
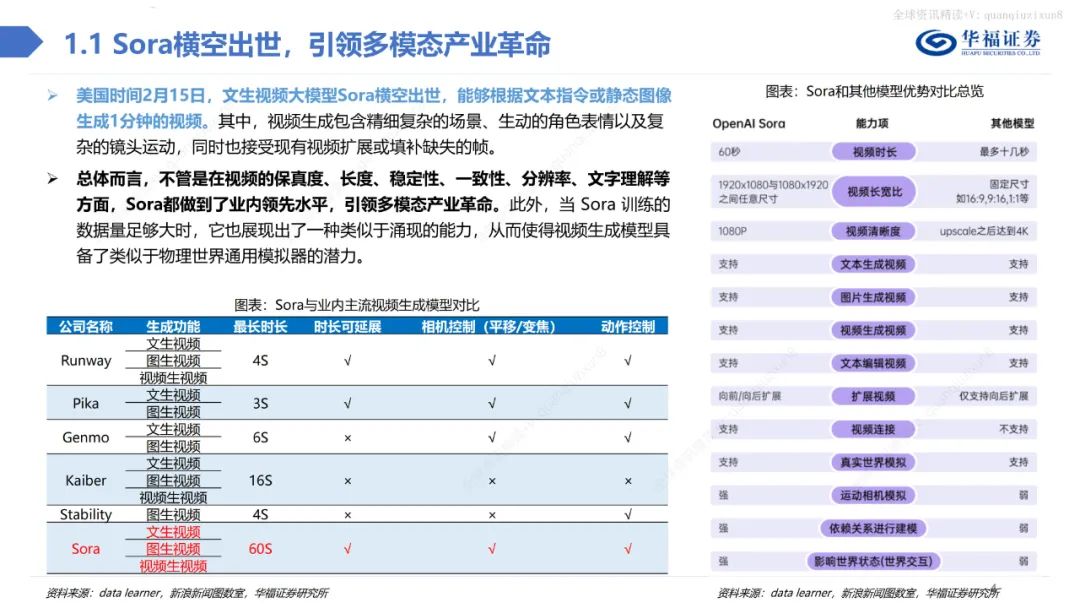
文生视频大模型Sora横空出世,能够根据文本指令或静态图像生成1分钟的视频。其中,视频生成包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,同时也接受现有视频扩展或填补缺失的帧。
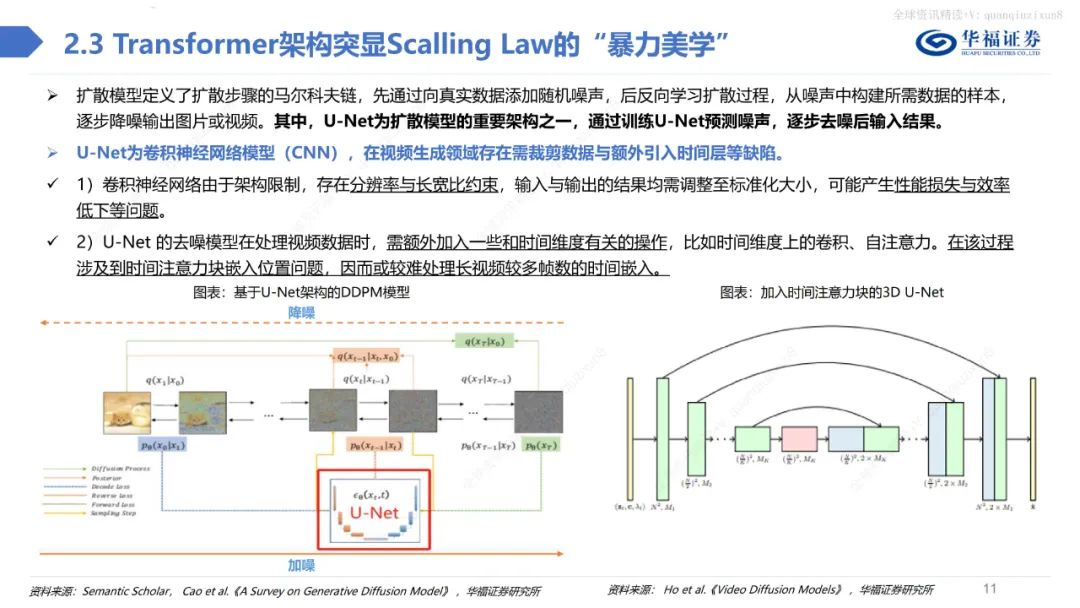
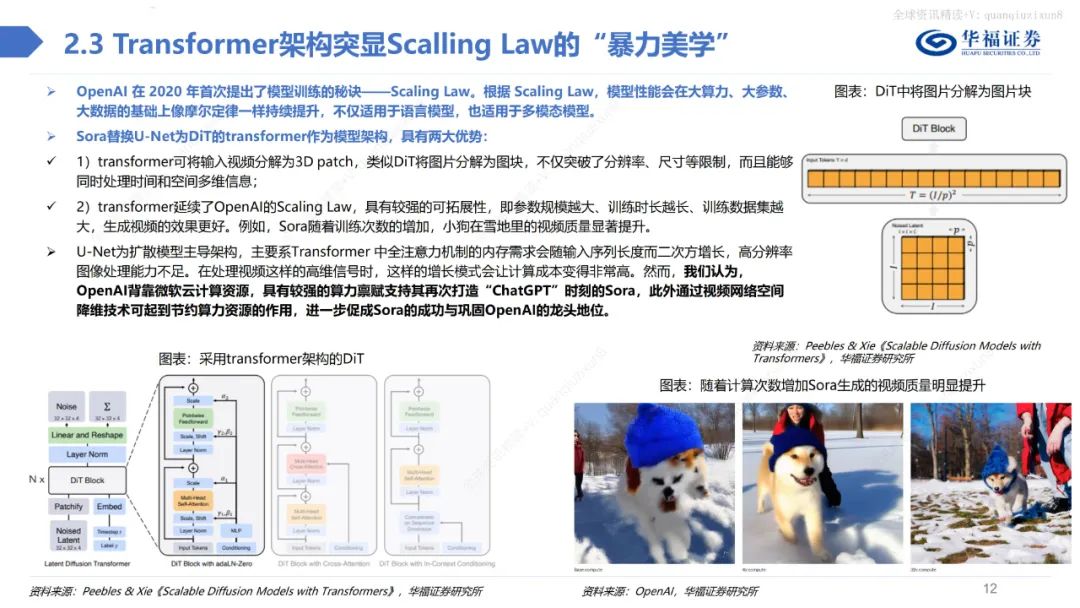
总体而言,不管是在视频的保真度、长度、稳定性、一致性、分辨率、文字理解等方面,Sora都做到了业内领先水平,引领多模态产业革命。此外,当Sora训练的数据量足够大时,它也展现出了一种类似于涌现的能力,从而使得视频生成模型具备了类似于物理世界通用模拟器的潜力。Sora借鉴LLM中将文本信息转化为token的思路,针对视频训练视觉patch,实现视觉数据模型的统一表达,实现对多样化视频和图像内容的有效处理和生成,之后通过视频压缩网络分解为时空patches,允许模型在时间和空间范围内进行信息交换和操作。
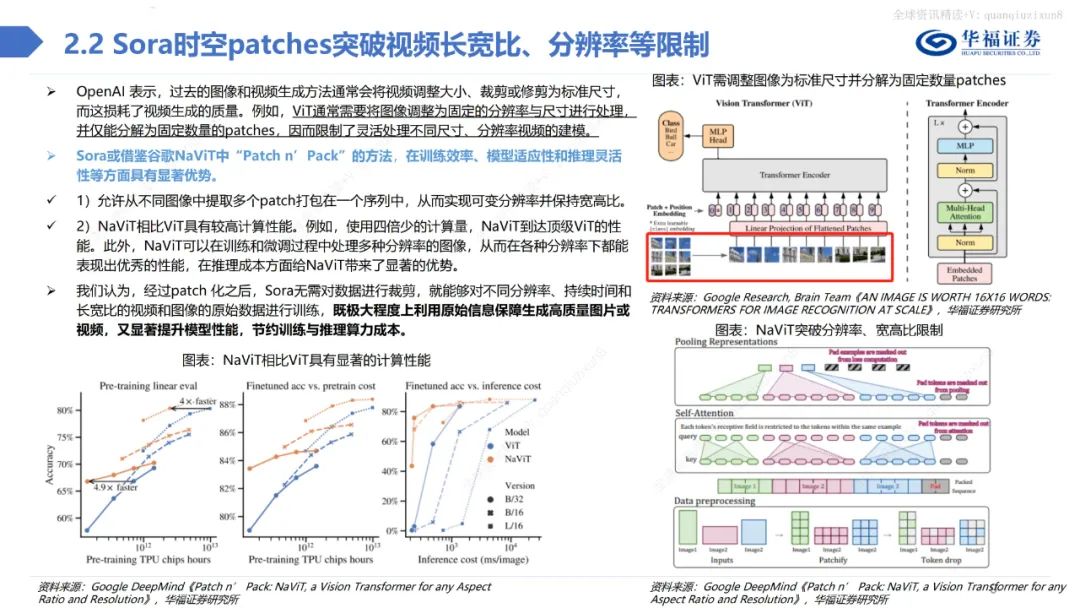
从Sora技术报告来看,时空patches或借鉴谷歌ViViT操作。ViViT借鉴ViT在图片分割上的思路,把输入的视频划分成若干个tuplet,每个tuplet会变成一个token,经过spatial temperal attention进行空间和时间建模获得有效的视频表征token。传统方法可能将视频简单分解为一系列连续的帧,因而忽略了视频中的空间信息,也就是在每一帧中物体的位置和运动。
我们认为,由于连续帧存在时空连续性,Sora的时空patches可同时考虑视频中时间和空间关系,能够更加精准生成视频,捕捉到视频中细微的动作和变化,在保证视频内容连贯性和长度的同时,创造出丰富多样的视觉效果,灵活满足用户的各种需求。







Sora:AIGC领域的划时代成就
Sora模型的横空出世,标志着AIGC行业的重大里程碑。基于MOE架构,谷歌Gemini大模型性能再创新高。
Sora以惊人的算力加速了文生视频的应用,引发AIGC持续正向循环。计算机行业研究表明,Sora将为全球文视频领域带来重大机遇。
Sora的突破性技术开启了创意领域的新篇章,堪比iPhone时刻,重新定义了文生视频的可能性。
《OpenAI新工具Sora,文字秒生短片》
OpenAI推出创新工具Sora,只需一句提示就能生成精彩的60秒短片。然而,Sora目前存在技术缺陷,导致生成视频偶尔会穿帮,暂时限制了其公开使用。
OpenAI发布首款文生视频大模型Sora,训练算力需求大幅提升
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
