
通过训练一种深度神经网络复原古代希腊文本,历史学家可用其达到72%的准确性。这些发现或可以更好的速度和准确性帮助复原和判断新发现或未明铭文的归属,增进人们对古代历史的理解。相关研究3月10日发表于《自然》。
要理解古代文明的历史,历史学家会研究古人直接书写在诸如石头、陶器或金属等材料上留存至今的的铭文。然而,许多铭文都在过去的历史中受到了破坏。这些文本难以辨认,书写时间也不确定。研究这些文本的铭文学家能重建缺失文本,但传统手段非常复杂而且极为耗时。
为克服当下铭文学的限制,英国深度思维公司(DeepMind)的希腊人工智能研究科学家亚尼斯.阿塞尔博士、意大利威尼斯大学研究古希腊及古罗马文字的历史学家和铭文学家西娅.索默斯菲尔德博士、牛津大学古典学院和雅典经济与商业大学信息学系合作开发了“伊萨卡”(Ithaca)。第一个可以复原受损古希腊铭文的缺失文本,识别铭文原始位置,并帮助确定铭文书写时间的神经网络。“伊萨卡”被设计用于协助和扩展历史学家的工作流程。
深度神经网络“伊萨卡”
这项研究由DeepMind、威尼斯大学人文系、牛津大学古典学院以及雅典经济与商业大学信息学系联合完成。
Assael在希腊马其顿大学获得应用信息学文凭后,相继在牛津大学、帝国理工学院学习,最终于2019年在牛津大学获得机器学习博士。而实际上,其从2007年起就开始成为了自由开发者,彼时尚在念高中。其间还创立了AccuInstruments、LipNet Artificial Intelligence等公司。直至2017年,其加入DeepMind。Assael还曾登上2021福布斯欧洲地区“30岁以下30位精英”榜单。
Sommerschieldze则是研究古希腊和古罗马文字的历史学家和铭文学家。其将机器学习应用于研究古地中海的书写文化,她还研究古代和古典西西里岛的社会和文化历史。其现为威尼斯大学的玛丽·居里研究员,同时借调在DeepMind,她也是哈佛大学希腊研究中心的研究人员。
DeepMind在一份新闻稿中写道,人类文字的诞生标志着历史的开端,对我们理解过去的文明和今天生活的世界至关重要。例如,2500多年前,希腊人开始在石头、陶器和金属上书写,记录从租约、法律到日历和预言的一切,让人们对地中海地区有了详细的了解。
然而,Assael等人意识到一个问题,这些记录通常都是不完整的。许多幸存下来的铭文在几个世纪的时间里遭到了破坏,或者从原来的位置被移走或者贩运。此外,现代年代测定技术,如放射性碳年代测定法,无法在这些材料上使用。而传统的铭文学方法涉及到高度复杂、耗时和专业的工作流程,这使得解读铭文既困难又费时。
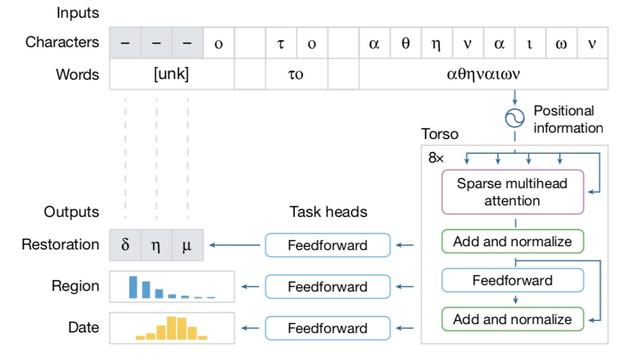
伊萨卡处理δήμο το αθηναίων’ (the people of Athens)的过程。该短语的前三个字符被隐藏
Assael对澎湃新闻记者表示,在将人工智能切入到铭文复原中,他们的工作涉及三项主要的任务,“文本复原、确定原始的地理位置,以及追溯至铭文书写的时间。”
他们在论文中也指出,受生物神经网络的启发,深度神经网络可以发现和利用大量数据中复杂的统计模式。而近年来计算能力的提高,使这些模型能够应对包括古代语言研究在内的许多领域中日益复杂的挑战。
Assael将目标旨在完成上述三项任务的深度神经网络命名为伊萨卡(Ithaca),该工作始于2019年。“伊萨卡接受了近8万份由帕卡德人文学院(PHI,一个非营利性基金会)提供的希腊铭文数字数据集的培训,它的架构旨在捕捉上下文并有效地处理受损的单词,同时它还可以并行地“注意”输入的不同部分。”他表示。
 阿塞尔博士和索默斯菲尔德博士
阿塞尔博士和索默斯菲尔德博士北京时间3月10日凌晨,国际顶级学术期刊《自然》(Nature)在线发表了Assael和Sommerschield作为共同通讯作者的一项新研究,题为“使用深度神经网络复原和归因古代文本”( Restoring and attributing ancient texts using deep neural networks)。研究团队训练了一种深度神经网络,名为伊萨卡(Ithaca)。

伊萨卡是以荷马史诗《奥德赛》中的希腊岛屿伊萨卡命名,是古希腊神话英雄奥德修斯的故乡。“我们开发的伊萨卡是第一个可以复原受损铭文的缺失文本、识别铭文原始位置、确定创建日期的深度神经网络。”
这些希腊铭文的时间跨度在公元前7世纪至公元5世纪,并横跨古地中海世界。
评估显示,伊萨卡单独使用于复原受损希腊铭文文本时可达到62%的准确率,在历史学家使用时可达72%的准确度。而且,伊萨卡还能协助确定铭文的书写位置和时间。在实验中,它能以71%的准确度判断这些铭文的原始位置,鉴定年代与历史学家提出的范围相差少于30年。
在年代方面,为增加可解释性,伊萨卡也不是输出一个单一的时间,而是预测时间的分类分布。更准确地说,伊萨卡将公元前800年至公元800年之间的所有时间处理为,取每10年为一个跨度,也就是说有160个10年。例如,如果日期范围在公元前300至公元前250年间,也就是5个10年,每一个概率分别为20%;而日期如果在公元前305年,则将以100%的概率指定为出自公元前300至公元前310年。
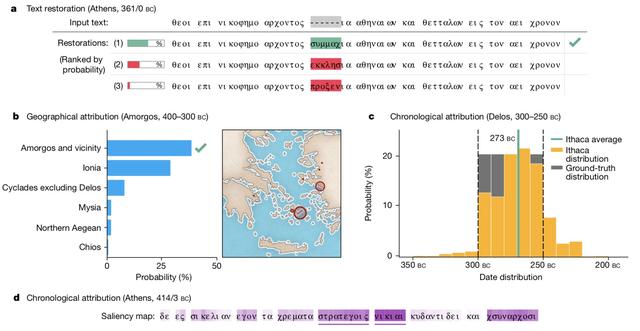
评估显示,在复原文本方面,伊萨卡始终优于其他竞争方法,字符错误率(CER)为26.3%,top 1准确率为61.8%。对复原铭文文本和确定原始的地理位置方面,研究团队还引用top-k准确率来衡量,即正确的复原或地理位置是否在前k项预测中。
具体来说,与人类历史学家相比,伊萨卡实现了更低的字符错误率(CER),人类历史学家该项分数为59.6%。另外,与研究团队此前开发的专注于文本复原的皮提亚(Pythia)相比,表现也更为优秀。皮提亚名字取自希腊神殿德尔斐中为阿波罗神传达神谕的女祭司。在文本复原方面,皮提亚皮的字符错误率(CER)为47.0%,虽然高于伊萨卡,但也高于人类历史学家。
值得注意的是,当人类历史学家与伊萨卡合作时,历史学家的字符错误率(CER)大幅降低到18.3%,top 1准确率则从25.3%大幅提升至71.7%。
研究团队认为,这些发现或可释放人工智能与历史学家的合作潜力,并改进我们对人类历史的理解。“我们确实看到了文化和人文领域人工智能跨学科研究的巨大潜力。”Assael强调。
