8万亿训练数据,性能超LLaMA-2,英伟达推出Nemotron-4 15B

英伟达推出 Nemotron-4 15B,这是一个拥有150亿参数的先进大语言模型,得益于8万亿文本标注数据的预训练,具备强大理解和生成文本的能力。
Nemotron-4 15B 的性能超越同类开源模型,在测试中超越了 7 个领域中的 4 个,展现非凡的能力。它在其他领域也表现出色,证明了其多功能性和潜力。
Nemotron-4 15B架构
Nemotron-4 15B 采用革命性的 Transformer 架构,利用自注意力机制实现卓越的自然语言处理能力。

Transformer采用层叠式设计,每一层包含多头自注意力机制和前馈神经网络。自注意力机制捕捉序列中位置间的关联性,而前馈神经网络进行非线性变换,增强模型对输入序列的理解。
解码器:Nemotron-4 15B
Nemotron-4 15B 采用 Transformer 架构,其解码器仅使用部分 Transformer 层。解码器通过自注意力机制和前馈网络处理输入序列,将其转换为输出序列。
注意力机制赋能Nemotron-4 15B:
自注意力:揭示输入序列内部关联。
全局注意力:连接输入和输出序列。

多头注意力机制:Nemotron-4 15B中,每个注意力层包含多个独立的头部,每个头部针对特定信息特征进行训练。这增强了模型捕获复杂关系和深层语义理解的能力。
位置编码赋予序列中的每个位置位置信息。Nemotron-4 15B采用旋转位置编码技术,在处理输入序列时融入位置信息,增强了对序列内顺序关系的感知。
Nemotron-4 15B数据与训练流程
Nemotron-4 15B数据集包含:
* 英语自然语言:70%
* 多语言自然语言:15%
* 源代码:15%
为提高准确性,构建预训练语料库时,我们剔除了重复数据,并进行了严格过滤。这让我们的模型具备了更高的可靠性和鲁棒性。

凭借384个DGX H100节点,每个节点配备8个NVIDIA Hopper H100 GPU,Nemotron-4 15B的训练突破了界限。创新性的训练技术包括八路张量并行和大规模分布式优化器分片,确保了高效的模型训练。
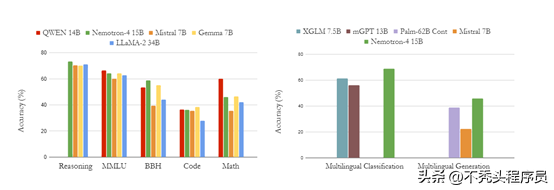
Nemotron-4 15B 在英语评估中表现出色,超越 LLaMA-2 34B 和 Mistral 7B。其表现与 QWEN 14B 和 Gemma 7B 相近,展示了在自然语言处理方面的强大能力。

Nemotron-4 15B展现出卓越准确率,在资源受限的编程语言中超越竞争对手,包括Starcoder和Mistral 7B。
