
今年1月下旬,中国人工智能(AI)大模型技术厂商DeepSeek(深度求索)发布推理大模型DeepSeek-R1,并将其开源。相关数据显示,DeepSeek-R1不仅性能比肩当时最强的OpenAI o1,训练成本可能只有后者的约1/20,API的定价更是只有后者的约1/28,相当于使用成本也降低了约97%。简单来说就是,DeepSeek-R1不仅好用,而且部署和使用成本也得到了极大降低,这也使得DeepSeek-R1在发布之后就持续火爆网络。
但是随着DeepSeek官方APP及API用户量和需求激增,导致DeepSeek官方服务器持续处于超负荷状态,不仅普通用户在访问过程中频繁遇到“服务器繁忙”,调用API的用户也面临不稳定的问题。对此,许多企业用户也开始转向第三方DeepSeek云服务或本地化部署。
面对激增的市场需求,众多的国内外一线云服务厂商纷纷上线了各种版本的DeepSeek模型的云服务。1月30日,微软宣布DeepSeek R1已正式纳入Azure AI Foundry,成为其AI服务的一部分。1月31日,亚马逊宣布,DeepSeek R1可在AWS平台使用,提升电商、数据分析等领域的AI服务效率。随后,百度云、阿里云、腾讯云、华为云等国内云厂商也纷纷上线DeepSeek R1/V3推理模型服务,支持科研、医疗、工业等多个领域的AI推理需求。
不过,一些对数据隐私和信息安全更为敏感、稳定性要求更高、或者有二次训练需求的企业级用户来说,更倾向于在本地部署DeepSeek R1/V3模型,毕竟这些模型都已开源,且对于硬件的需求相较于同等参数量级的Llama 3等开源模型大幅降低,这也极大的推动了企业级用户通过本地化部署来助力DeepSeek R1/V3模型,助力企业AI转型的热情。
DeepSeek模型私有化部署带来的挑战
DeepSeek大模型根据不同的模型规模分为不同的版本,以满足不同应用场景的需求。从最初的V1版本到当前的R1蒸馏版及其满血版671B(6710亿参数),DeepSeek的进化不仅体现在模型的参数规模和推理能力上,也在硬件需求、应用场景和部署成本等方面逐步优化和调整。

△DeepSeek模型的不同版本
其中, 以DeepSeek R1蒸馏版(70B)为例,其模型规模为70B(700亿参数,基于Qwen或Llama架构的蒸馏版本),对于硬件要求相对较低,FP16显存需求为140GB,但是4-bit量化显存只需要约35-50GB。因此,2×RTX 4090(24GB显存)或4×RTX 3090(24GB显存)并行即可满足本地化部署需求。
DeepSeek R1 蒸馏版(70B)模型在保持较高性能的同时,显著降低了模型规模和对硬件的要求,部署成本大大降低,适合个人及小微企业应用和开发测试。虽然DeepSeek蒸馏版(70B)模型降低了部署门槛,但在高精度任务上有所妥协,这也在某种程度上降低了其生产力。
相比之下,DeepSeek R1满血版(671B)模型该版本代表了DeepSeek的极限性能,适用于超大规模的AI训练和推理任务。尽管训练成本高昂,但在学术研究和超高精度任务中,DeepSeek满血版提供了前所未有的推理能力,能够生成高质量的科研报告、论文框架等。因此,更多的企业级用户更倾向于在本地部署DeepSeek R1满血版(671B)模型,以便更好的满足企业级的需求,但是这也带来了对于硬件更高的要求。
据了解,DeepSeek R1满血版(671B)模型在FP16精度下,显存需求高达1.34TB,4-bit量化显存也需要约350GB,至少需要16张NVIDIA H100 80GB + NVLink/InfiniBand互联才能满足本地化部署要求。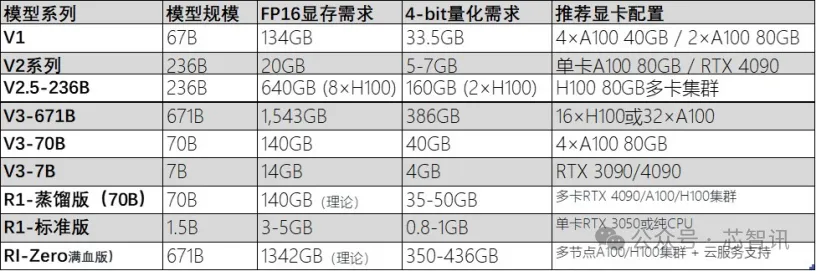
△不同deepseek模型对硬件配置的要求
总结来说,DeepSeek 每个版本的参数规模、硬件需求和适用场景各不相同,用户可以根据自身的需求选择合适的版本进行部署。对于个人开发者、小型企业和中等复杂度任务,推荐使用DeepSeek标准版(如V2、V2.5)或蒸馏版(如R1-70B)。这些版本要求较低的硬件配置,如单卡RTX 3090或A100,并且可以在本地进行部署,降低了成本。
大型企业和科研机构需要处理超大规模任务时,则需要选择DeepSeek R1满血版(671B)。这些版本适合高性能推理和训练,尤其是在金融、科研计算等精密领域。R1满血版要求极高的硬件支持,需要多卡集群(如16×A100或32×H100),部署成本非常高。对于科研机构,可能通过云服务进行资源调配,避免本地硬件的高昂费用。
百度昆仑芯支持单机部署DeepSeek满血版
对于大模型来说,要想高效、快速、稳定地输出高质量内容,则需要强大的AI芯片来作为支撑。目前在大模型训练方面,英伟达的H100是市场的领导者,其可以提供1979 TFLOPS(FP16)和3958 TOPS(INT8)的强大算力,适用于大规模的训练任务。但是在AI推理方面,各类AI芯片可谓是百花齐放。特别是的DeepSeek的推理模型,通过蒸馏模型(如DeepSeek-R1-Distill-Qwen和DeepSeek-R1-Distill-Llama)、MoE(专家混合系统)、MLA(多头潜在注意力机制)等创新技术,显著降低了计算开销,同时维持了模型的高性能。这使得国产AI芯片厂商能够在推理任务中与英伟达GPU竞争,甚至在某些场景中表现更好。
据不完全统计,到2025年2月,至少有20家国产芯片厂商宣布与DeepSeek展开合作,其中就包括了华为昇腾、百度昆仑芯、海光、沐曦集成电路、摩尔线程、天数智芯等知名AI芯片厂商。通过国产AI模型+国产AI芯片的组合,国内AI生态开始打破英伟达的CUDA生态限制,推动“国产算力+国产大模型”生态系统的建设。
以百度昆仑芯P800为例,其XPU-R架构将通用计算单元和专用AI加速单元进行了融合,算力水平达到了仅次于昇腾910的水平,支持训练、推理和虚拟化等多模式任务,能够灵活适配AI算法的快速迭代需求。昆仑芯P800特别适用于需要大吞吐量的AI应用,单卡即可支撑高并发、高计算量的实时计算需求。
凭借昆仑芯P800强大的算力,对于DeepSeek R1/V3满血版的本地化部署,只需要8张基于昆仑芯P800的加速卡,即一台8卡的服务器就能够完成,部署起来非常的便捷。相比之下,基于昇腾、沐曦、海光等AI芯片的方案,则可能需要32张加速卡(8卡服务器需要4台)才能实现DeepSeek R1满血版的本地化部署,相比单台服务器的解决方案,不仅部署成本可能更高(需要的AI芯片数量更多、服务器数量及配套设施也要更多,成本显然会更高)、组网复杂、能耗更高、空间占用也更大。

此外,昆仑芯P800在功耗控制方面表现突出,在120W功耗下即可实现128 TFLOPS的FP16算力,能效比优于许多国际主流芯片。该芯片在工业质检等应用场景中能够显著降低成本,与非国产方案相比,其总体TCO(总拥有成本)能够节省超过65%。
在实际部署过程中,昆仑芯还能够通过与百度飞桨(PaddlePaddle)深度适配,提供端到端的模型压缩和编译优化工具,减少显存占用,进一步降低了部署成本。
在实际使用中,一台基于昆仑芯P800的8卡服务器,在部署DeepSeek R1/V3满血版后,可以支持高达500人并发使用时,仍能保持50毫秒的低延迟响应,这使得它特别适用于对实时性要求极高的场景。
在生态方面,昆仑芯P800与主流深度学习框架(如TensorFlow、PyTorch、PaddlePaddle)全面兼容,开发者无需大幅修改代码即可迁移模型。昆仑芯还支持硬件级虚拟化技术,单卡可以划分为多个虚拟实例,在处理不同优先级的工作负载时,能够显著提高资源利用率。在DeepSeek的多租户场景中,这一特性尤为重要,能够优化资源分配,降低运维成本。
DeepSeek一体机市场爆发
面对企业级用户对于本地化部署满血版DeepSeek大模型的需求,不少硬件厂商也纷纷推出了各种AI一体机解决方案。其中,相比基于英伟达GPU方案的DeepSeek一体机来说,性价比更高的基于国产AI芯片方案的DeepSeek一体机似乎更受市场欢迎。
传统AI部署需要企业自行搭建GPU集群、调试分布式框架等一系列的工作,不仅部署周期长、还需要有专业的团队来进行搭建和维护。相比之下,AI一体机通过标准化配置,提供了快速、便捷的本地化部署方案,无需专业运维团队,就可以做到开箱即用,并且拥有更高的稳定性、更低的时延和更好的数据隐私保护。
目前面向DeepSeek大模型的AI一体机主要分为推理一体机和训推一体机两大类。推理一体机主要面向需要高效推理计算的企业,内置DeepSeek-R1 32B、70B、满血版671B等不同尺寸的模型,价格从几十万到数百万不等,适用于对数据安全性要求较高的企业。训推一体机则适用于需要进行模型训练和推理的场景,其价格更高,主要用于预训练和微调大模型,能够支持更复杂的训练/推理任务。
近期,多个终端厂商都已针对DeepSeek大模型推出了一系列一体机产品,其中涉及的技术平台涵盖了国产化算力芯片如昇腾、海光、沐曦、昆仑芯等。这些产品的核心特点在于支持DeepSeek大模型的快速部署,同时满足不同应用场景下的高效能需求。

比如,华为推出的昇腾DeepSeek一体机,采用了昇腾高性能算力底座,深度融合了DeepSeek全系列大模型能力,能够满足语言理解、图像分析、知识推理等全场景应用需求。中国电信(天翼云)也有推出基于昇腾芯片的“息壤智算一体机”。
百度智能云也推出了基于各种国产AI芯片方案的DeepSeek一体机,其中就包括搭载自研昆仑芯P800的“百舸DeepSeek一体机”,相比其他AI一体机方案具备更为显著的部署优势和成本优势。据介绍,百度的“百舸DeepSeek一体机”支持高性能的训练与推理需求,单机即可完成满血版DeepSeek的部署,并且支持高吞吐,能够满足500人团队并发使用,响应速度极快,且运维成本低。
国产高端服务器行业应用定制服务商立尔讯近日也宣布推出DeepSeek一体机解决方案,目前已有支持英伟达GPU芯片的版本,同时正在与百度合作,即将推出基于昆仑芯P800的DeepSeek一体机解决方案。
此外,浪潮信息、联想集团、中国移动、拓维信息、开普云、中科曙光、超讯通信、天融信、科大讯飞等厂商也都有推出“DeepSeek一体机”。
值得一提的是,今年2月,超讯通信就宣布拿下了合计14.88亿元的基于沐曦C500方案的训推一体服务器大单。足见目前市场对于AI一体机需求的火爆程度。
百舸DeepSeek一体机的4大优势
在众多已经发布的DeepSeek一体机中,百度百舸DeepSeek一体机凭借其出色的综合表现,尤其是在数据安全、隐私保护以及低成本部署方面的突出优势,成为许多企业的首选。

1. 部署与运维:开箱即用与低运维成本
传统的AI大模型部署方式往往需要企业投入大量的时间和人力去配置硬件、安装软件、调试系统。尤其是在私有化部署场景中,部署周期通常较长,且一旦发生故障,运维团队的响应速度和调整周期较慢。因此,企业需要耗费更多的技术资源来确保系统的正常运行。
对于一些中小型企业或技术力量薄弱的组织来说,运维难度成为实施AI解决方案的一个门槛。百舸DeepSeek一体机通过智能运维系统,能够自动监控和调节系统负载,并提供实时反馈。其智能运维系统帮助企业在运营过程中减少人力投入,将运维成本降低了80%,使得企业能够将资源更多地投入到核心业务中,而不是运维管理上。其“开箱即用”的特点使得企业能够在不到0.5天的时间内完成部署,大大缩短了从购买到投入使用的时间。这意味着,企业无需进行繁琐的配置与调试,从而避免了传统部署方式中可能出现的冗长等待和复杂操作。
2. 数据安全:本地化部署与隐私保护优势
随着越来越多的企业开始处理敏感数据,如何确保数据在存储、传输和计算过程中的安全性成为了重中之重。特别是在合规要求日益严格的背景下,数据泄露和跨境数据传输的风险引发了广泛关注。目前某些一体机虽然支持本地化部署,但在跨区域的数据传输和存储管理上依然面临合规风险。百舸DeepSeek一体机采用全本地化部署方式,所有的数据和计算均在企业内部完成,避免了通过外部云平台传输敏感数据的风险。尤其对于一些对数据隐私有严格要求的行业(如金融、医疗等),百舸一体机提供的数据隔离和本地化处理特性确保了数据的绝对安全性和隐私保护。
3. 计算性能与响应能力:低延迟与高吞吐量
AI大模型的计算性能直接影响到应用效果,尤其是在实时推理等场景中,系统的计算能力和响应速度至关重要。例如,在金融风控、智能客服等场景中,系统需要在极短的时间内对大量数据进行处理并给出反馈。因此,系统的低延迟响应和高吞吐量至关重要。百舸DeepSeek一体机搭载的昆仑芯P800芯片在推理性能方面表现尤为出色。
4. 性价比与市场竞争力
在AI一体机领域,性价比一直是企业在选择产品时考虑的重要因素之一。百舸DeepSeek一体机通过软硬件的高度协同,结合国产AI芯片的优势,能够以较低的成本提供强大的计算性能,尤其是在推理任务中表现尤为突出。在AI大模型应用的背景下,企业能够通过购买设备实现一次性投资,从而避免了云计算服务中不断上涨的使用成本。
百舸DeepSeek一体机可满足高性能训练与推理需求,单机高吞吐,数据处理速度快,可支持500人团队并发使用,推理延迟低,响应速度快,平均50毫秒以内,运维成本低,最高可降低80%,省钱又省心;从开箱到上电到服务上线最快仅需0.5天,省时省力。
小结:
总体来看,随着国产DeepSeek大模型的突破,极大地推动了大模型应用的不断扩展,企业对于在业务流程中部署AI以提升“生产力”的需求也变得更加迫切。而兼顾算力、数据安全、部署成本与效率的AI一体机的出现,无疑将加速这一进程。特别是随着国产替代的推进和行业应用场景的拓展,百度智能云推出的百舸DeepSeek一体机将在推动AI普惠化进程中继续发挥重要作用,有望成为企业智能化转型的最优解之一。
编辑:芯智讯-浪客剑
