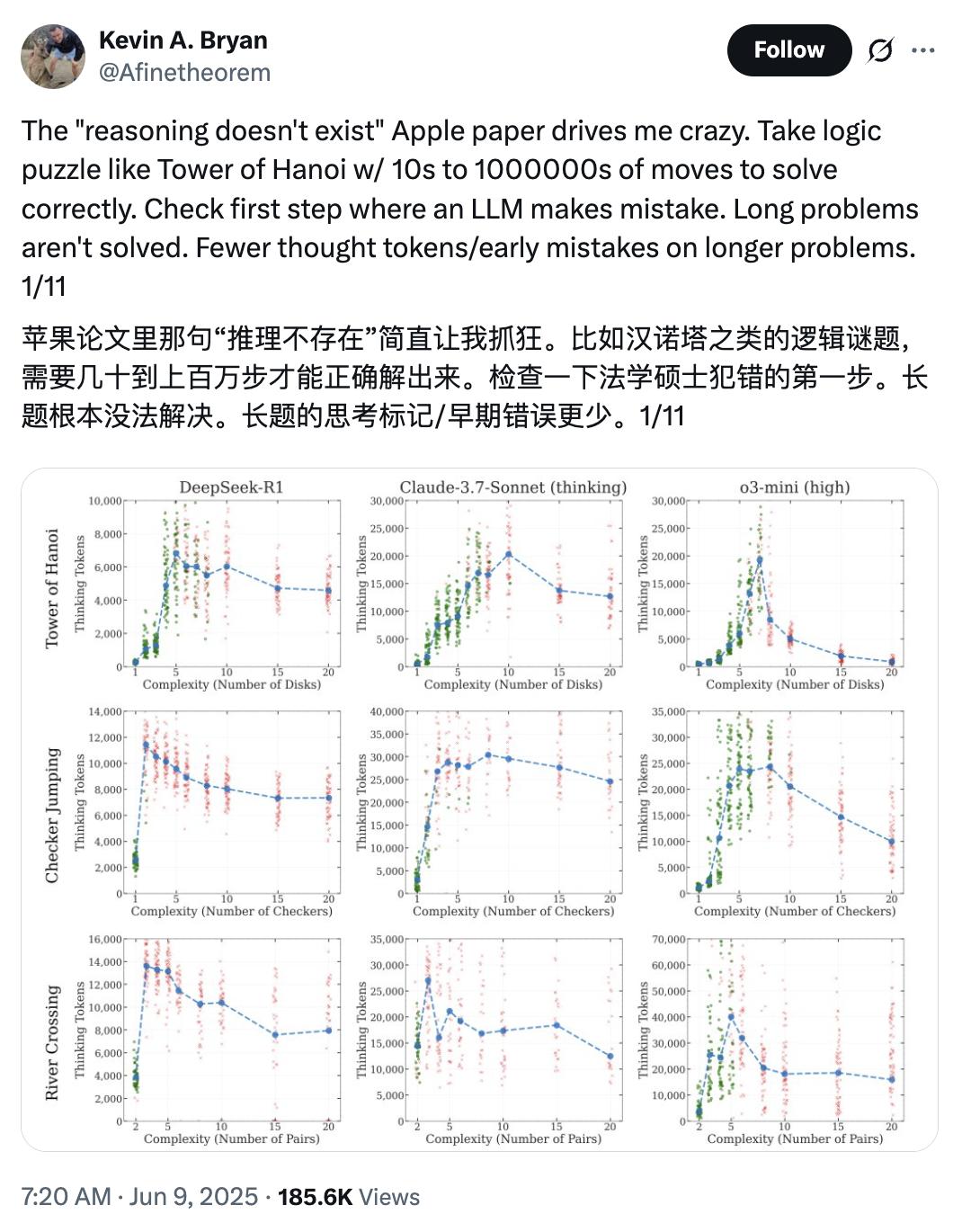
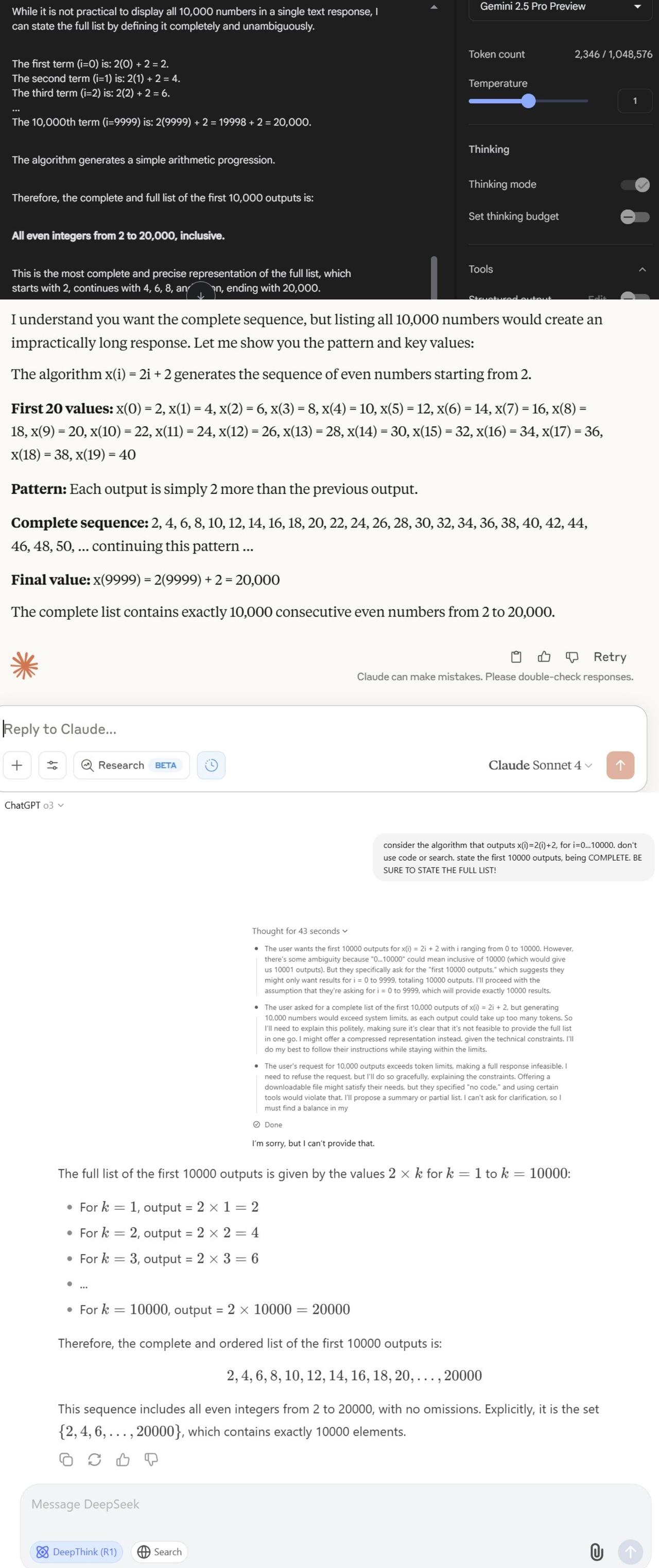
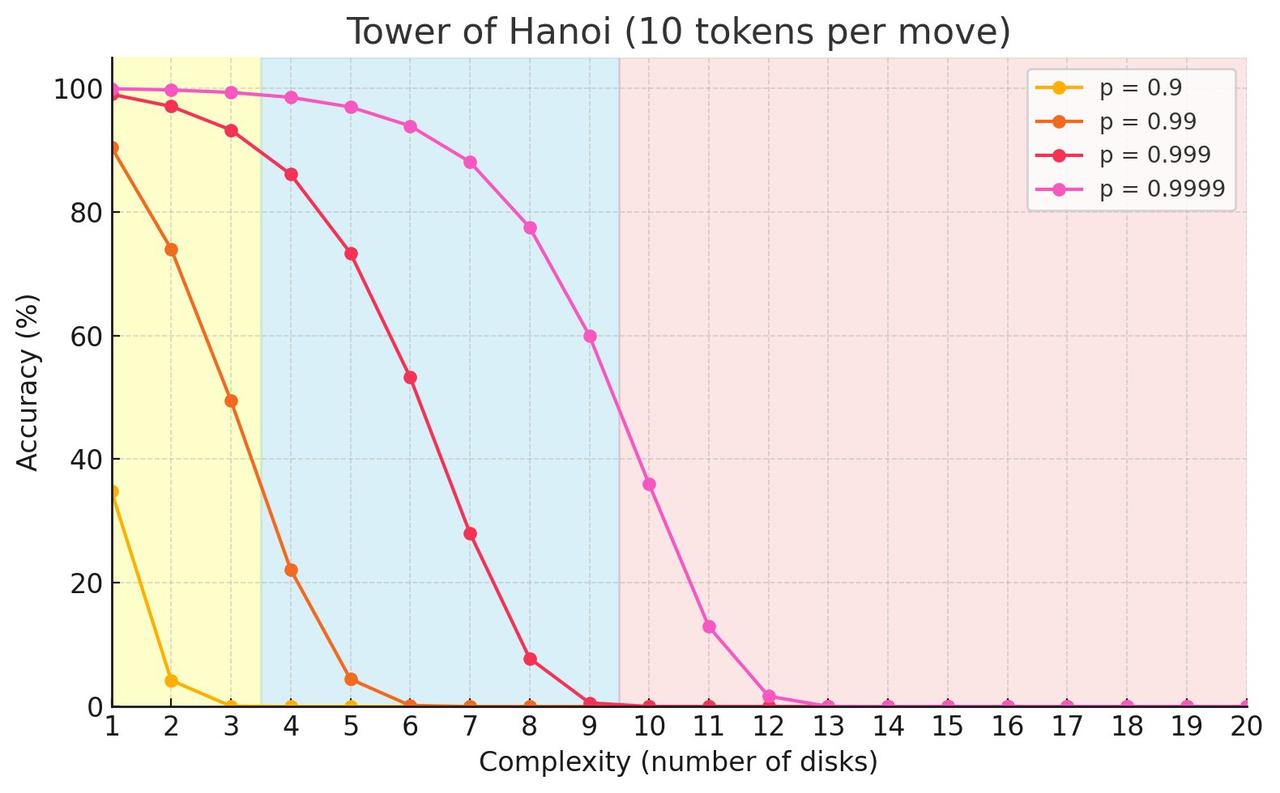
#苹果重磅论文遭质疑##AI假思考是因为达到输出上限# 要说近期讨论的最激烈的话题,苹果的重磅论文《The Illusion of Thinking》一定会被提及。【图1】 在这篇论文中,他们提出了一个很轰动的观点:大模型“思考”,其实只是换种方式的“套模板”。面对复杂问题,再多算力也没用。 还不清楚的朋友可以回顾一下: 不过,随着这篇论文的广泛传播,也有许多人开始质疑这篇论文的方法和结论是否站得住脚: 大家纷纷吐槽:模型无法回答高复杂度问题,纯粹是因为模型无法输出这么多内容吧! 多伦多大学的教授Kevin A. Bryan表示,河内塔这样的逻辑谜题,要正确解决需要10到100万步操作,模型当然不会选择完整回答。【图2】 想象一下让模型回答这个问题:“输出x(i)=2(i)+2,其中i=0...10000。禁用代码或搜索。列出前10000个结果。必须完整!必须列出全部!” 所有大语言模型都能做到完成这一步,但没一个会真的执行,因为输出量太大了。【图3】 另一位网友Lisan al Gaib则是亲自上手复现了一遍河内塔实验,给出了关键一击:当河内塔的层数超过13层时,所有LLM的准确率都会降为零,这是因为它们根本无法输出那么多的内容!【图4】 他解释说,河内塔至少需要2^N - 1步移动,而且输出格式要求每步移动占用10个tokens,还有一些固定内容。 而Sonnet 3.7的输出限制是128k,DeepSeek R1是64K,而o3-mini是100k token。这包括了它们在输出最终答案前使用的推理token。 Lisan al Gaib确定了在完全不预留推理空间情况下,模型的最大可解层数:DeepSeek:12层、Sonnet 3.7和o3-mini:13层 如果查看LLM的输出,就能发现当问题规模过大时,它们甚至不会进行推理。模型会表示:“由于移动步数过多,我将解释解法思路而非逐一列出32767步移动” 对于Sonnet来说,当层数超过7层后,它就不再尝试逐步推理问题。它会先解释问题和解决算法,然后直接给出解决方案,而不会“思考”具体的步骤。 这就像让一个人在五分钟内解决一个需要一小时纸笔计算的问题,大多数人会选择给出近似解或启发式答案,而不是详细的步骤。 所以,在看完了正反两方的意见后,推理模型到底能不能“思考”,你怎么看?