
本文由半导体产业纵横(ID:ICVIEWS)编译自chipsandcheese
展望英特尔 Xe3 GPU 架构。

过去几年来,英特尔在高性能图形领域的进军取得了令人瞩目的进展,而且该公司并没有松懈脚步。英特尔的 Tom Peterson表示,Xe3 硬件设计已经完成,软件工作正在进行中。
GPU 组织:更大的渲染切片?现代 GPU 是基于细分级别的层次结构构建的,因此它们可以扩展以达到不同的性能、功耗和价格目标。在英特尔 GPU 上运行的着色器程序可以通过读取(状态寄存器 0)架构寄存器的低位来检查其运行的位置sr0。

sr0Xe3 上的拓扑位具有不同的布局。渲染切片中的 Xe 核心用四位枚举,高于前几代中的两位。因此,Xe3 的拓扑位将能够处理最多 16 个 Xe 核心的渲染切片。前几代 Xe 每个渲染切片只能有四个 Xe 核心,而且通常会一直这样。B580 和 A770 都在每个渲染切片中放置了四个 Xe 核心。

拥有足够的位来描述某种配置并不意味着英特尔会推出如此大的产品。Xe 确实在 Arc A770 中使用了其最大 32 核、4096 通道设置。然而,Xe2 在 Arc B580 上最大达到了 20 核和 2560 通道。Xe2 的sr0格式理论上可以枚举 16 个切片。给每个切片最多 4 个 Xe 核心将形成一个 64 Xe 核心 GPU,具有 8192 个 FP32 通道。显然,B580 根本无法达到这个水平。

在假设的巨型 Xe2 实现上可视化着色器阵列,该实现最大化所有拓扑枚举位
Xe3 则更进一步。最大化所有拓扑枚举位将产生一个非常大的 256 Xe Core 配置,具有 32768 个 FP32 通道。这甚至比 Nvidia 的 RTX 5090 还要大,后者“仅”有 21760 个 FP32 通道。相反,笔者认为英特尔希望更灵活地扩展计算能力,而不受 ROP 和光栅化器等固定功能硬件的影响。AMD 和 Nvidia 的 SA 和 GPC 都包含远超四个核心的内核。例如,RX 6900XT 的着色器引擎各有 10 个 WGP。Nvidia 的 RTX 4090 在每个 GPC 中放置了八个 SM。随着游戏使用更复杂的着色器程序,GPU 的计算量随着时间的推移变得越来越大。英特尔似乎也在遵循同样的趋势。
XVE 变化
Xe 矢量引擎 (XVE) 在英特尔 GPU 上执行着色器程序。它们结合使用矢量级和线程级并行来隐藏延迟。
占用率更高,并行度更高
Xe3 XVE 可以同时运行 10 个线程,而前几代只有 8 个。与 CPU 上的 SMT 一样,跟踪多个线程有助于 XVE 使用线程级并行性隐藏延迟。如果一个线程停滞,XVE 有望找到一个未停滞的线程来发出指令。活动线程数也称为线程占用率。GPU 上的 100% 占用率类似于 Windows 任务管理器中的 100% 利用率。与 CPU SMT 实现不同,GPU 占用率可能受寄存器文件容量限制。
之前的英特尔 GPU 有两种寄存器分配模式。通常每个线程获得 128 个 512 位寄存器,每个线程 8 KB 寄存器。“大型 GRF”模式为每个线程提供 256 个寄存器,但由于寄存器文件容量限制,占用率降至 4 个线程。Xe3 继续为每个 XVE 使用 64 KB 寄存器文件,但灵活地在 32 个条目块中分配寄存器。只要每个线程使用 96 个或更少的寄存器,Xe3 的 XVE 就可以同时运行 10 个线程。如果着色器程序需要大量寄存器,则占用率会比前几代产品下降得更平稳。

Nvidia 和 AMD GPU 以更精细的粒度分配寄存器。例如,AMD 的 RDNA 2 以 16 个块为单位分配寄存器。但 Xe3 仍然比前几代英特尔产品更灵活。通过这一变化,只需要几个寄存器的简单着色器将通过更多的线程级并行性享受更好的延迟容忍度。而更复杂的着色器可以避免降到“大型 GRF”模式。
Xe3 的 XVE 也拥有更多的记分牌令牌。与 AMD 和 Nvidia 一样,英特尔使用编译器辅助调度来处理长延迟指令(如内存访问)。长延迟指令可以设置记分牌条目,而依赖指令可以等到该条目被清除。每个 Xe3 线程都会获得 32 个记分牌令牌,无论占用情况如何,因此 XVE 总共有 320 个记分牌令牌。在 Xe2 上,如果 XVE 运行八个线程,则线程获得 16 个令牌,或者在四个线程的“大型 GRF”模式下获得 32 个令牌。因此,Xe2 的 XVE 总共只有 128 个记分牌令牌。更多的令牌让线程拥有更多未完成的长延迟指令。这很可能转化为每个线程更多的内存级并行性。
“标量”寄存器(s0)
英特尔的 GPU ISA 有一个矢量寄存器文件(GRF,即通用寄存器文件),用于存储着色器程序的大部分数据并为矢量执行单元提供数据。它还有一个带有特殊寄存器的“架构寄存器文件”(ARF)。其中一些可以存储数据,例如累加器寄存器。但其他寄存器则用于特殊用途。例如,sr0如上所述,提供 GPU 拓扑信息,以及浮点异常状态和线程优先级。32 位指令指针指向当前指令地址,相对于指令基址。
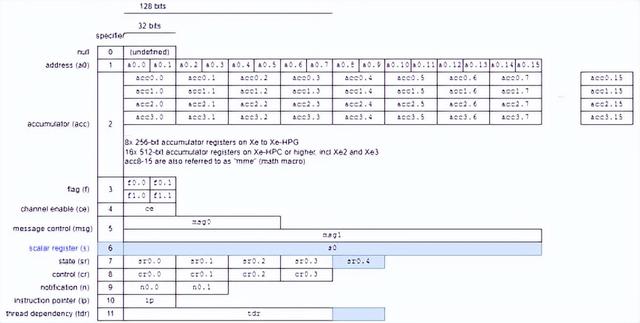
英特尔 ARF 说明,其中蓝色部分显示了从 Xe2 到 Xe3 的变化
s0Xe3在 ARF中添加了一个“标量寄存器” 。s0其布局与地址寄存器(a0)非常相似,用于收集发送指令。XVE 通过使用send指令通过 Xe Core 的消息结构发送消息来访问内存并与其他共享使用进行通信。收集发送似乎让 Xe3 从寄存器文件中收集不连续的值,并使用单个指令发送它们send。
除了添加标量寄存器之外,Xe3 还扩展了线程依赖寄存器 (TDR) 以处理 10 个线程。sr0由于未知原因获得了一个额外的 32 位双字。
指令变更
Xe3 支持 FCVT 的饱和度修饰符,这是一种在不同浮点类型之间(而不是在整数和浮点之间)进行转换的指令。FCVT 是在 Ponte Vecchio 中引入的,但饱和度修饰符可以简化从高精度浮点格式到低精度浮点格式的转换。Xe3 还获得了 HF8(半浮点 8 位)格式支持,除了 Xe2 中已经支持的 BF8 类型之外,还提供了另一种 8 位浮点格式选项。
对于 XMX 单元,Xe3 增加了一条xdpas指令。sdpas代表稀疏脉动点积与累加。具有大量零元素的矩阵称为稀疏矩阵。稀疏矩阵上的运算可以进行优化,因为任何乘以零的数显然都是零。Nvidia 和 AMD GPU 都实现了稀疏性优化,而英特尔显然也在寻求做同样的事情。
光线追踪子三角形不透明度剔除 (STOC) 将 BVH 叶节点中的三角形细分,并将子三角形标记为透明、不透明或部分透明。主要动机是减少游戏使用纹理 alpha 通道处理复杂几何图形时浪费的任意命中着色器工作。英特尔的论文以树叶为例,指出程序员可能会使用低顶点数来减少“渲染、动画甚至模拟运行时间”。
从API 角度来看,BVH 几何只能完全透明或不透明,因此游戏将所有部分透明的图元标记为透明。每个光线相交都会触发一个任意命中着色器,该着色器执行 alpha 测试。如果 alpha 测试表明光线与图元的透明部分相交,则着色器程序不会贡献样本,并且任意命中着色器启动基本上是浪费的。如果光线与完全透明或完全不透明的子三角形相交,STOC 位会让任意命中着色器跳过 alpha 测试。

摘自英特尔的论文,展示了树叶纹理的示例
存储每个子三角形的不透明度信息需要两位,因此与使用单个不透明度位存储整个三角形相比,STOC 确实需要更多存储空间。不过,它比将整个纹理打包到 BVH 中更实用。英特尔的论文发现,在处理半透明光线追踪阴影时,与标准 alpha 测试相比,纯软件 STOC 实现可将性能提高 5.9-42.2%。

Elden Ring 的 BVH 使用较大的三角形来表示 Leyndell 中的树叶,如 Radeon Raytracing Analyzer 所示。STOC 可能很好地映射到此场景
STOC 感知光线追踪硬件可以提供进一步的增益,尤其是使用英特尔的光线追踪实现时。英特尔的光线追踪加速方法与 DXR 1.0 标准非常接近。光线追踪加速器 (RTA) 通过向 Xe Core 的线程调度程序发送消息来自主处理遍历并启动命中/未命中着色器。如果光线与完全透明的子三角形相交,STOC 位可以让 RTA 跳过着色器启动。对于不透明的子三角形,RTA 可以告诉着色器程序跳过 alpha 测试,并提前终止光线。

说明 STOC 试图解决的问题
Xe3 将 STOC 位带入硬件光线追踪数据结构,复杂程度有两级。基本实现保留 64B 叶节点,但创造性地找到空间容纳 18 个额外位。英特尔的QuadLeaf结构代表一对合并的三角形。每个三角形获得 8 个 STOC 位,这意味着四个子三角形。另外两位指示任意命中着色器是否应在软件中进行 STOC 模拟,可能让程序员关闭硬件 STOC 进行调试。此模式在代码中名为“STOC1”。

为 Xe/Xe2 和 Xe3 勾画出三角形(叶)节点格式。蓝色 = STOC 相关,紫色 = 非 STOC 射线追踪数据结构变化
“STOC3”结构通过存储指向 STOC 位的指针而不是将其嵌入到 BVH 中,使事情更进一步。这允许在 STOC 位可以使用的存储量方面有更大的灵活性。STOC3 还指定了 STOC 位的递归级别,可能用于递归划分三角形。进一步细分将减少部分透明子三角形的数量,这需要从任意命中着色器进行 alpha 测试。存储 STOC3 的指针将叶节点大小增加到 128 字节,从而增加了 BVH 内存占用量。
可能的性能提升令人兴奋,但使用 STOC 需要游戏开发人员或游戏引擎的工作。英特尔建议 STOC 位可以作为游戏资产编译的一部分离线生成。艺术家必须确定使用 STOC 是否会为特定场景提供性能提升。有大量树叶的场景可能会从 STOC 中受益匪浅。铁丝网围栏可能是另一回事。STOC 不是 DirectX 或 Vulkan 标准的一部分,这可能是采用的另一个障碍。但是,纯软件 STOC 仍然可以提供好处。这可能会鼓励开发人员尝试它。如果他们确实实施了它,那么支持 STOC 的 Xe3 硬件将比纯软件解决方案获得更多收益。
距离真正的 Xe3 产品还有一段时间。但软件变化表明 Xe3 是英特尔图形架构向前迈出的又一大步。Xe2 是英特尔进军独立显卡领域的坚实一步,它以名义上较小的 GPU 提供了比 Xe 更好的性能。Xe3 再次调整了架构,可能具有类似的目标。更高的占用率和动态寄存器分配将使 Xe Cores 更能容忍延迟,从而提高利用率。这些变化也使英特尔的图形架构更接近 AMD 和 Nvidia。
XVE 的变化表明英特尔仍在忙于改进其核心计算架构。相比之下,Nvidia 的流式多处理器从 Ampere 到 Blackwell 并没有发生重大变化。Nvidia 可能觉得 Ampere 的 SM 架构已经足够好了,于是将精力转向调整功能,同时扩大 GPU 规模以继续提供代际收益。与此同时,英特尔寻求从每个 Xe 核心中获得更多收益(Xe2 以更少的 Xe 核心实现了比 Xe 更高的性能)。
与 Nvidia 类似,英特尔正在大力推进功能,显然已投入研究。GPU 通常会尝试避免做无用的工作。就像光栅化管道使用早期深度测试来避免无用的像素着色器调用一样,STOC 避免产生无用的任何命中着色器。现在判断 STOC 或其他 Xe3 功能会带来什么样的不同还为时过早。但任何怀疑英特尔致力于推动其 GPU 架构发展的人都应该认真研究 Mesa 和英特尔图形编译器的变化。
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。
想要获取半导体产业的前沿洞见、技术速递、趋势解析,关注我们!
