两大基础之上,研究人员提出了LIMO假说:
在知识基础已足够完善的情况下,仅需少量高质量示例,就能通过推理链激活模型的潜在推理能力,而无需海量数据。
如果模型在预训练阶段已经获得了丰富的数学知识,那么我们或许只需要用少量但精心设计的例子,来「唤醒」这些沉睡的能力。这就像是在教导一个已经掌握了所有必要知识,却不知如何有效运用这些知识的学生。

LIMA vs LIMO: 「少即是多」现象的比较分析。
LIMO vs. RL Scaling:两种推理范式的碰撞
强化学习扩展(RL Scaling)
以OpenAI的o1系列和DeepSeek-R1为例,RL Scaling方法通常试图通过大规模的强化学习训练来增强模型的推理能力。这种方法通常依赖于海量数据及复杂的算法,虽然在某些任务上取得了显著成效,但亦有局限:它将推理能力的提升视为一个需要大量计算资源的「搜索」过程。
LIMO的新视角
与之相对,LIMO(Less Is More for Reasoning)提出了一个不同的理论框架,认为推理能力潜藏于预训练模型中,关键在于如何通过精确的认知模板来激发这些内在能力。这一转变将研究重点从「训练新能力」转向「激活潜在能力」,强调了方向的重要性。
LIMO的核心假设是,在知识基础已经足够完善的情况下,利用少量高质量的示例就能够激活模型的潜在推理能力。这一理论不仅重新定义了RL Scaling的位置,将其视为寻找最优推理轨迹的一种手段,更为整个领域的研究提供了新的思考框架。
研究意义
在当下,以DeepSeek-R1为代表的RL Scaling方法逐渐成为主流,LIMO研究的意义则在于提供了一个更加本质的视角:大模型的推理能力本身是内在存在的,关键挑战在于如何找到最优的激活路径。
这一洞察不仅重新定义了RL Scaling,将其视为寻找最优推理轨迹的一种实现方式,更重要的是,它引领了一种全新的研究范式——从「训练新能力」转向「激活潜在能力」。这一转变不仅加深了我们对大模型推理能力的理解,也为更高效的能力激活方法提供了明确的方向。
LIMO和RL Scaling的对比,揭示了推理能力提升的不同路径与思路。LIMO提供了更为根本的理解,指明了未来研究的方向:不再是无止境的数据堆砌,而是更加关注如何有效激活模型本就具备的能力。

LIMO和RL Scaling方式的比较分析。
实验验证:颠覆性的结果
LIMO的理论得到了实验结果的强力支持。仅凭817条数据,LIMO就超越了主流的OpenAI-o1-preview和QwQ等模型。它的性能相较于自身的基座模型 (Qwen2.5-32B-Instruct) 有显著的提升,更是击败了采用数十万数据的OpenThoughts和Numina Math。
在传统评测任务上,LIMO取得了突破性表现。在数学竞赛级别的AIME24测试中,LIMO赢得了57.1%的准确率,远超QwQ的50.0%和o1-preview的44.6%。在MATH500测试中,LIMO更是达到了94.8%的惊人成绩,显著超越了QwQ(89.8%)和o1-preview(85.5%)。这些数据清晰地表明,少量但精心设计的训练数据,确实能带来超越传统方法的性能提升。
在各类跨域测试中,LIMO的泛化能力同样表现出色。在奥林匹克数学测试(OlympiadBench)上,LIMO达到了66.8%的准确率,远超QwQ的58.5%;尽管LIMO数据集中不包含任何中文数据,在中国高考数学(Gaokao)测试中,它也取得了81.0%的成绩,领先于QwQ的80.1%。这种广泛的适用性让我们发现,LIMO不是简单地记忆了训练数据,而是真正掌握了数学推理的本质。
总体而言,LIMO在所有测试中的平均准确率达到了72.8%,大幅领先于o1-preview(61.1%)和QwQ(66.9%)。这个结果不仅证实了「Less is More」假说的正确性,更为整个行业指明了一个全新的发展方向:也许我们不需要无止境地堆砌数据和算力,而是应该更多地思考如何激活模型本就具备的能力。

LIMO和其他模型在多个基准测试上的性能比较。
数据的三重密码
基于LIMO假设,我们构建了高质量的数据集,并通过实验揭示了少量数据提升大模型推理能力的三大关键因素,即推理链质量、问题难度和预训练知识:
推理链质量:细节决定成败
想象一下,你在教一个学生解题。如果只是简单告诉他答案,他可能永远无法真正理解背后的逻辑。但如果你详细解释每一步的推理过程,甚至让他自己验证每一步的正确性,他就能逐渐掌握解题的精髓。LIMO的研究发现,推理链的质量对大模型的推理能力有着决定性影响。
实验表明,高质量推理链(L5)与低质量推理链(L1)之间的性能差距高达15个百分点。高质量推理链不仅逻辑清晰、步骤完整,还包含自我验证环节,确保推理的正确性。而低质量推理链往往只是简单列举步骤,缺乏详细的逻辑推导。这表明,精心设计的推理链不仅能帮助模型更好地理解问题,还能提高其推理的准确性和泛化能力。

不同质量等级(1~5)推理链训练得到的模型在AIME24和MATH500上的表现。
问题难度:挑战激发潜力
如果说推理链是解题的「路线图」,那么问题本身则是激发模型潜力的「催化剂」。LIMO的研究发现,更高难度的问题能够显著提升模型的推理能力。研究人员创建了三个不同难度的问题集:Simple-500, Complex-500和Advanced-500,分别为他们构建高质量的推理链并训练模型。实验表明,使用Advanced-500(竞赛级别问题)训练的模型,在基准测试中的准确率比使用Simple-500(简单数学题)训练的模型高出16%。
这背后的逻辑在于,更复杂的问题需要更长的推理链和更深入的知识整合,从而迫使模型在推理过程中更充分地利用其预训练知识。这就像让一个学生不断挑战更高难度的题目,他的解题能力也会随之提升。因此,选择更具挑战性的训练数据,可能是提升模型推理能力的有效策略。

不同难度问题集训练后的模型在AIME24和MATH500上的表现。
预训练知识:基础决定高度
最后,LIMO的研究强调了预训练知识的重要性。实验对比了两种架构相同但预训练数据质量不同的模型,结果显示,Qwen2.5-32B-Instruct(预训练数据质量更高)在数学推理任务上的表现显著优于Qwen1.5-32B-Chat,AIME24准确率提升了47个百分点。
这说明,模型的推理能力很大程度上依赖于其预训练阶段所掌握的知识。如果模型在预训练阶段已经接触并理解了大量数学知识,那么只需要少量高质量示例,就能激活其推理能力。反之,如果预训练知识不足,即使使用大量数据进行微调,效果也可能有限。因此,提升预训练数据的质量和多样性,可能是未来提升模型推理能力的关键。

采用LIMO数据微调相同架构、不同预训练数据的模型,二者性能区别显著。
案例与定量分析:LIMO的卓越表现
在具体的案例分析中,LIMO展现出了令人瞩目的推理能力。图5对比了Qwen2.5-32B-Instruct、DeepSeek-R1和LIMO生成的响应。尽管LIMO仅使用了817个训练样本,但其表现与DeepSeek-R1不相上下,甚至在某些方面更为出色。LIMO不仅能够进行自我反思,还能在长链推理中保持高度准确性。例如,LIMO在验证自己的陈述时表现出色:「等一下,24分钟是0.4小时?不对。60分钟是1小时,所以24分钟是24/60,也就是0.4小时。」这种自我验证和修正的能力,使得LIMO在复杂的数学推理任务中表现尤为突出。

相同问题下,不同模型的推理链和LIMO的比较。
相比之下,Qwen2.5-32B-Instruct在推理过程中表现出明显的局限性,无法纠正不准确的陈述,并且在求解方程时未能进行交叉验证。这些结果不仅支持了LIMO假设,更表明通过少量高质量的训练样本,模型可以被赋予强大的推理能力。
在定量分析中我们发现:随着训练样本质量的提高,模型生成的响应更长,行数更多,并且在推理过程中使用了更多的自我反思过渡词(例如,「等一下」、「也许」、「因此」)。这些高质量模型能够分配额外的计算资源,进行更深入的思考,从而在复杂的数学问题中表现出色。
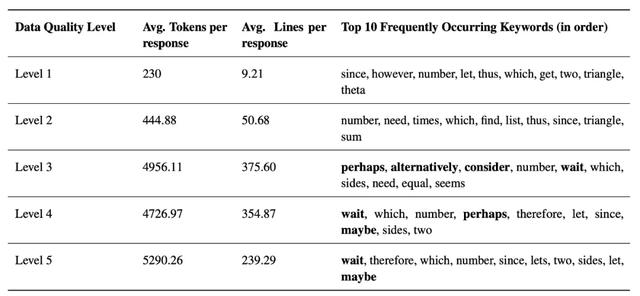
不同质量推理链的定量分析。
未来展望:少即是多的无限可能
尽管LIMO在极小数据量的情况下在数学推理方面取得了显著成功,但未来的研究仍然充满挑战和机遇。
1. 领域泛化
将LIMO假设扩展到更广泛的推理领域是一个关键方向。虽然当前的研究主要集中在数学推理上,但高质量推理链的原则可能适用于科学推理、逻辑推理和因果推理。理解这些原则如何跨领域转移,可能揭示有效推理的通用模式。这一探索需要调整质量评估标准,并开发特定领域的评估框架,从而为机器推理的理论体系做出贡献。
2. 理论基础
对LIMO成功的更深层次理论理解也至关重要。未来的研究应致力于形式化预训练知识、推理时计算和推理能力之间的关系。这包括研究有效推理所需的最小预训练知识阈值,并开发数学模型以预测推理链质量与数量之间的最佳平衡。这些理论基础可以指导更高效的训练策略,并为机器推理的本质提供洞见。
3. 自动化评估
开发自动化质量评估工具是另一个重要方向。目前对推理链质量的手动评估虽然有效,但耗时且难以扩展。未来的工作应致力于创建能够根据我们提出的指标自动评估和改进推理链质量的系统。这可能包括开发算法来自动增强现有推理链,并以最少的人工干预生成高质量推理链,从而使LIMO方法更具可扩展性和可访问性。
4. 多模态集成
跨模态推理为扩展LIMO原则提供了一个激动人心的前沿领域。由于现实世界中的推理通常涉及多种模态,研究视觉信息和结构化数据如何增强数学推理能力至关重要。这一研究方向需要开发新的多模态推理链质量评估标准,并理解不同类型的信息如何有效集成到推理过程中。
5. 实际影响
将LIMO原则应用于现实场景值得特别关注。未来的工作应致力于将这些方法应用于教育、科学研究和工业应用中的实际问题。这包括为特定领域开发专门版本的LIMO,并创建帮助人类专家生成高质量推理链的工具。这些应用可能显著影响我们在各个领域中的问题解决方式。
6. 认知科学桥梁
最后,整合认知科学的见解可以为改进提供有价值的方向。理解LIMO的推理模式与人类认知过程之间的相似性,可能有助于开发更有效的推理策略。这包括研究不同推理方法如何影响模型的性能和泛化能力,并将认知科学原则融入推理链的设计中。这样的研究不仅可以改进人工智能系统,还可以为人类推理过程提供洞见。
这些未来方向共同致力于加深我们对大语言模型中高效推理的理解,同时扩展其实际应用。通过探索这些路径,我们可以朝着开发更复杂、高效且广泛适用的推理系统迈进,以更好地服务于各个领域的人类需求。
LIMO的研究不仅挑战了「更大即更强」的传统认知,更揭示了大模型推理能力的潜在机制。通过少量高质量的训练样本,LIMO成功激活了模型的潜藏能力,展示了「少即是多」的惊人效果。这一发现不仅为未来的研究指明了方向,更为我们理解大模型的能力本质提供了新的视角。
在未来,随着LIMO假设的进一步验证和扩展,我们有望看到更多高效、精准的推理系统在各个领域中得到广泛应用。这不仅将推动人工智能技术的发展,更将深刻影响我们解决复杂问题的方式。LIMO的成功,或许只是人工智能推理能力觉醒的开始,未来的路,充满无限可能。
--机器之心
