如何在AMD显卡平台部署Deepseek R1大模型可参考我之前的文章:《》
很多人不知道AMD显卡能运行什么参数的大模型,这里我以AMD Radeon RX 5700 XT 显卡实测来展示Deepseek R1运行情况,并不是传说中的4090/5090显卡才能运行大参数的大模型,我在8G显存的5700XT上就可以运行70B参数大模型。70B就是700亿参数模型,参数越大,模型就越强大越智能,目前Deepseek R1开源大模型参数最大是671B,即6710亿大模型,这么大的参数的话我等配置只能仰望了。
先说结论:70B能运行,但速度很慢,不推荐使用
32B能运行,速度一般,没必要使用
14B能流畅运行,速度快,推荐使用此版本
小于14B不推荐,因为实在不够智能,随便找个线上大模型都比这强。
 我使用的机器硬件基本配置如下:
我使用的机器硬件基本配置如下:显卡:AMD Radeon RX 5700 XT 显存为8GB
显卡驱动版本:25.1.1
内存:64GB DDR4 3000hz
CPU:intel i9 10900K
硬件配置很老,是五年前的电脑配置,依然可以成功运行Deepseek R1 70B参数模型,因为这款显卡很老了,不支持AMD最新的ROCm架构接口,只能使用Vulkan,因此如果你是新型号显卡,性能将更厉害。

我本地下载安装的Deepseek R1大模型分别为70B、32B、14B参数,使用Q4量化版。
 70B参数模型运行效果
70B参数模型运行效果启动70B参数模型可以成功启动,使用的参数如下,硬件资源占用参数越大模型运行越快,但是电脑上其它软件能用的资源就越少了,按下图参数,启动后占用30多GB内存。

70B模型对话响应速度:推理过程非常慢,差不多每秒钟响应一个字符,虽然速度很慢,但并非不能运行,对于有需要AI查询的问题,慢一些也好过直接没法使用。当然,因为Deepseek R1的火爆,目前很多第三方平台也上线部署了满血版本且支持联网搜索,比如360纳米AI就可以免费使用,可以访问网站http://bot.n.cn或下载App使用。

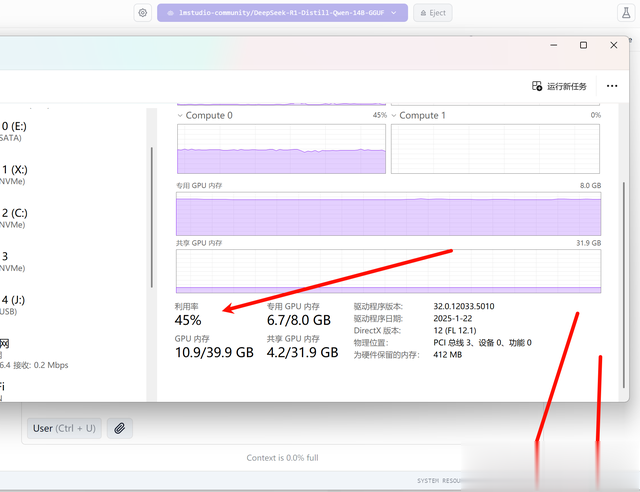
回复速度也和推理速度一样,差不多每秒一个tokens,速度实在太慢了,此时CPU占用为30%左右,内存占用为36GB左右,而显卡的占用在13%左右。

GPU占用较少是因为模型设置了GPU Offload,这个一般使用LM-Studio给出的默认选项即可,如果需要手动设置,则根据显卡配置来设置,设置的值越高,即使用GPU占用越高,显卡配置需求也越高。
 32B参数模型运行效果
32B参数模型运行效果32B大模型启动参数如下图所示

32B推理响应速度大概是70B参数量的三四倍以上,速度不是非常快,但也是勉强能接受。

32B模型按照上面的启动参数配置,运行的CPU占用大约30%、内存占用为15G、GPU占用大约25%。
 14B参数模型运行效果
14B参数模型运行效果14B大模型启动参数如下图所示

14B参数模型比32B速度大约又提升3-4倍,速度可以达到了可以接受的水平,因为是老显卡,没办法要求太多。

14B响应速度也能达到可用水平,通过AI写代码能实现正常速度,适合本地启动API接口服务,给代码编辑器调用来生成代码,关于如何在IDEA系列软件开发工具中接入Deepseek R1本地部署大模型,可以参考我之前文章《》

14B模型按照上面的启动参数配置,运行的CPU占用大约30%、内存占用为5G以内、GPU占用大约48%。
 总结
总结老显卡并非不能运行32B以上大模型,大模型运行和大模型训练并不是完全一样,都需要显卡计算,通过GPU Offload技术可以让GPU工作量分化出来。合理的设置GPU Offload以及搭配更多的RAM内存可以加快大模型运行速度。
