工作中,经常有一个头疼的问题,就是去除重复值,得到唯一序列
例如,如下A列数据,我们想得到唯一数据列
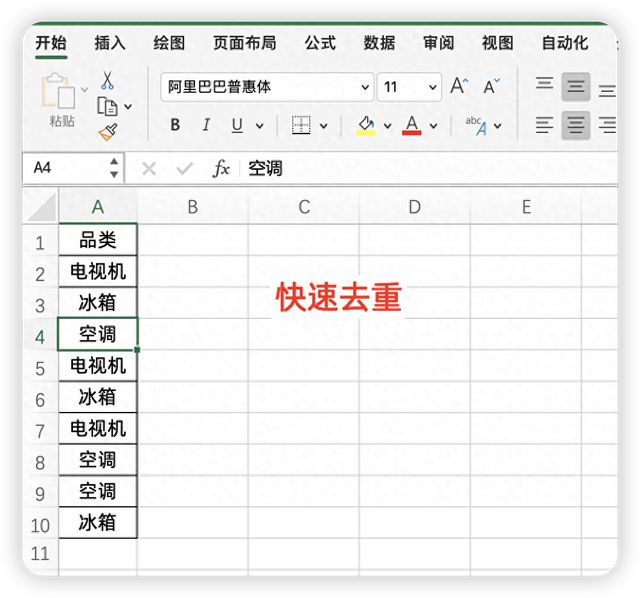
我们通常的做法是:
选中整列数据,点击数据选项卡,点击删除重复项
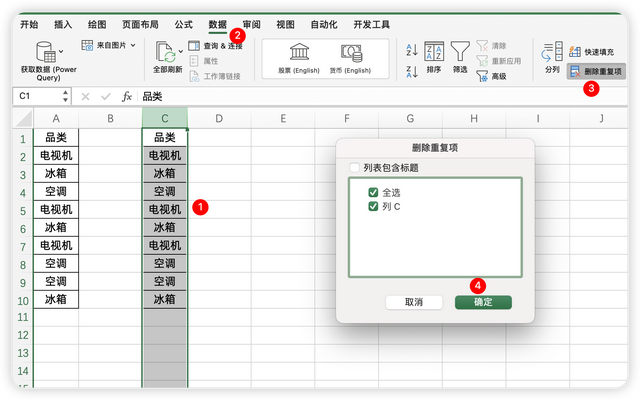
这样就得到了去重的数据,但是这种方法有个缺点,就是当我们数据列有更新的时候,又需要重新再次的去操作一次,才能得到去重的结果

为了解决这一重大痛点,Excel在最新的版本中,更新了一个函数公式,可以快速去重,那就是unique公式
当我们输入的公式是:
=UNIQUE(A1:A10)
它能提取a1:a10数据区域唯一值

有的时候,我们会继续在A11下方新增数据,所以通常我们使用的公式是:
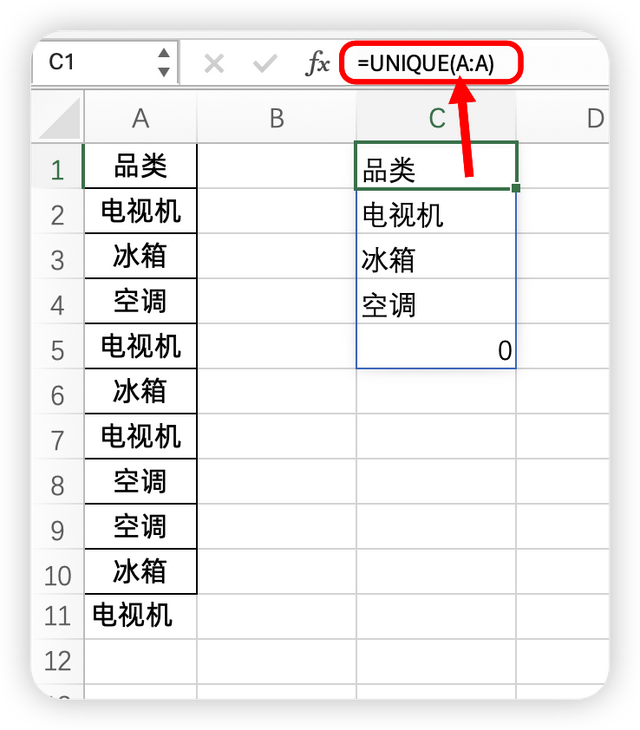
=UNIQUE(A:A)
它又会有一个新的问题,最后面的一个数据会有0小尾巴
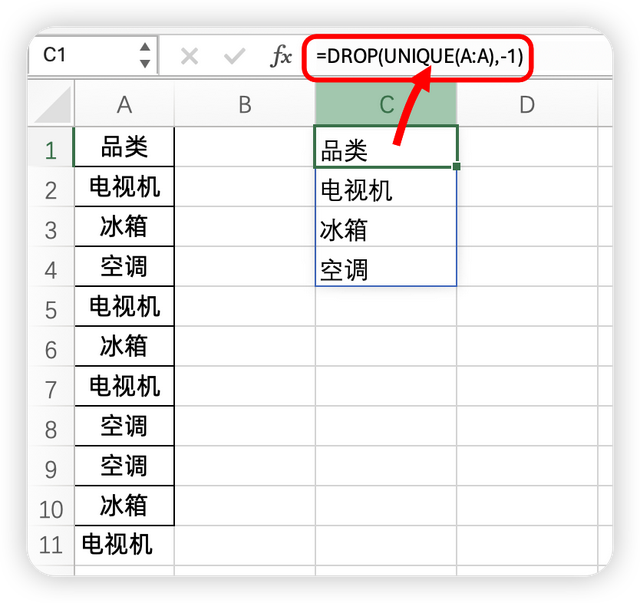
为了去掉这个小尾巴,我们可以使用DROP函数公式,去除数据
使用的公式是:
=DROP(UNIQUE(A:A),-1)
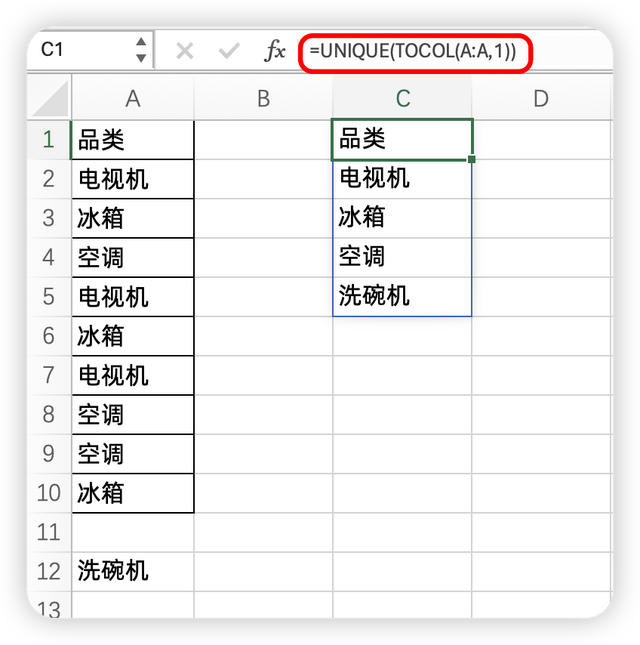
随着我们数据录入的增多,有的时候,会有一个空行出现,然后继续录入数据,那上面的drop公式又会不行了,因为空格会显示为0,然后同时drop函数公式,会丢掉最后一个元素,此时空白值,并不是最后一个元素,导致出现这样的局面

所以为了让空白值彻底丢掉,unique公式的结果不统计这个值
我们可以使用公式:
=UNIQUE(TOCOL(A:A,1))
tocol的第2参数,可以忽略掉空白值
再用unique公式轻松去掉了空白值
关于这个小技巧,你学会了么?动手试试吧!
