因为字节跳动自研交换机,早在2019年,就开始悄悄布局了。

见证全球首款51.2T全端口支持LPO的交换机——B5020,它开创了800G大规模部署的先河。
字节跳动自研交换机B5020,引领网络技术新时代。这款交换机具有51.2T的吞吐量,支持LPO,实现了800G的实际规模化部署,是全球首创。
一览B5020交换机的震撼细节,领略字节跳动的技术实力。51.2T高性能数据中心交换机的闪亮登场,字节跳动也低调宣布,实现了“在2023年全面上线自研交换机的目标”。废话不说,先戳视频,看看这款命名为B5020的51.2T交换机的细节吧。
按字节的说法,这可是全球首款51.2T全端口支持LPO的交换机,也是全球率先实现800G实际规模化部署的产品。
字节跳动系统技术公众号发布了一段关于二次剪辑关键信息的视频,重点如下:
* 识别并突出重要信息。
* 提供清晰且简短的讲解。
* 保持视频简洁扼要。
观看此视频,了解如何从海量信息中快速提取关键信息,帮助您提高剪辑效率,提升产出质量。SYS Tech),我在二次剪辑的时候,把一些关键信息摘出来Highlight了一下。
- 机架式交换机,4U高度
- 64个800GbE端口
- 51.2Tbps交换容量(全双工算法下达102.4Tbps)
- 当下业界单芯片盒式交换机的极限4U高度,64×800GbE端口。整机交换容量51.2Tbs(其实按业界全双工的算法应该是102.4Tbps),这个容量也是当下业界单芯片盒式交换机的极限。


在设计这款交换机时,字节充分考虑了散热、电源功率、机箱结构等因素,使其与下一代 102.4T 产品实现向后兼容。从功率密度角度来看,2U 机箱未必节省空间。未来,单芯片 102.4T 时代,这款 4U 交换机可以轻松容纳 128 个 800G 端口,甚至可以支持 64×1.6T 端口,让人惊叹。


字节公司在板卡设计方面独具匠心:
* 采用一张MAC-PCB板,大幅减少生产功率和成本。
* 整机内部仅用三条连接线缆,简化生产流程并降低故障率。
* 践行DFM(Design For Manufacturing)理念,实现高效生产和故障点减少。
这些创新设计极大程度地提高了生产直通率,提升产品质量,为字节公司带来了更高的生产效率和更低的生产成本。MAC-PCB板,整机内部仅用三条连接线缆。这些极简设计可以让整机生产功率大幅减少。有助于提高生产直通率,减少故障点。
以前大家学产品规划/管理的时候,都有一条叫做DFM(Design For Manufacturing)。在这里,字节就运用得很好。

突破传统限制,创领先设计:
- 28层PCB方案,高密度布线设计,实现全端口最大损耗控制在7d以下。
- 层数减少,生产难度降低,硬件成本更具竞争优势。28层PCB方案的情况下,完成高密度布线设计,而且成功将全端口最大损耗控制在7d以下。较少层数的PCB,降低了生产难度,也能更好地控制硬件成本。

字节团队在端口扇出设计上,开创性地采用大芯片布线空间复用方案,舍弃传统扇出方案,解决了远端端口信号完整性难题。此举大幅提高了大芯片的信号完整性。Fan out)设计上,字节团队摒弃了传统扇出方案(传统扇出方案在大芯片时代,远端端口难以维持信号完整性),首创了大芯片布线空间复用方案。

PCB设计论文入选DesignCon 2024并获发明专利
PCB相关设计论文在全球芯片设计领域顶级会议DesignCon 2024中脱颖而出,荣获殊荣。同时,该论文还申请了两项发明专利,彰显其原创性和技术突破性。
除PCB设计外,另一篇论文涉及业内首度采用的800G LPO技术,该技术具有功耗低、延迟低的特点,且成本更低。
这些论文的入选和专利的申请,不仅是对公司研发实力的认可,也为PCB设计领域的发展做出了贡献。相关的设计论文,入选了全球芯片设计领域的顶级会议DesignCon 2024,并申请了两项发明专利。
上面入选的论文一共三篇,其中两篇是PCB设计相关,还有一篇涉及800G LPO技术,因为这款交换机还在业内首度采用了800G LPO。
跟传统光模块相比,LPO光模块功耗低、延迟低,当然成本也更低。

这款交换机采用模块化设计,极大降低运维难度。管理引擎上的 BMC、SSD 和 DDR 内存均采用扣卡设计,简化了更换和维护流程,提高了运维效率,平均每年可节省 30% 的运维成本。
同时管理引擎上的BMC、SSD、DDR内存等,全部都是扣卡设计,大大降低了运维难度。

B5020 不是模块化机箱交换机,而是一款“盒式”机架交换机,适用于互联网数据中心/智算中心的 Leaf 或 Spine。
在胖树架构中,B5020 作为 Spine 或 Leaf,提供高速率、高密度、高性价比和易运维的解决方案。
B5020 运行字节自研的 Lambda OS,基于开源的 SONiC 开发。SONiC 生态不断完善,越来越多的互联网大厂选择基于 SONiC 开发交换机软件。有同学评价:管理引擎光模块化还不够,不支持热插拔,也不是双冗余。
其实这是对业务场景和交换机定位的误解。这款B5020并不是模块化机箱交换机,而是一款“盒式”机架交换机,应用场景是互联网数据中心/智算中心的Leaf或者Spine。在这样的场景下,一般采用胖树架构,而不是咱们常规园区或者企业网络中,双核心+汇聚+接入。


字节跳动的自研交换机已于 2023 年全面上线,覆盖了大规模交付的 100G/400G 网络。其硬件采用 JDM + CM 模式研发,软件则是自研的 Lambda OS。
JDM+CM 是业界交换机产品研发模式之一,具有高性能、低功耗、低成本的特点。字节跳动采用这种模式,可以实现对交换机的完全控制,并根据其业务需求进行定制化开发。
字节跳动自研交换机的成功,标志着其在网络设备领域取得了重大突破,进一步提升了其网络基础设施的稳定性和安全性。。根据字节跳动的说法,他们已经实现了在2023 年全面上线自研交换机的目标。
目前大规模交付的 100G/400G 网络,全由自研交换机覆盖,硬件采用 JDM + CM 模式研发,软件则是自研的 Lambda OS。说到这里,我们有必要谈谈硬件的研发模式:JDM+CM。
以交换机为例,业界的产品研发模式包括:
OEM模式,即贴牌生产,品牌商仅需贴标、修改软件界面,无需研发软硬件。这种模式易于进入市场,但利润较低。OEM模式,也就是大家常说的贴牌。交换机软硬件整机全是原厂提供,品牌商只需要贴标,修改下软件界面,就变成自家的品牌。
ODM模式,指品牌商提出定制化需求,由ODM厂商完成设计和生产。在交换机领域,品牌厂商具备软件研发能力,仅需ODM定制化硬件,尤其在白盒时代,这种模式颇为流行。ODM的灵活性高,可满足品牌商的个性化需求,但质量把控和研发能力依赖ODM厂商。ODM模式,品牌商有自己的idea,提出自己的定制化需求,然后由ODM商完成设计和生产。对交换机来说,一般品牌厂家具备软件研发能力,只需要ODM定制化硬件。尤其白盒时代,这种流行度很高。
JDM模式:深度定制,强强联合
第三级JDM模式(联合设计制造)是客户企业与交换机制造商共同参与设计和开发。客户企业需要深度参与整个过程,与制造商强强联合,实现深度定制,满足个性化需求。JDM模式,Joint Design Manufacture,联合设计制造,是客户企业(比如字节)和交换机制造商(比如数通大厂)共同参与设计和开发,企业方需要深度参与整个过程。
CM模式:合同制造,客户自设计,委托生产,生产商负责制造。该模式下,客户企业拥有产品设计与知识产权自主权,降低生产成本与库存风险,专注于产品创新与市场开拓。CM模式,Contract Manufacture,合同制造,也就是客户企业完全自行设计,然后委托给制造商生产。
字节交换机采用“JDM+CM”模式,即联合设计制造+委托生产。这种模式不是简单的贴牌,而是联合设计与委托生产的组合,更能保证产品的质量和性能。“JDM+CM”,即联合设计制造+委托生产,这可不是贴牌,人家说自研,完全没毛病。
字节进军交换机领域并不是一时兴起,而是互联网大厂自研基础设施的大势所趋。
从谷歌、Facebook到BAT,互联网巨头们都在积极布局自研基础设施,包括服务器、存储、交换机,甚至AI芯片、DPU、主芯片等。
这样做,一方面可以有效降低成本。以字节为例,每年采购交换机的支出高达数十亿元。通过自研,字节可以节省大量成本。
另一方面,自研可以满足大厂们对软件和硬件的定制化需求,让设备更纯粹地扛活。

另一方面,大厂们会根据自己的业务场景需求,来定制软件和硬件,让这些设备更纯粹的扛活。所以,更低的成本、更方便运维、极简且定制的功能,这些是大厂们看重的,其实前面视频里,字节也多次强调了成本的节省、功耗的节省、运维的简化。
这不是交换机厂商的宣传标签,这是人家真实的需求啊。

数据中心/智算中心的交换机需求量激增,主要是由于大模型时代GPU服务器场景中,一台8卡服务器需要占用8个400G/800G交换机端口,且冗余拓扑要求增加了交换机的数量需求。

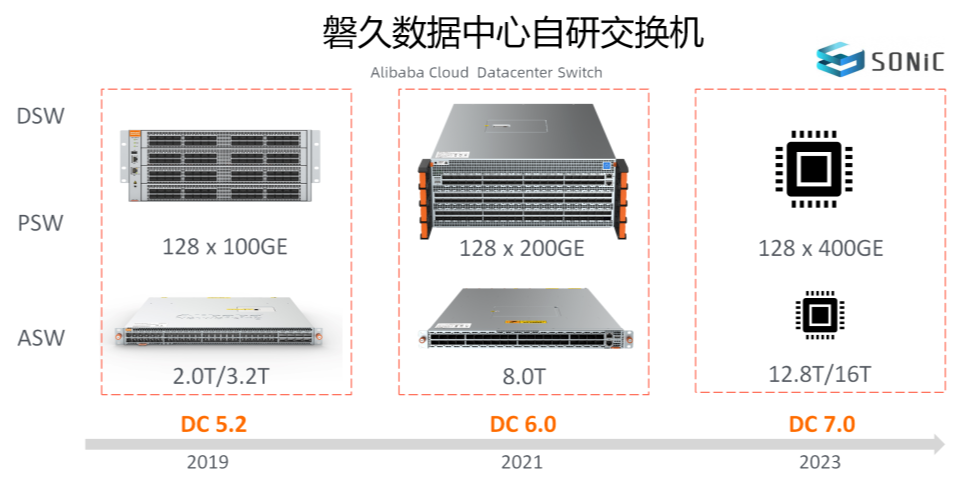
(阿里自研交换机)
鹅厂则搞出了星脉网络,而且,鹅厂不仅有交换机,还有自研的光传输呢。

(腾讯自研交换机TCS9500)
鹅厂自研光传送系统OPC-8开辟万亿级市场
根据IDC交换机市场跟踪数据,ODM Direct市场规模庞大,是互联网大厂的重要战场。其中,鹅厂自研光传送系统OPC-8便是ODM Direct的典型代表。OPC-8以其出色的性能和可靠性,为互联网大厂提供高品质的光传送解决方案,帮助其构建安全、稳定、高效的网络基础设施。OPC-8的成功,也为鹅厂在ODM Direct市场树立了标杆。(鹅厂自研光传送系统OPC-8)这块市场有多大呢,从IDC的交换机市场跟踪数据上,我们可以大概揣摩出来。
下图橙色的部分,每次排名里那个神秘的“ODM Direct”,主要就是这类互联网大厂们干的。

所以,字节做交换机,并非「突袭」,更非玩票,而是谋定后动,顺势而为。

-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
