
在一个寒冷的冬日夜晚,我和朋友小王围着火炉,一边喝热茶一边聊最近的科技新闻。
他忽然问我:“你听说过DeepSeek吗?
有些人说它让AI技术普及更快,也有些人认为它不过是另一个噱头。”这一问倒引起了我的兴趣,决定查一查这个“DeepSeek”的究竟。

很多人感叹人工智能的发展速度,不知不觉中,我们的生活已经离不开各种智能工具。
这时候出现了一家名叫DeepSeek的公司,它号称能用1/11的算力实现比现有AI模型更好的性能。
这是一个什么样的存在呢?

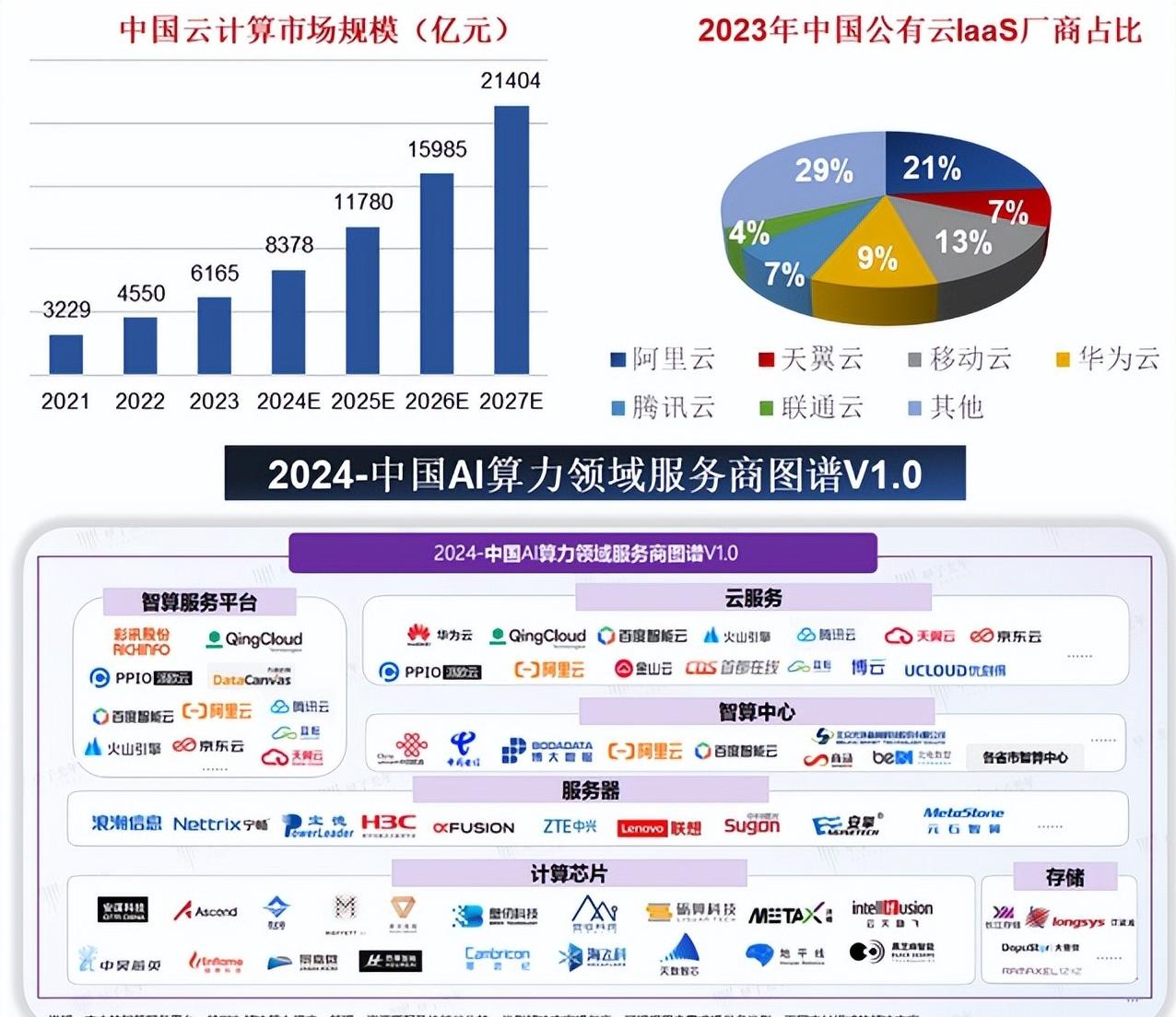
我们先来看看具体数据。
DeepSeek的V3模型,使用2000个GPU芯片,花费了557.6万美元训练出来,却超越了ChatGPT-4o模型,这背后是巨大的算力差距。
相比之下,ChatGPT-4o用了25000个GPU芯片,成本高达1亿美元。
DeepSeek不仅在成本上有优势,在数学、代码生成、中文知识问答等多个领域的测试表现也更出色。

小王听了这些数据后,忍不住感叹:“难怪大家都说DeepSeek是AI界的‘拼多多’,又便宜又好用。”
DeepSeek成功的背后原因那么,DeepSeek这么厉害的秘诀到底是什么呢?

说白了,它是怎么以更少的投入办更大的事的?
我们可以通过一个简单的例子来理解。
复习考试时,有些同学喜欢题海战术,总觉得做题越多考试就越好。
而另一些同学则擅长找到考试的重点,通过分析历年真题,集中精力在关键点上。

DeepSeek就像是后者,通过算法优化,巧妙地绕过了大量的冗余数据,仅用20%的努力达到了80%的效果。
这并不是说DeepSeek只是省钱的高手,它在技术上也有自己的独到之处。
通过分析和优化算法,DeepSeek有效地减少了算力需求,并把更多的精力放在优化训练数据上。
这就是为什么它能在兼顾性能的同时降低成本。
DeepSeek的出现,给整个AI行业带来了不小的震动。
其背后的开源策略和低成本模式,更是引起了热烈讨论。
公司宣布模型源码全公开,这一点直接让许多初创公司和研究机构省去了巨额的研发费用。

还有网友笑称,“DeepSeek一出,AI技术人人可用。”
2024年12月26日,DeepSeek一举发布了其第三代大模型DeepSeek-V3,这个被称为“来自东方的神秘力量”的模型,其训练成本不到OpenAI GPT-4的十分之一,但在性能上却能相媲美。
这些都源于技术进步和策略上的创新。

通过优化模型和算法,DeepSeek完成了一次次数据和计算能力的突破。
DeepSeek的创始人与团队许多人好奇,这样一家神奇的公司,背后到底有怎么样的团队?
DeepSeek的创始人梁文锋,同样有个“传奇”的故事。

梁文锋,浙江大学信息与电子工程专业的本科和硕士,之前创办的幻方量化名扬业内。
这家量化基金公司以其先进的AI策略和巨额投入闻名。
在2017年前后,梁文锋开始转移视线,将目光放在了人工智能上。
他的团队同样年轻,富有活力。

目前,DeepSeek团队中有139人,大都是名校出身,充满了对新技术的好奇和求知欲。
当其他公司忙于市场竞争时,DeepSeek更注重的是技术本身的进步。
梁文锋并没有将DeepSeek定位为一个商业化的巨头,而是希望通过技术普惠更多人。
他们不仅勇于开源,还在定价上不断挑战行业规则。
这种开放和务实的态度,让DeepSeek迅速崛起,成为人们口中的“AI界的拼多多”。
结尾:DeepSeek的故事让我们看到,技术进步不仅仅是巨头们的游戏,更可以是小团队的努力和创新。
通过优化和重新思考现有技术路线,DeepSeek以更低的成本实现了更高的性能,为整个行业带来了新的思路和希望。

这也给我们一个启发:有时候,突破并不一定要依赖巨额的投入和最强大的资源。
往往是那些敢于尝试新方法、跳脱旧框架的勇者,才能在创新的道路上走得更远。
DeepSeek用实际行动证明,脚踏实地的努力和对技术的热爱,终会开花结果。
希望在未来,我们能看到更多像DeepSeek一样的奇迹,让我们的生活变得更加智慧和美好。

