全文约1500 字;
阅读时间:约4分钟;
听完时间:约8分钟;

延续昨天的思路,在对工单下的子件进行分拆时,首先需要确定父件的分拆数量。这里我们使用XLOOKUP 函数来引用父件的分拆数量,而该分拆数量是通过 COUNTIFS 函数统计得出的。获得分拆数量后,子件的分拆可以分为两个主要步骤:
简单的重复:使用TEXTSPLIT、CONCAT 和 REPT 函数组合实现。
堆叠实现:使用DROP、REDUCE、LAMBDA、VSTACK 和 FILTER 函数组合实现。
对于子件的核心未领用量的分拆,则不仅仅是简单的重复与堆叠,而是需要根据工单的分拆比例来进行计算。例如,工单WK-01 的数量为 1000,被分拆成 300、300、300 和 100,对应的分拆比例分别是 30%、30%、30% 和 10%。这时就需要用子件的用量乘以相应的比例来计算分拆后的数量。
 分配比例
分配比例根据上述分析思路,我们首先要计算出工单分拆数量与分拆前工单数量的比例。为此,我们需要录入以下公式来获取堆叠后的比例:
=DROP(REDUCE("",X3#,LAMBDA(X,Y,VSTACK(X,FILTER(Q3#,M3#=Y)))),1)
公式解释:
REDUCE("", X3#, LAMBDA(X, Y, ...)):使用 REDUCE 函数遍历范围 X3#(用料分析的工单号列WK-01、WK-02等),初始化一个空字符串 "" 作为累加器 X 的起始值。对于每个遍历的元素 Y,执行给定的 LAMBDA 函数。
LAMBDA(X, Y, VSTACK(X, FILTER(Q3#, M3# = Y))):这是一个 LAMBDA 函数,它接受两个参数 X 和 Y。对于每一个 Y,使用 FILTER 函数筛选出 Q3# 中满足条件 M3# = Y 的行,然后使用 VSTACK 函数将这些行添加到累加器 X 下方。其中Q3#为MPS主计划一维表中的分配比例,M3#为主计划的工单号列。
FILTER(Q3#, M3# = Y):从范围 Q3# 中筛选出那些在 M3# 列中等于当前遍历值 Y 的行。筛选出主计划工单号等于用料分析的工单明细,返回用料分配比例。
VSTACK(X, ...):将过滤结果与累加器 X 堆叠在一起。
DROP(..., 1):最后使用 DROP 函数去除堆叠结果的第一行(即初始值),以确保结果只包含有效的数据。
综上所述,此公式用于根据分拆数量生成堆叠后的比例列表。
 未领用量
未领用量我们需要用这些比例乘以用料分析中子件的未领量。子件未领量相对于上方的Y值是在第9列,可以使用公式 OFFSET(Y, , 9) 来得到。因此,我们只需在之前的公式基础上增加这个乘法操作,就可以得到分拆后的未领量明细。录入以下公式:
=DROP(REDUCE("",X3#,LAMBDA(X,Y,VSTACK(X,FILTER(Q3#,M3#=Y)*OFFSET(Y,,9)))),1)
公式解释:
前面同上,后面用这个结果乘以子件未领料的数量;
OFFSET(Y, , 9):从当前遍历值 Y 所在的行向右偏移9列,以获取子件未领量的值。
FILTER(Q3#, M3# = Y) * OFFSET(Y, , 9):将筛选出的行与子件未领量相乘。
VSTACK(X, ...):将计算结果与累加器 X 堆叠在一起。
DROP(..., 1):最后使用 DROP 函数去除堆叠结果的第一行(即初始值),以确保结果只包含有效的数据。
综上所述,此公式用于根据分拆数量生成堆叠后的未领量明细。
效果如下图所示:
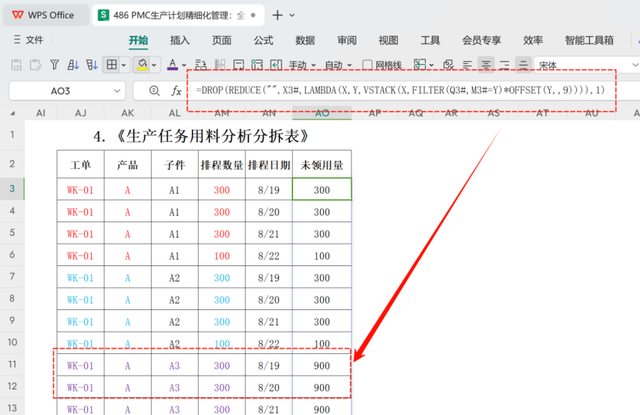 数据整理
数据整理在完成上方的用料分析后,接下来就是计算日欠料了。在计算日欠料之前,需要先对数据进行排序并引用库存。数据排序的目的在于将相同的子件按日期的升序排列在一起,以便库存能够按照排程日期的升序逐一扣减。
使用以下公式进行排序:
=TAKE(SORT(AJ3:AO30000,{3,5}),ROWS(AJ3#))
公式解释:
SORT(AJ3:AO30000, {3, 5}):对范围 AJ3:AO30000 内的数据进行升序排序。排序依据是第3列(子件)和第5列(排程日期)。
ROWS(AJ3#):计算范围 AJ3# 的行数,这里的 AJ3# 应当是指排序后的动态数组范围。
TAKE(SORT(AJ3:AO30000, {3, 5}), ROWS(AJ3#)):从排序后的数据中提取前 ROWS(AJ3#) 行,这里 ROWS(AJ3#) 的值应该是排序前范围的行数,从而保留完整的排序结果。
通过这样的操作,我们实现了对原始数据的排序,并保留了整个排序后的数据集。这样就可以确保库存的扣减是按照正确的顺序进行的。
 今日小结
今日小结今天的知识点集中在用料分析中的子件分解上。我们通过主计划的工单数量来计算分解比例,然后使用VSTACK函数堆叠重复的数据项,接着利用OFFSET函数获取子件的未领用量需求。为了确保数据的有效性,我们会使用DROP函数去除无效的空行。在整个过程中,SORT函数帮助我们对数据进行多条件排序。通过这些步骤,我们最终实现了用料分析中子件的需求分拆。
核心函数包括:
OFFSET: 偏移函数,用于确定子件的未领用量需求。
SORT: 排序函数,用于对数据进行多条件排序。
VSTACK: 堆叠函数,用于堆叠数据。
DROP: 去除函数,用于删除无效的空行数据。

