
4月29日凌晨,阿里巴巴宣布开源新一代通义千问模型 Qwen3(简称千问 3),以其参数量仅为 DeepSeek-R1 的 1/3、成本大幅下降,且性能全面超越R1、OpenAI-o1 等全球顶尖模型,登顶全球最强开源模型,引发了行业的广泛关注。
据悉,千问3还提供了丰富的模型版本,包含2款MoE模型235B-A22B、以及30B-A3B; 6款Dense(密集)模型32B、14B、8B、4B、1.7B和0.6B,均在Apache 2.0 许可下开源。
 千问3的核心亮点,全球首个开源的混合推理模型
千问3的核心亮点,全球首个开源的混合推理模型千问3的最大亮点在于它是国内首个 “混合推理模型”,将 “快思考” 与 “慢思考” 集成进同一个模型,大大节省算力消耗。
具体来看,对于简单的需求,如日常聊天等,千问3可以低算力“秒回”答案,实现快速响应;
而对于复杂的逻辑推理、数学和编码等任务,则能够进行多步骤的“深度思考”,从而大大节省算力消耗。这种混合推理模式增强了模型实现稳定且高效的 “思考预算” 控制能力,使其在不同场景下都能表现出色。
同时,这样的设计也能让用户能够更轻松地为不同任务配置特定的预算,更好的控制成本。

在架构方面,千问3采用混合专家(MoE)架构,总参数量为 235B,但激活仅需22B。相比于传统的密集模型架构,MoE 架构能够更高效地利用计算资源,避免了对所有参数进行计算的冗余操作,大大降低了计算成本。
这种设计使千问3在显存占用上仅为性能相近模型的1/3。
成本方面,可以对比满血版671B DeepSeek-R1。据悉,千问3旗舰版本235B仅需4张H20显卡即可部署。有测试显示,同类模型DeepSeek-R1满血版需8张H20(成本100万元左右)。
意味着,千问3的部署成本直接降至约50万元,降幅达50%。
与此同时,千问3模型还首次支持119种语言和方言,覆盖中文(含粤语)、英语、法语、德语、阿拉伯语等主流语种及方言。
这一广泛的多语言能力为国际应用开辟了新的可能性,让全球用户都能受益于这些模型的强大功能。
 千问3的性能,刷新多项开源纪录
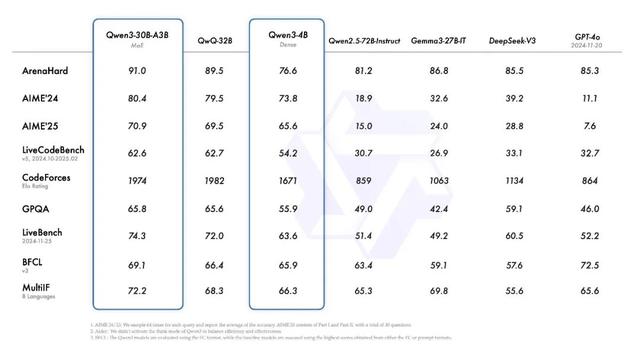
千问3的性能,刷新多项开源纪录据介绍,旗舰模型千问3-235B-A22B在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro等顶级模型相比,表现出极具竞争力的结果。
此外,小型MoE模型30B-A3B的激活参数数量是QwQ-32B的10%,表现更胜一筹,甚至像千问3-4B这样的小模型也能匹敌千问2.5-72B-Instruct 的性能。

例如在奥数水平的AIME25 测评中,千问3以81.5分刷新了开源纪录;
在考察代码能力的LiveCodeBench测评中,突破70分大关,表现甚至超过了马斯克旗下Grok3等国际主流模型;
在评估模型人类偏好对齐的ArenaHard 测评中,以95.6分超越DeepSeek-R1及OpenAI-o1。
此外,在GPQA、AIME24/25 等测评中也取得了优异成绩,创下所有国产模型及全球开源模型的性能新高。
在工具调用方面,千问3原生支持MCP协议,并具备强大的工具调用能力,结合 Qwen-Agent 框架,大大降低了编码复杂性,可实现高效的手机及电脑Agent操作等任务,为即将到来的智能体Agent和大模型应用爆发提供了更好的支持。
李飞飞团队等调用,基于千问衍生模型已全球第一阿里通义千问的团队表示,千问3的发布和开源将极大地推动大型基础模型的研究与开发。“我们的目标是为全球的研究人员、开发者和组织赋能,帮助他们利用这些前沿模型构建创新解决方案。”
关于阿里对于模型开源历史方面。据悉,早在2022年11 月初,阿里就上线了开源模型分享平台魔搭社区,一口气开源了达摩院成立 5 年来研发的所有近400个模型。
2023年8月开始,阿里云通义千问又相继推出Qwen、Qwen1.5、Qwen2、Qwen2.5,以及如今的Qwen3等开源大模型。涵盖大语言模型、多模态模型、数学模型和代码模型等数十款产品,且屡次在多个国内外权威评测中创下佳绩,展现出全球领先的性能水平。
与此同时,阿里的大模型也在业界得到广泛应用和认可。

例如,今年2月,李飞飞等斯坦福大学和华盛顿大学的研究人员,就基于阿里通义千问Qwen2.5-32B-Instruct开源模型为底座,通过26分钟的监督微调,以不到50美元的费用,打造出了性能卓越比肩OpenAI的O1和DeepSeek的R1等尖端推理模型的s1-32B模型。
迄今为止,Qwen系列大模型已被累计下载3亿次(综合Hugging Face、魔搭等社区数据)其中2.5亿次是最近7个月新增的;基于Qwen的衍生模型数量超10万个,为全球第一。
